Hypertable(C++)吞吐率测试完胜HBase(Java)
2019-02-26 来源:多智时代

近日,Hypertable和HBase进行了类似随机读取统一的测试, 结果表明Hypertable在吞吐量测试中以2倍的性能优势压倒HBase。HBase在410亿和1670亿的数据插入测试中不堪重负(垃圾数据收集)。在此次测试中Hypertable选用了0.9.5.5版,而HBase版本为0.90.4(CDH3u2运行于Zookeeper)。
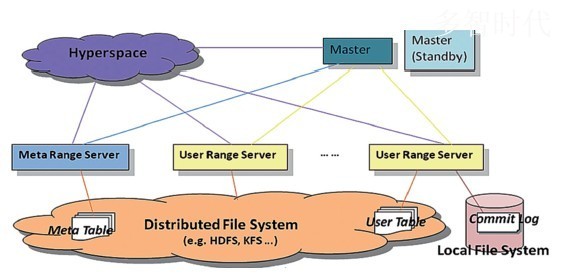
Hypertable高可用改进架构示意图
| Hypertable系统主要包括Hyperspace、Master和Range Server三大组件。Hyperspace是一个锁服务,地位相当于Google的Chubby,主要用于同步、检测节点是否发生故障和存放顶层位置信息;Master主要用于完成任务分配,未来会有负载均衡以及灾后重建(Range Server失效后自动恢复服务)等其他作用;Range Server是Hypertable的实际工作者,主要负责对一个Range中的数据提供服务,此外它还肩负起灾后重建的责任,即重放本地日志恢复自身故障前状态;另外,还有访问Hypertable的客户端Client等组件。 |
Hypertable和HBase都是开源的可扩展的数据库产品,它们的设计蓝本同时基于Google BigTable。两者的主要区别是Hypertable依靠C++语言实现,而HBase则基于Java编写。 本次测试的环境为16台服务器,这16台服务器通过千兆网络连接在一起。
操作系统:CentOS 6.1
CPU:2X AMD C32 Six Core Model 4170 HE 2.1Ghz
内存:24GB 1333MHz DDR3
硬盘:4X 2TB SATA Western Digital RE4-GP WD2002FYPS
Hypertable和HBase在HDFS的NameNode运行在1号测试机之上。而DataNodes则运行在4号测试机到15测试机之上。与此同时RangeServer和RegionServers运行在同一组计算机之中,并且配置使之可用所有的内存资源。三个Zookeeper和Hyperspace副本运行在1号测试机在3号测试机。在测试中,表被配置使用Snappy压缩,同时使用Bloom filters加载Row Key。
在随机写入测试中,Hypertable和HBase分别测试写入4个不同的5TB数据。 使用的值大小分别为10000、1000、100和10。同时固定为20字节并将范围内的随机整数(随机值的数据段取自英文Wiki百科XML页面的200MB样本)格式化为零填充(0..number_of_keys_submitted*10)。
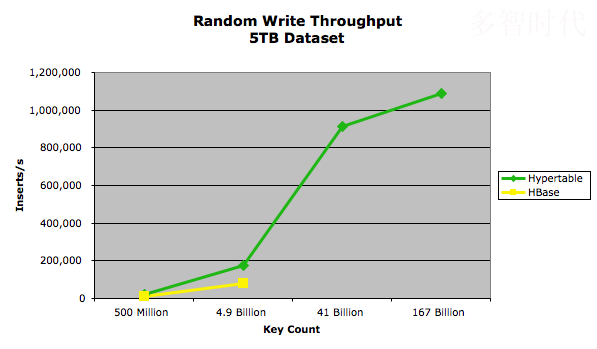

从图中我们可以看出HBase在410亿以及1670亿的键测试中由于HBase的RegionServers并发模式失败而抛出异常。无论如何配置当RegionServer产生无用数据的速度超过Java垃圾收集器就会发生如上的故障。为了解决这一问题,建造新的垃圾回收计划以克服问题,但这也会为运行时的性能带来沉重的代价。
在2005年的OOPSLA会议上Matthew Hertz和Emery D. Berger公布了《Garbage Collection vs. Explicit Memory Management》的研究文档,这为相关研究提供坚实的信念。
在不久的将来,云计算一定会彻底走入我们的生活,有兴趣入行未来前沿产业的朋友,可以收藏云计算,及时获取人工智能、大数据、云计算和物联网的前沿资讯和基础知识,让我们一起携手,引领人工智能的未来!
标签: CentOS Google 大数据 服务器 数据库 网络 云计算
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

上一篇:混合云计算面临哪些安全问题
