����R����������Ӫʵս
2018-08-06 ��Դ��raincent

һ������
�����������ŷֲ�ʽ���ݴ��������IJ��ϸ��£�Hive��Spark��Kylin��Impala��Presto �ȹ��߲����Ƴ³��£��Դ����ݼ��ϵļ���ʹ洢��Ϊ��ʵ�����ݲֿ�/��ҵ�������������Ϊ������ҵ�ͻ����ı��䡣�����ֱ����£��Ƿ���̽�����ھ����ݼ�ֵ���߱���ϸ��������Ӫ���������ͳ�Ϊ�ж�һ�������Ŷӳɹ����Ĺؼ���
�����ݴӺ�̨����ǰ̨�Ĺ����У�����չʾ�����һ���ؼ����ڡ������ı���չʾ��ȣ�������ת����ͼ���������ʵ���������֯�������ܸ����١���ֱ�۵Ĵ�����Ϣ���������õ��ṩ����֧�֡��ӽṹ�����ݵ����յ�չʾ����Ҫͨ��һϵ�е�̽���ͷ�������ȥ��ɲ�Ʒ˼·�ij������������Ҳ�����Ŵ��������ݶ��δ�����
������Щ���� R �������Ŷ��ص����ơ����Ľ��������ŵ�������������ľ�ϸ��������Ӫʵ�������� R �����ݷ�������ӻ�����Ĺ���������ϣ���ܹ���ש����Ҳ��ӭҵ��ͬ�и������ṩ����Ľ��顣
����������Ӫ��Ʒ������ R ������
2.1 ������Ӫ��Ʒ����
����ҵ������Ӫ�����У�����ʹ�ó�������Ʒ�ص㡢ʵʩ��ɫ�Լ������õĹ��ߣ����¿��Խ�������Ӫ�����Ϊ���࣬���±���ʾ��

��һ ������Ӫ�������
2.2 R ��������Ӫ�ϵ�����
���Ͻ��������ھ�ϸ��������Ӫ�����У�������Ҫʹ�ø߶ȶ��Ƶ����ݴ��������ӻ����������ֶΣ���Щ���� Excel��Tableau����ҵ���������߶�������㵽����ǡ���� R ��ǿ�һ����˵��R �߱���������������������“���ݷ����������ʿ����”�����ţ�
• ��ѡ���Դ������չ�������� 2018-08-02��“The CRAN package repository features 12858 available packages. ”��CRAN �ϵ��������漰��Ҷ˹�������˳�ѧ�����ڡ�����������Ŵ�ѧ�ȷ������棬���ڳ��������͵�����
• �ɱ�̣�R ������һ�Ž��������ԣ�����ͨ���������ִ�й��̣�����ͨ�� rPython��rJava ��������ʵ�ֺ� Python��Java ���ԵĻ�����á�
• ǿ������ݲٿ�������
• ����Դ���룺ͨ�� RMySQL��SparkR��elastic ��������������ʵ�ִ� MySQL��Spark��Elasticsearch ���ⲿ���������ȡ���ݡ�
• ���ݴ��������� vector��list��matrix��data.frame �����ݽṹ������ͨ�� sqldf��tidyr��dplyr��reshape2 ��������ʵ�ֶ����ݵĶ��μӹ���
• ���ݿ��ӻ���ggplot2��plotly��dygraph �ȿ��ӻ�������ʵ�ָ߶ȶ��ƻ���ͼ����Ⱦ��
• ���ݷ������ھ�R ������һ����ͳ��ѧ�ҷ��������ͳ�Ʒ��������ԣ�ͨ�����б��ʵ�ֻ��ߵ��������������ã���������ʵ�����Իع顢������������ɷַ����ȷ������ھ��ܡ�
• ���߳��εķ����ܣ�
• Web ��̿�ܣ����粻��ͨǰ�˺�ϵͳ������ͬѧ��ͨ�� shiny �����������Լ�������Ӧ�á�
• ��������������ͨ�� rserve ��������ʵ�� R ����������ͨ�ŵ� C/S �ܹ�����
����������Ϊ���ĵ�Ӧ����˵��Python �� R ���Dz�����ѡ�����������ڷ�չ������Ҳ���н����“Խ�ӽ�ͳ���о������ݷ�����Խ���� R;Խ�ӽ����̿������̻������ˣ�Խ���� Python”��Python ��һ��ȫ����“�˶�Ա”��R �������һ��ͳ�Ʒ��������“����”��“Python ��δ������һ������ CRAN �����ľ�Ĵ���⣬R ���ⷽ����о����������ơ�ͳ��ѧ������ Python �ĺ���ʹ��”����������վ���д���“Python VS R ”�����ۣ�����Ȥ�Ķ��߿��������˽������ѡ��
����R �����ݴ��������ӻ������ظ������ݷ�������
���ھ߱���������ķ���ʦ���߾߱����������Ŀ�����Ա��˵���ڽ���һϵ�г��ڵ����ݷ�������ʱ��ʹ�� R �ȿ�������“һ�ο�������������”���ֿ�������“������ͼ�ηḻ”��Ҫ�����Ľ��ֱ���� R �����ݴ������������ӻ������Ϳ��ظ������ݷ���������
3.1 ���ݴ���
����ҵ������ϵͳ�У�������ϴ����������Ϲ�����ͨ�����ݲֿ⡢Hive��Spark��Kylin �ȹ�����ɡ�����������Ӫ��Ŀ����Ȼ R �������ǽ�����ݼ�����Ҳ���ܱ�����Ҫ�ڲ�ѯ����ж������ݴ�����
�����ݲ�ѯ�㣬R ��̬�ֳɾʹ����ڶ�����֧�֣��������ͨ�� RMySQL ������ MySQL ����IJ�ѯ������ʹ�� Elastic ���� Elasticsearch �����ĵ��������������� Kylin ���¼������� R ��̬�����֧��û�и���ʱ������ͨ��ʹ�� Python��Java ��ϵͳ���Խ��в�ѯ�ӿڷ�װ���� R �ڲ�ʹ�� rPython��rJava ������е�������ѯ�ӿڵ��á�ͨ����ѯ�����ȡ������һ���� data.frame��list �����Ͷ�����ڡ�
���� R ����Ҳӵ�бȽ��걸�Ķ������ݴ����������������ͨ�� sqldf ʹ�� sql �� data.frame ����������ݴ���������ʹ�� reshape2 ���п���ʽ��խ��ʽ��ת��������ʹ�� stringr ��ɸ����ַ��������������������鴦����ȱʧֵ���ȹ��ܣ�Ҳ���߱����Ƶ����Ա�������̬��֧�֡�
3.2 ���ݿ��ӻ�
���ݿ��ӻ�������̽�����̺ͽ�����ֵĹؼ����ڣ��� “R is a free software environment for statistical computing and graphics. ”����ͼ(���ӻ�)ϵͳҲ�� R ���������֮һ��
Ŀǰ R ����֧�ֵ��������ӻ�ϵͳ��
• ����ϵͳ�������� base��grid �� lattice �������÷��а���֧������ԱȽ����صķ�ʽ���ͼ�λ��ơ�
• ggplot2���� RStudio ����ϯ��ѧ�� Hadley Wickham ������ggplot2 ͨ��һ��ͼ���֧�֣�֧��ͨ��ͼ���������ϵķ�ʽ֧�ָ߶ȶ��ƵĿ��ӻ�����һ����Ҳ��Ӱ���˰��� Plotly������ AntV �ȹ��������ݿ��ӻ���������������� 2018-08-02��CRAN �Ѿ������ 40 �� ggplot2 ��չ�����ο�������
• htmlwidgets for R����һϵͳ���� RStudio ֧������ 2016 �꿪ʼ��չ׳���ṩ���� JavaScript ���ӻ��� R �ӿڡ�htmlwidgets for R ��Ϊǰ�˿��ӻ�(for ǰ�˹���ʦ)�����ݷ������ӻ�(for ���ݹ���ʦ)������������������������֮���������ơ������� 2018-08-02�����������ķ�չ��Ŀǰ CRAN ���Ѿ��� 101 ������ htmlwidgets �����ĵ����������ο�������
ʵ��������Ӫ���������У����Թ̻������ͼ��չ�ֺͿ��ӻ��������̣�ʵ�ִ��븴�ã���߿���Ч�ʡ���ͼ�����ŵ�����������������Ŷӻ��۵IJ��ֿ��ӻ����ʾ����

ͼһ ���ӻ����ʾ��
���ڿ��ӻ�����⣬һ�����ӻ�����ֻ��Ҫһ�д��뼴����ɣ��ܼ�����������Ч�ʡ���ͼ�����������������ʾ��ͼ�Ĵ������£�

Ɲ�ٸ���������������ӻ�����ĺ���������

3.3 ���ظ������ݷ���
������Ӫ����������һ���ظ��Եġ����˹�����Ĺ��̣����ջ����һ�����ݷ�����ܣ��������ݷ�����������������ݣ�����֧����ҵ���ݾ��ߡ�
RStudio ͨ�� rmarkdown + knitr �ķ�ʽ�ṩ��һ������ѧ��̵����ݷ���������������������߿��Խ� R ����Ƕ�� Markdown �ĵ���ִ�в��õ���Ⱦ���(��Ⱦ��������� HTML��PDF��Word �ĵ���ʽ)��ʵ�����ݷ��������У��������������γ�һ�����ݷ���ģ�棬ÿ�����䲻ͬ�����ݣ����ܲ���һ���µ����ݷ������档
rmarkdown �����߱���ҳ�沼������������ʹ�� flexdashboard ������չ�����������������ʵ���ظ��Է������̣�����ʵ�ַ�������ĸ߶ȶ��ƻ�չʾ������ʹ�� HTML��CSS��JavaScript ǰ������������ݷ����������չʾ�ͽ�����ϸ�ڵ���������ʵ�������Ľ�ʡ�����ݷ�������Ŀ��١���Ч������
�ġ�R ������
4.1 R �����
R ��������һ�����ԡ�Ҳ��һ����ƽ̨�IJ����������߱�ǿ������ݴ��������ݷ����������ݿ��ӻ������������ڸ��˵��Ե� Windows/MacOS �������ϳ䵱����ͳ�Ʒ��������⣬Ҳ���������� Linux �����У���˿��Խ� R ��Ϊ����չ�����棬��Χͨ�� Java ��ϵͳ����������ɻ��桢��ȫ��顢Ȩ���Ƶȹ��ܣ�������ҵ����ϵͳ�����ݷ���(�ھ�)��ܣ���������ֻ�ǽ� R ��Ϊһ������������
��ҵ����ϵͳ�����ݷ���(�ھ�)�����Ʒ�������ͼ��ʾ��

4.2 foreach + doParallel ��˲��з���
��Ϊһ��ͳ��ѧ�ҿ����Ľ��������ԣ�R ���е��� CPU �����ϵĵ��̳߳�������Ҫ��ȫ�����ݼ��ص��ڴ���д�������˺� Java��Python ��ϵͳ������ȣ����������� R �����ߡ����ڴ����ݼ��ϵļ��㳡������Ҫ���������ݼ��㲿��ͨ�� Hive��Kylin �ȷֲ�ʽ����������ɣ������� R ֻ����������ݼ�;����Ҳ����ͨ�� doParallel + foreach ������ͨ����˲�����������Ч�ʣ�����ʾ�����£�

4.3 ͼ�λ����ݱ�����Ⱦ����
�����ݷ��������У�R ����Ҫ���dz䵱ͼ������Ľ�ɫ������б�Ҫ�˽���ͼ����Ⱦ���ܡ���������Ļ��� rmarkdown + flexdashboard �����ݷ���������Ⱦ�����������ܲ��Խ�����£�
ϵͳ������
• 4 �� CPU��8 G �ڴ棬2.20GHz ��Ƶ��
• Linux version 3.10.0-123.el7.x86_64��
���Է�����
�����ڲ�ͬ�������¡���ͬ���Ӷȵ���Ⱦģʽ�£��ظ���Ⱦ 100 �εĺ�ʱ��
���Խ����

���� ���ݷ���������Ⱦ���ܲ���
���ݲ��Խ����֪��
��Ӧ��ƽ����Ⱦʱ���� 0.74s ���ϣ��������Ⱦʱ���Ӽ��㸴�Ӷȶ���(����ͨ���Ͻڽ��ܵ�“foreach + doParallel ��˲��з��� ”�ӿ촦������)�����ݾ��飬��Ӧ�������뼶�����Ⱦ��
���ڵ��˵��߳�ģʽ���ޣ����������� CPU ����ʱ����Ⱦ��������������Ӧ��������Ҫ����ʵ��ҵ��ƥ���Ӧ�ķ���˻������ã���������ת��ʱ���ò���ִ�����ޡ������ڲ���Ӫ���ʵ�����ϵͳ����̨ 4 �� 8 G ��������������Ҫ��
�塢R ���������ݲ�Ʒ�е����ʵ��
���ŵ�����������ŶӴ� 2015 �꿪ʼ�� R ��Ϊ���ݲ�Ʒ�ĸ����������ԣ����� 2018 �� 8 �£��Ѿ��ɹ�Ӧ�����������������������ݱ��桢�������ݲֿ������ķ������ߡ������ڲ���Ӫ�����ʦ������ Dashboard�������ͻ����۵�Ʒ���̼����ݷ���ϵͳ�ȶ����Ŀ�С�Ŀǰ���е��������ڲ��Ķ���ʽ�����Ͳ�Ʒ������ѡʹ�� R ���п�����
��������Ҳ������ R ���ӻ������������������� R ��������û� BI ��Ʒ������ܣ����ڽ�һ������ R ��ʹ���ż������� R ���ռ���Χ��
��ͼ�����ŵ�����������Ŷ����������������У�ʹ�� R ������ ETL ��������ϵ���ӻ����ߣ�
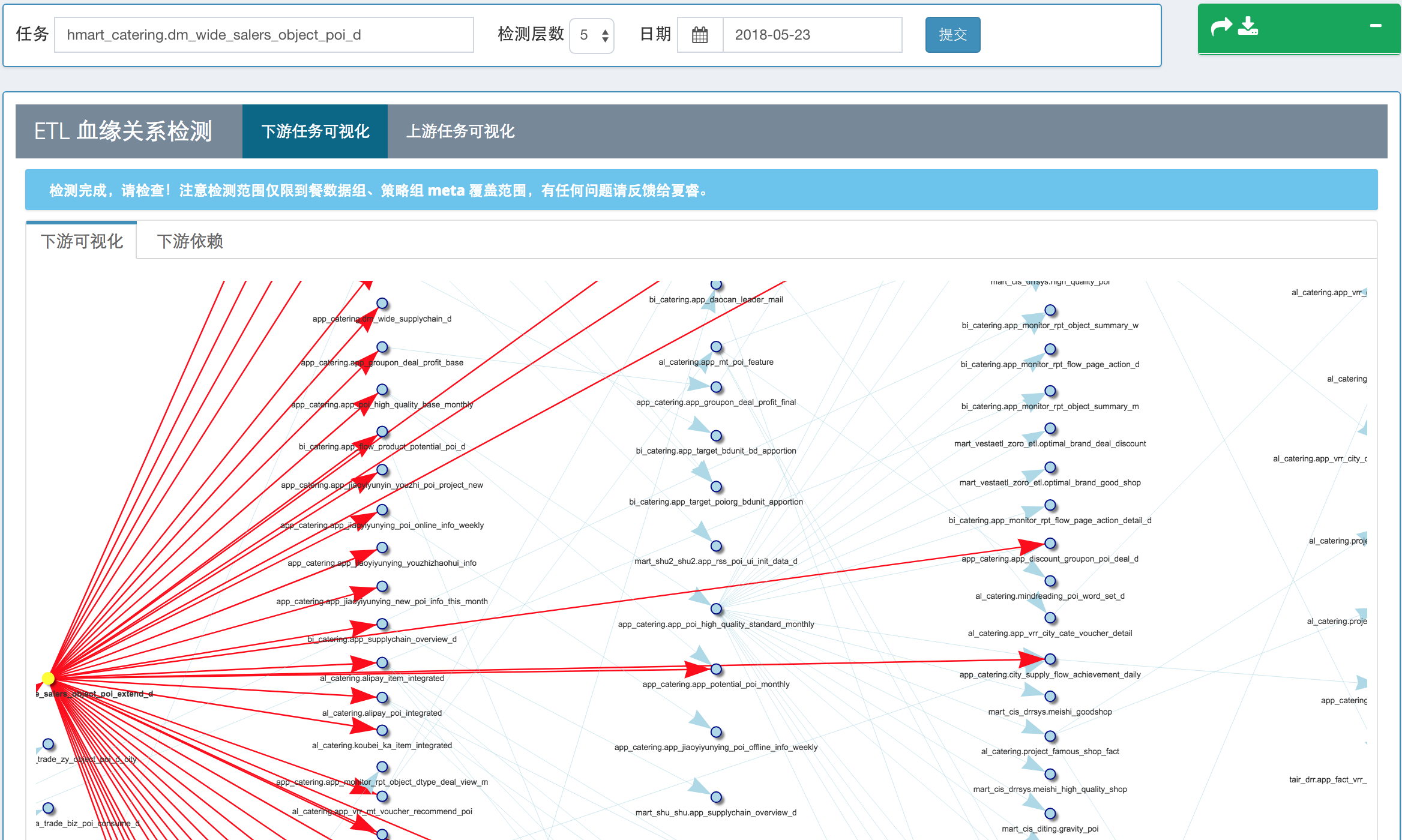
ͼ�� ETL ��������ϵ���ӻ�����
��������
����������R ��������ҵ������Ӫʵ���а��ݹؼ������ܸˣ�����Ϊһ������ͳ�Ʒ������������ԣ��ںܳ�һ��ʱ�䣬R �ķ�չ��Ҫ��ͳ��ѧ�����������Ž�������ݱ���ʽ������Ӧ���˳���R �õ�Խ��Խ�ҵ���֧�֣�Ʃ�����չ����� R ����ҵ�����ݽ�������ṩ�� Revolution Analytics���� SQL Server 2016 ���� R������ Visual Studio 2015 ��ʼ��ʽͨ�� RTVS ������ R ����������һϵ���¼���־���������ݷ�������� R �ĸ߶����ӡ�
����д���ĵ�Ŀ�ģ�Ҳ��ϣ��������������ع�����ͬѧ��һ���µġ��������ƵĿ�ѡ�
�������ߣ����ӣ����ŵ����������������ϵͳ�����ݲ�Ʒ�ŶӸ�����
��ǩ�� linux Mysql ��ȫ ������ ���� ���� ������ Ȩ�� ���ݷ��� ���� ͨ��
��Ȩ��������վ���²��������磬������Ȩ������ϵ��west999com@outlook.com
�ر�ע�⣺��վ����ת���������۲�������վ�۵㣡
��վ���ṩ��ͼƬ���زģ���Ȩ��ԭ�������У�����ʹ�ã�����ԭ������ϵ��

