基于ELK的大数据平台实践分享
2018-07-28 来源:raincent

数据分类
数据采集
数据采集主要分为网络类和日志类。网络类主要为旁路部署,用小盒子部署在机房内不同的点,包括出口入口。日志类主要包括Nagios (filebeat)和Zabbix (mysqlexporter)。
数据类型

上图为主要数据类型,网络协议里也有数据库,是一些协议解析,还有一些交易的解析。可以从网络层面和日志层面分开来比对。
数据量
每天数据量至少2TB,记录数22亿,不含副本;高峰数据量每秒6万条记录;单个索引最快处理12万条记录每秒。
使用场景
主要有三个使用场景:查询聚合;大屏分析,预测告警;网络指标,业务指标安全指标。
网络业务安全是基于一些不同的团队,定制个性化的指标,进行一些对比分析。
运维之路
集群演变
在使用ELK的整个过程中,我们使用过Vmware、Docker,跟美国的第三方公司的一些合作。我们自己用的最多的是单节点单实例和单节点双实例。基本是用于功能测试小公司一些测试部署。
冷热分离
我们做的冷热分离,开始采用的是flashcache模式,每台物理机上面都配备了一个SSD的小盘,主要是为了抵消传统的机械式硬盘寻到的一个LPS。LPS比较慢,延迟比较高,所以分布式集群每一块都配备一个小盘。在这种模式下,磁盘IO连续小块读,负载高,IOwait高,分析发现存在抖动。采用单机双实例冷热分离模式,充分利用1.6TB的SSD,只保存每天的热数据,隔夜迁移到HDD Raid0。
升级的主要目的有两个:内存隔离,当天和历史JAVA对象分离在不同的JVM里;IO隔离,当天和历史数据的磁盘IO分离在不同的磁盘上。

上图为运维前后对比效果图。左边是运维之前,右边是运维之后。升级后,有效减少了cpu wait和磁盘读,降低了系统负载,有效提升了查询和写入性能。
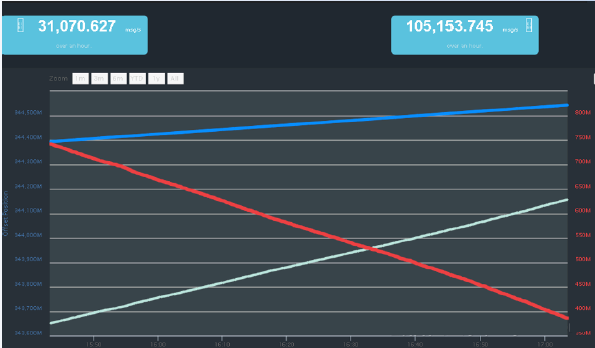
上图为在单个索引上做的测试。之前做了许多积压,可以发现索引的速度是上升的。单个索引最高速度从之前的60000条每秒提升到120000条记录每秒,平均10万条每秒。聚合查询性能提升1倍。
重要选型
重要选型首先从cpu介绍,我们推荐使用Xeon E5-2600 V4系列。官方测试显示,它比V3系列提升JAVA性能60%,我们进行了一些设置,包括指令预取,cache line预取,Numa Set。结合双路cpu,它的内存和节点有一个就近读取的原则。我们根据单个机器的实例进行cpu的绑定。设置以后可以提高cpu的命中率,减少内存的切换。
在内存方面,每台物理机配备的是128TB,SSD是1.6TB,HDD是40TB~48TB。具有大内存的特点,我们还进行了Cache加速,写负载高的时候上SSD,定期做Trim优化,利用SSD,SAS和SATA盘分级存储。
OS file system用的最多的是xfs。针对HDD、SSD 4k对齐优化,确保每个分区的start Address能被8整除,解决跨扇区访问,减少读写次数和延迟。
Shard和Replica个数是基于测试的经验,可以作为参考,还基于负载、性能等。节点数设置为1.5。Shard size 控制在30GB以内,Shard docs 控制在5百万记录以内,Replica至少为1。
可靠性

由上图可以看到每个角色都有A、B、C三个点,然后做了冷热分离,Client多个点做了负载均衡。
性能分析
高负载
高负载主要采用IO负载型,主要关注Sar,Vmstat,IOstat,Dstat和Systemtap,Perf。
线程池
线程池这里主要关注Index,Query,Merge,Bulk,包括Thread,Queue Size和Active,Queue。
内存占用
内存占用主要看各个节点的内存占用大小,Fielddata设置为10%,也有的设置为1%,大部分场景都是精确查询。
查询
用慢查询作为告警,然后进行请求、响应、延时、峰值统计。随着资源使用率的提升,我们会发现在80%的点位,延时会特别大,于是会有多个监工。单个监工是没问题的,但是多个监工可能是有问题的。Query profile用来定位各个阶段的时间。Cache filling用来观看命中率如何,可以做一些cache的设置。然后会进行日志埋点采集,query replay,做一些测试。
集群健康
集群健康这里主要是对以下几项进行指标监控。 _cluster/health:active, reallocating, initializing,unassigned;Ping timeout;Shard allocation,recover latency。
GC效率
GC效率主要关注以下几点:GC时长占比,GC回收量占比;内存增长速率,内存回收速率;各代回收耗时,频率;Dump profile;Jstack,Jmap,Jstat。
存储规划
上图为基于不同业务做的存储规划。
性能提升
合理设计
首先我们会考虑每个域的意义,没有意义的域是不允许插进来的。然后要考虑需要存储搜索还是聚合,思考每一个域的价值所在。它是字符串型的还是数值型的?然后我们会对模板进行动态的设置。当字符串过长的时候,我们是否要做一个截取?是否要做一个Hash?
批处理
适当调大处理时间,Translog适当把频率降低。
上图做了一个按需隔离,分表分级分组。
规划计算
提前聚合后插入;因为空间不够,所以超过生命周期后只保留基线,然后做压缩,做合并;随后可以做Pipeline拆分。
集群监控
监控这里用了一些工具。Netdata用来做一些系统资源的升级, _cat api是官方自带的,Cerebro是用的比较多的一个插件,Prometheus可以开箱即用。
告警分析
用Sql语法做一些包装、抽象,告警模型基于从工作日开始的迭代、同比环比、平均值及标准差,基线学习。
我们发现问题,解决问题,需要不停的去思考。不断迭代,严苛细节,最终性能是否满足?是否可接受?这些都是需要思考的问题。
标签: Mysql ssd 安全 大数据 大数据平台 机房 数据库 搜索 网络
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

