GPU云服务器深度学习性能模型初探
2019-10-25 来源:多智时代

摘要:本文根据实测数据,初步探讨了在弹性GPU云服务器上深度学习的性能模型,可帮助科学选择GPU实例的规格。
NVCaffe是NVIDIA基于BVLC-Caffe针对NVIDIA GPU尤其是多GPU加速的开源深度学习框架。LMDB格式的ImageNet训练集大小为240GB ,验证集大小为9.4GB。
我们使用NVcaffe对AlexNet、GoogLeNet、ResNet50、Vgg16四种经典卷积神经网络做了图像分类任务的模型训练测试。分别对比了不同vCPU和Memory配置下的训练性能。性能数据单位是Images/Second(每秒处理的图像张数)。图中标注为10000指的是迭代次数10000次,其它都是测试迭代次数为1000次。
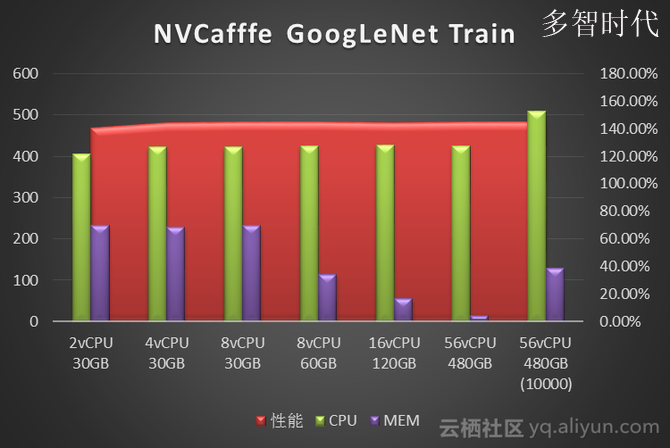
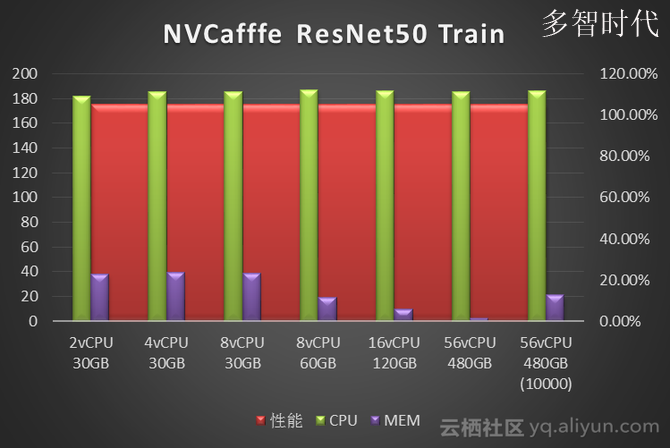
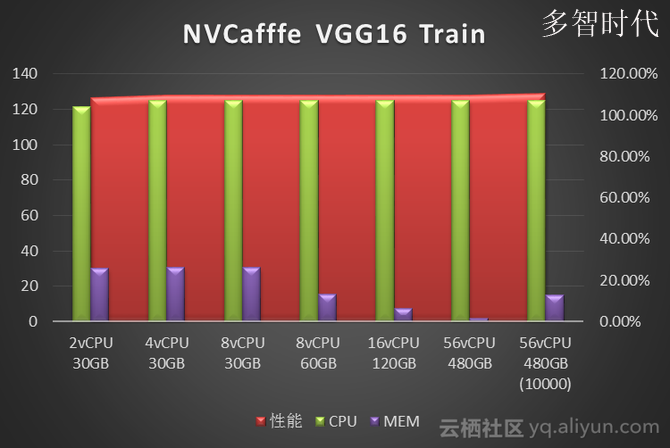
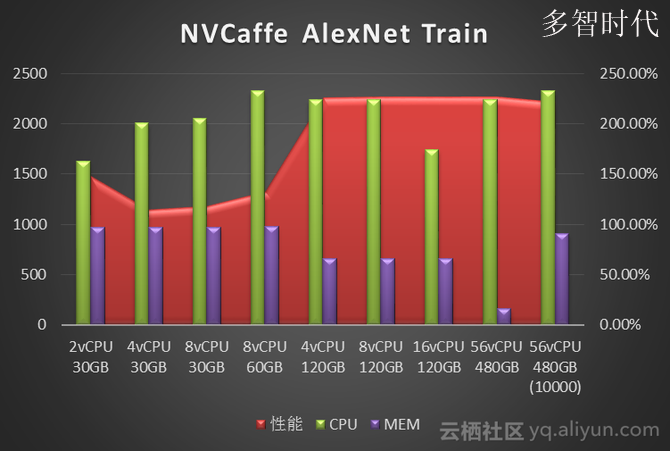
从NVCaffe和MXNet的测试结果来看,图像分类场景单纯的训练阶段对CPU要求不高,单GPU 只需要4vCPU就可以。而内存需求则取决于深度学习框架、神经网络类型和训练数据集的大小:测试中发现NVCaffe随着迭代次数的增多,内存是不断增大的,但是内存需求增大到一定程度,对性能就不会有什么提升了,其中NVCaffe AlexNet网络的训练,相比其它网络对于内存的消耗要大得多。相比之下MXNet的内存占用则要小的多(这也是MXNet的一大优势),93G预处理过的训练数据集训练过程中内存占用不到5G。
对于磁盘IO性能,测试显示训练阶段NVMe SSD本地盘、SSD云盘性能基本接近,高效云盘上的性能略差1%。因此训练阶段对IO性能的要求不高。
从NVCaffe的图像分类推理测试来看,除AlexNet 2vCPU刚刚够用外,其它网络2vCPU对性能没有影响,而9.4GB的验证数据集推理过程中内存占用大概是7GB左右,因此对大部分模型来看,2vCPU 30GB 1GPU规格基本满足图像分类推理的性能需求。
对于磁盘IO性能,推理性能NVMe SSD本地盘、SSD云盘很接近,但高效云盘差15%。因此推理阶段至少应该使用SSD云盘保证性能。
5.2.2 自然语言处理
对于自然语言处理,参考训练性能需求,我们应该可以推测2vCPU 30GB 1GPU规格应该也能满足需求。
5.3 数据预处理
从NVCaffe对ImageNet ILSVRC2012数据集做数据预处理的测试来看,数据预处理阶段是IO密集型,NVMe SSD本地盘比SSD云盘快25%,而SSD云盘比高效云盘快10%。
6 总结
深度学习框架众多,神经网络类型也是种类繁多,我们选取了主流的框架和神经网络类型,尝试对单机GPU云服务器的深度学习性能模型做了初步的分析,结论是:
(1)深度学习训练阶段是GPU运算密集型,对于CPU占用不大,而内存的需求取决于深度学习框架、神经网络类型和训练数据集的大小;对磁盘IO性能不敏感,云盘基本能够满足需求。
(2)深度学习推理阶段对于CPU的占用更小,但是对于磁盘IO性能相对较敏感,因为推理阶段对于延迟有一定的要求,更高的磁盘IO性能对于降低数据读取的延时进而降低整体延迟有很大的帮助。
(3)深度学习数据预处理阶段是IO密集型阶段,更高的磁盘IO性能能够大大缩短数据预处理的时间。
标签: 云服务器 深度学习 卷积神经 图像分类 神经网络 数据集
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

下一篇:网络直播系统教育的学习阶段
