一种提高云存储中小文件存储效率的方案
2019-02-26 来源:多智时代

实验结果表明,在不影响存储系统运行状况的基础上,该方案提高了HDFS(Hadoop distributed file system)是一种具有高度容错性质的分布式文件系统模型,可以部署在支持JAVA运行环境的普通机器或虚拟机上,能够提供高吞吐量的数据访问,非常适合部署云存储平台。
HDFS采用主从式架构设计模式(master/slavearchitecture),一个名称节点(NameNode)和若干数据节点(DataNode)构成HDFS集群。HDFS的这种单名称节点的设计极大地简化了文件系统的结构,然而也因此引发了HDFS的小文件存储效率低的问题。因为HDFS中的每个目录和文件的元数据信息都存放在名称节点的内存中,如果系统中存在大量的小文件(指那些比HDFS数据块(默认为64MB)d,得多的文件),则无疑会降低整个存储系统的存储效率和存储能力。
在各种存储系统中,存在大量这样的小文件。美国西北太平洋国家实验室2007年的一份研究报告表明,他们系统中有1 200万个文件,其中94%的文件小于64 MB,58%的小于64 kB。在一些具体的科研计算环境中,也存在大量的小文件,例如,在某些生物学计算中可能会产生3 000万个文件,而其平均大小只有190 kB。
解决基于HDFS的存储系统中小文件存储效率问题的主流思想是将小文件合并或组合为大文件,目前主要的方法分为2种,一种是利用Hadoop归档(Hadoop archive,HAR)等技术实现小文件合并的方法,另一种则是针对具体的应用而提出的文件组合方法。
Mackey等利用HAR技术实现小文件的合并,从而提高了HDFS中元数据的存储效率。Liu等结合WebGIS应用,以Hadoop为存储平台开发了HDWebGIS原型系统;结合WebGIS访问模式的特点,将小文件组合为大文件并为其建立全局索引,从而提高了小文件存储效率。Dong等[4]针对BlueSky系统中PPT课件的存储问题,提出了将小文件合并到大文件中并结合预取机制来提高系统存储和访问小文件的效率的方法。刘立坤等对分布式存储系统中小文件的并发访问进行了优化。
以上的研究工作都是基于文件的合并或组合来解决小文件存储效率不高的问题,然而还存在以下2个问题:第一,作为一个完整的系统,在提高小文件存储效率的同时,也应该考虑到系统的负载状况,因为不管是文件合并还是文件组合,对HDFS而言都是一个额外的操作;第二,未对小文件合并规模进行研究,即尚未确定多少个小文件合并为一个大文件可以使系统性能达到最优。
基于以上两点,本文提出了一个面向HDFS的云存储系统中小文件存储效率的优化方案:采用序列文件技术将小文件合并为大文件,结合多属性决策理论和实验得出合并文件的最优方式,通过基于层次分析法(analytic hierarchy process,AHP)的系统负载预测算法实现系统的负载均衡。
1 小文件存储效率优化方案设计
在构建的云存储系统中,采用多叉树的结构来构建文件索引。用户将文件上传到云存储系统后,系统会自动根据用户文件的组织形式建立对应的多叉树索引。
1.1序列文件合并技术
序列文件(SequenceFile)是HDFS提供的一种二进制文件技术,这种二进制文件直接将对序列化到文件,文件序列化时可实现基于记录或数据块的压缩。在云存储系统中,对二进制文件采用SequenceFile技术将小文件合并为大文件,以小文件的索引号为key、内容为value的形式进行合并,合并的同时实现基于数据块的压缩,这样,在节省名称节点内存空间的同时也节省了数据节点的磁盘空间。
1.2小文件存储效率优化方案
在基于HDFS的云存储系统中,小文件存储效率优化方案如图1所示。为提高对小文件的处理效率,系统为每个用户建立了3种队列:第1种为序列文件队列(SequenceFile queue,SFQ),第2种为序列文件操作队列(SequenceFile operation queue,SFOQ),第3种为备用队列(Backup queue,BQ)。其中,SFQ用于小文件的合并,SFOQ用于对合并后小文件的操作,BQ用于操作的小文件数超过SFQ或SFOQ长度的情况。3种队列的长度一致,可通过实验得出队列长度的最优值。下面介绍具体的处理流程。
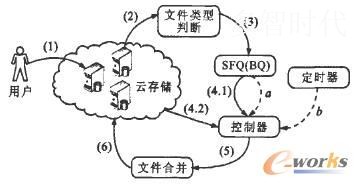
图1 小文件存储效率优化方案
如图1所示,用户将本地的文件上传至云存储服务器(过程1),然后服务器开始对该文件的类型进行判断(过程2),如果是小文件,将该文件的索引号放入SFQ中(过程3)。当SFQ满时,将发送“队列满”信号(QF)给控制器,如图中虚线口所示,而当定时器到定时点时,将发送“时间到”信号(TU)给控制器,如虚线b所示。接收到QF或者TU信号后,控制器开始读取SFQ的相关信息(过程4.1),对系统负载进行计算(过程4.2)(具体算法在第2节中介绍),并据此决定是否进行小文件的合并(过程5)。文件合并后完成小文件与大文件之间的映射(过程6)控制器的具体处理逻辑如图2所示。
当控制器接收到信号时,首先判断信号类型,如果是QF,则调用基于AHP的系统负载预测算法计算系统负载。如果得到的系统负载低于系统设定的阈值,则开始合并文件(包括SFQ和BQ),并取消系统中的TU信号;如果系统负载大于系统设定的阈值,则进一步判断BQ的数量,若BQ数量小于某个值(例如3),则新建BQ,将SFQ转移到BQ中并推迟合并操作(系统中设定推迟的时间为30 min),设定TU信号,若BQ数量大于3,则将BQ中的小文件进行合并,取消系统中的TU信号。
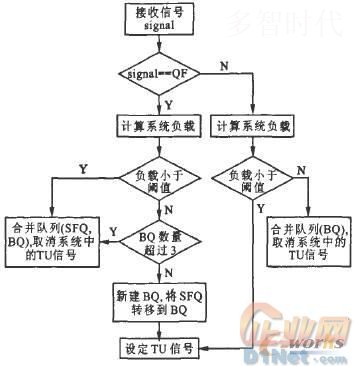
图2 控制器控制逻辑
如果接收到的是TU信号,计算系统负载并判断是否大于系统设定的阈值。若负载大于阈值,则推迟合并操作并设定TU信号;若负载小于阈值,则合并BQ中的小文件,取消系统中的其他TU信号。
2 基于AHP的系统负载预测算法
系统负载预测通常定义为基于CPU利用率、内存利用率、带宽利用率和系统平均吞吐量等系统属性对系统运行状态进行的多属性决策。
层次分析法(AHP)E7]是美国运筹学家托马斯萨迪提出的一种层次权重决策分析方法,是对定性问题进行定量分析的一种简便、灵活而又实用的多准则决策方法。
负载计算得到的是一个即时值或历史值,即只能够得到当前或以前时刻的系统负载,然而对小文件的操作是在系统负载计算之后,因此需要根据系统负载的历史信息来推测下一时刻的系统负载。基于此,本文设计了基于AHP的系统负载预测算法。该算法通过获取系统属性的历史信息,经过2次AHP分析,最终可得到系统负载的预测值。
算法依据系统属性的重要性,将每个时刻的系统负载属性值经过AHP分析融合为单一的决策属性值,然后依据决策属性值的时间重要性,经过第二次AHP分析最终得到下一时刻的系统负载值。具体步骤如下。

通过本文提出的这一算法,可以实现对系统负载的预测,从而将对小文件的操作控制在某个能够均衡系统负载的时刻进行
3 实验
为提高小文件的操作效率,系统为每个用户建立了SFQ和SFOQ。在这一节中,将通过实验研究SFQ长度对云存储系统的影响,选取读取文件时间、合并文件时间和节省的内存空间作为参考指标,以得到小文件合并的最优方式。
在基于HDFS的云存储系统中,对文件的操作主要有上传、下载、读取等。合并操作对上传没有影响,下载的核心操作也是读取,因此选取读取文件时间作为参考指标。提高名称节点内存利用率是本文的主要工作,因此将通过合并文件节省的内存空间作为参考指标之一。合并文件的效率是影响存储系统性能的一个重要因素,故也将合并文件时间作为参考指标。
3.1实验方案与实验结果
我们将通过3个实验分别获取在SequenceFile中读取小文件的平均时间、合并文件的平均时间以及合并所能节省的内存空间等指标值,并通过AHP分析数据,得出SFQ长度与系统性能的关系。6台Dell服务器构成云存储环境,服务器的配置均为CPU 8 Intel Xeon 2。13 GHz,内存8 GB,硬盘500 GB,操作系统均为Ubuntu Server 9。04,Hadoop版本为0.20.0.
实验1统计合并文件的平均时间(t1)。按照SFQ长度分别为100、200、300、400、500、600、700、800、900、1 000合并小文件50次,并且在不同的时段重复这样的实验10次。统计这10种情况下合并文件所需时间的平均值,最终得到合并文件的时间,结果如图3所示。
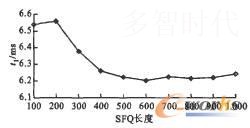
图3 合并文件的平均时间
实验2统计读取小文件的平均时间(t2)。小文件合并为SequenceFile之后,读取小文件的时间主要分为在SequenceFile中查找小文件的时间和获取小文件内容的时间2部分,因此,小文件合并之后读取文件的时间与该文件在SequenceFile中所处的位置有关。HDFS提供的API中采用顺序查找算法进行文件查找,因此读取的文件在SequenceFile中位置越靠后所需的时间越长。在实验l中得到的10个大文件中以10为步长读取小文件,获取其平均时间作为读取该大文件中小文件的平均时间,实验结果如图4所示。
实验3统计合并10 000个小文件节省的内存空间。将10 000个小文件上传到云存储系统,统计其占用名称节点的内存空间,然后分别按照SFQ长度为100、200、300、400、500、600、700、800、900、1 000进行合并,获取合并后占用名称节点的内存空间,两者之差即为合并操作所节省的内存空间,实验结果如图5所示。

图4 读取小文件的平均时间
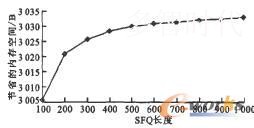
图5 节省的内存空间
3.2实验结果分析
3.2.1数据标准化将实验指标转化为逆指标(越小越好的指标),分别利用Min-Max方法和Z-Score方法对转化为逆指标的实验数据进行标准化睁9I,结果如图6、图7所示。
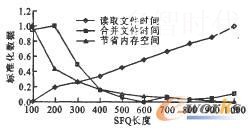
图6 Min-Max法的标准化数据
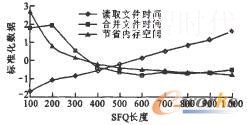
图7 Z-Score法的标准化数据
3.2.2系统性能决策值计算利用AHP进行权重计算。由于读取文件是最频繁的操作,因此认定读取文件时间为3个指标中最重要的,节省的内存空间其次。据此,计算3个指标的权重如表2所示。
表2权重
将标准化的数据与相应的权重相乘之后相加,得到系统性能决策值,如图8所示。
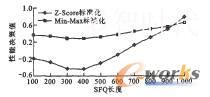
图8分析结果
3.2.3结果分析从图8可以看到,两种数据标准化方法都反映出一个规律,即在本文的实验环境中,性能决策值随着SFQ长度的增大呈现一种类似开口向上的抛物线状变化,并且在SFQ长度为400时取得最小值。由于我们采用了逆指标进行计算,因此当性能决策值最小时,表示系统性能达到了最优。由此可以得出结论:在本文的云存储环境中,SFQ长度取400是小文件合并的最优方式;根据基于AHP的系统负载预测算法对系统运行状况监控的结果,可以得到小文件合并的最佳时间。
通过实验可知,小文件合并的规模越大,名称节点消耗的内存空间将越少,与此同时,对小文件的操作(读取、删除等)以及合并文件所花费的时间代价也将越大。在其他基于HDFS的存储系统中采用本文的方案进行分析和部署,都可在时间消耗和内存利用率之间实现一种最优平衡,实现在小文件存储效率提高的同时不影响系统性能的目标。
4 结语
本文针对基于HDFS的云存储系统中小文件存储效率不高的问题,提出了一套完整的解决方案。在该方案中,采用SequenceFile技术将小文件以队列的形式合并为大文件,从而实现了节省名称节点所占内存空间的目的,同时也实现了对合并之后的小文件的透明操作。在确定影响队列长度的指标之后,通过实验获取指标值,采用数据标准化方法和三标度层次分析法确定队列长度的最优值,使得小文件的合并能在合并时间、文件操作时间和节省内存空间之间达到一种平衡。基于负载均衡的目的,本文设计了基于AHP的负载预测算法对系统负载进行预测。
在以后的工作中,我们将从以下两个方面来进行改进:①将小文件的合并以及小文件的读取改进为Map-Reduce任务,从而提高操作的效率;②对SequenceFile中的小文件查找算法进行改进,提高小文件查找效率。
在不久的将来,云计算一定会彻底走入我们的生活,有兴趣入行未来前沿产业的朋友,可以收藏云计算,及时获取人工智能、大数据、云计算和物联网的前沿资讯和基础知识,让我们一起携手,引领人工智能的未来!
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

上一篇:云计算环境下安全服务的思考与探索
下一篇:云计算所需的独特安全保护措施
