六个大数据应用实战案例
2019-02-26 来源:多智时代

案例主要关注三个问题:数据从哪里来?数据如何存储?数据如何计算?
1. Last.fm
1.1 背景
创建于2002年,提供网络电台和网络音乐服务的社交网络。每个月有2500万人使用Last.fm,产生大量数据。现在有了中文版http://cn.last.fm/,界面很不错!
2006年初,Last.fm开始使用Hadoop,几个月后投入实际应用。Hadoop是Last.fm基础平台的关键组件,有2个Hadoop集群,50台计算机,300个内核,100TB的硬盘空间。在集群上,运行数百种各种日常作业,包括日志文件分析,A/B测试评测,即时处理和图表生成。
1.2 图表生成
图表生成是Hadoop在Last.fm的第一个应用。
1.3 数据从哪里来
Last.fm有两种收听信息:用户播放自己的音乐,如pc或者其他设备mp3,这种信息通过Last.fm的客户端或者第三方应用发送到Last.fm,这一类叫scrobble收藏数据;用户收听Last.fm网络电台的节目,以及听节目时候的喜爱,跳过,禁止等操作信息,这一类叫radio listen电台收听数据。
1.4 数据存储
收听数据被发送到Last.fm,经历验证和转换,形成一系列有空格分隔的文本文件,包含用户id-userid,音乐id-trackid,这首音乐被收藏的次数scrobble,这首音乐在电台中收听的次数radio,被跳过的次数skip。真实数据达到GB级别,有更多属性字段。
1.5 数据处理
1.5.1 Unique Listeners作业:统计收听某一首歌的不同用户数,也就说说,有多少个用户听过某个歌,如果用户重复收听,只算一次。
1.5.2 Sum作业:每首歌的收听总数,收藏总数,电台收听总数,被跳过的总数。
1.5.3 合作作业:每首歌的被多少不同用户收听总数,收听总数,收藏总数,电台收听总数,被跳过的总数。
1.5.4 这些数据会被作为周排行榜等在Last.fm主站上显示出来。
2. Facebook
2.1 背景
Facebook社交网络。
开始时,试用一个小Hadoop集群,很成功。同时开始开发Hive,Hive让工程师能用SQL语言处理Hadoop集群的数据,毕竟很多人更熟悉SQL。后来,Facbook运行了世界第二大Hadoop集群,数据超多2PB,每天加入10TB数据,2400个内核,9TB内存,大部分时间硬件满负荷运行。
2.2 使用情况
2.2.1 在大规模数据是以天和小时为单位产生概要信息。如用户数,网页浏览次数,网站访问时间增常情况,广告活动效果数据,计算用户喜欢人和应用程序。
2.2.2 分析历史数据,以设计和改进产品,以及管理。
2.2.3 文件存档和日志查询。
2.3 广告分析
2.3.1 cpc-cost perclick点击数计费,cpm-cost per mille每千人成本。
2.3.2 个性化广告定制:根据个体用户进行不同的内容剪辑。Yahoo!的SmartAds,Facebook的Social Ads,Engagement Ad广告意见/嵌入视频交互。Facebook每天处理1TB数量级广告数据。
2.3.3 用Hive分析A/B测试的结果。
2.3.4 Hadoop和Hive分析人气网站,生物信息公司,原油勘探公司,在线广告。
3.Nutch搜索引擎
3.1 Nutch框架用户建立可扩展的crawler网络爬虫和搜索引擎。
3.2 架构
3.2.1 crawlDb网页数据库:跟踪网络crawler抓取的网页和它们的状态。
3.2.2 fetchlist爬取网页清单:crawler定期刷新web视图信息,下载新的网页。
3.2.3 page content原始网页数据:从远程网站下载,以原始的未世界的格式在本地存储成字节数组。
3.2.4 解析的网页数据:Nutch为html, pdf, open office, ms office, rss提供了解析器。
3.2.5 linkdb链接图数据库:page rank来的。
3.2.6 lucene全文检索索引:倒排索引,基于搜集到的所有网页元数据和抽取到的纯文本内容建立。
3.3 使用情况
Nutch使用Hadoop作业处理数据。
4 Rackspace
4.1 背景
Rackspace hosting为企业提供管理系统。在数百台服务器上为100万用户和几千家公司提供邮件服务。
4.2 使用情况
日志分析。发送邮件需要使用多个postfix邮件代理服务器,大部分消息穿越多个Postfix服务器,但每个服务器只知道邮件的目的地,为了给消息建立完整的历史信息,需要用Hadoop处理日志记录。
4.3 使用方式
在数据中心, syslog-ng从source机器传统日志数据到一组负载均衡的collector收集器机器。在收集器上,日志数据被汇集成一个单独的数据流,用gzip格式进行轻量级压缩。
当压缩的日志流到达本地收集器,数据会被写入Hadoop,这一步用简单的python脚本写入即可。
Hadoop集群有15个数据节点,每个节点使用普通cpu和3个500G硬盘。
4.4 计算
每个电子邮件有一个唯一标示符号queue-id。每个电子邮件有一个唯一的message-id,但恶意客户端会重复发送消息,所以message-id会被伪造。
在Postfix日志,需要用queue-id查找message-id。
第一步,以queue-id为健,进行map,把日志log的每个分配给对应的queue-id,然后,执行reduce过程,根据日志消息数值判断queue-id的发送过程是否完整。
第二步,根据message-id对第一步的结果进行分组,以queue-di和message-id同时为键,以它们对应的日志行作为值,在reuce阶段,判断针对某个message-id的所有queue-id是否合理,验证消息是否离开系统。
5. Cascading
5.1 背景
Cascading是一个开源的Java库,为MapReduce提供抽象层。用Java写Hadoop的MapReduce是有难度的:cascading用简单字段名和数据元组模型代替MapReduce的key-value;cascading引入了比Map和Reduce更抽象的层次,如Function, Fileter, Aggregator和Buffer。
5.2 使用情况
Cascading以字段名和元组的方式,把多个MapReduce的处理简化成一个管道链接起来的形式处理数据。从例子来看非常简洁,需要的代码很少。
6. 用Pig和Wukong探索十亿数据级别的网络图
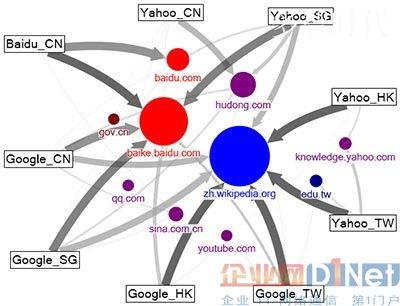
6.1 图=节点+连接节点的边。
6.2 Infochimps项目,一个发现,共享,出售数据集的全球性网站。用简单的脚本语言-不超过一页,就可以处理TB级别的图数据。
6.3 在Infochimps,有twitter,faceboobk的数据集;有wiki百科数据集;线虫项目神经愿和突触的联系;高速公路地图等等。
6.4 在网络图分析上可以做出很多很好玩的有趣东东。
在不久的将来,云计算一定会彻底走入我们的生活,有兴趣入行未来前沿产业的朋友,可以收藏云计算,及时获取人工智能、大数据、云计算和物联网的前沿资讯和基础知识,让我们一起携手,引领人工智能的未来!
标签: 大数据 大数据应用 代理服务器 代码 电子邮件 服务器 脚本 评测 数据库 搜索 搜索引擎 网络 云计算
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

下一篇:云计算与呼叫中心的未来解析
