��Python�а��账�����ݣ���2����: ����� itertools
2018-08-07 ��Դ��raincent

Python ���������һЩ�dz����õ�֧�ֺ��ߣ������漣��������Щ���߱��������߸�����һЩ���м���ģ���ڲ���������ʱ�����ã���������Ӧ�鿴���ù����е�һЩ���ߣ�“����”��ζ�ţ��ڴ��������£������赼���κ����ݼ��ɽ���ʹ�á�
ʹ�� map ����������
ʹ�� map �����������Դ����������е�ÿһ����Ա������µĵ�������
>>> r = range(10) >>> m = map(str, r) >>> next(m) '0' >>> list(m) ['1', '2', '3', '4', '5', '6', '7', '8', '9']
map �ĵ�һ���Ա�����ӳ�亯������Ӧ����ÿ����ĺ����� �ڴ����У���ʹ�� str ����Χ�е�ÿ������ת��Ϊ�ַ���������ͨ�� map �����������һ��ʱ���һ��յ�һ���ַ�����Ȼ����ʹ�� list ����ȡ�����е��������ݡ���ע�⣬�б��Ǵ� 1�������� 0����ʼ��������Ϊ����ͨ�� map ��ȡ�˵�һ����б���Ԫ�鲻ͬ����������֧��������ʡ��������������λ�ȡ�����
��Ȼ�������Ա�д�Լ���ӳ�亯�����������յ����� map ��һ������ֵ������������ճ�����������Ự�У�
def get_letter(i):
return chr(ord('a')+i)
�˴�����ʹ�� ord ��ȡ���ַ� 'a' ��Ӧ�����ִ��룬�����Ӻ������Ա����������µ��ַ����롣���� chr ���˴�������ת��Ϊ�ַ����ַ������˺����� map ���ʹ�á�
>>> r = range(10) >>> list(map(get_letter, r)) ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Map ������������ʽ
��ʱ�������ܻ������ 1 ����������ʶ�����������������ʽ����ȷ���ҿ��������µ�����
>>> list( ( get_letter(i) for i in range(10) ) ) ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
��ע��������ν�����������ʽ��Ϊ�Ա���ֱ�ӷ��� list�� ��˵����һ�㣬��������ʹ������ Python ����ʽһ��ʹ������������ʽ���ڴ����У�get_letter �����dz������������Խ���ֱ�ӹ���������������ʽ�С�
>>> list( ( chr(ord('a')+i) for i in range(10) ) )
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
���ƺ��еㆪ���ˣ������� Python �У�map �Ĵ���ʱ��Ҫ������������ʽ����������ijЩ�����������ʹ�������ܷ��㡣Ȼ�����ڴ��������£������ܻ�ʹ������������ʽ��������������
ͨ��������ʵ�ֽ�ά
��ʱ���������뽫һ��������ת��Ϊ��һ������������ֻ����ͨ��������������һ��ֵ��
>>> sum(range(20, 30)) 245
sum �����������ֵ����������������������ص���������������ܺͣ��ڴ������� 20 �� 30 ֮���������ֵ��ܺ͡����Ϊ“��ά”��������һϵ��ֵ��άΪһ����ֵ��Python ���ṩ��һ�����ڽ�ά��ͨ�ú���������ճ�����º�����
def sum_of_squares(acc, i): return acc + i**2
ʹ�ô˺���ʵ�ֽ�ά��������ʾ������Ҫ functools ģ�顣
>>> import functools >>> functools.reduce(sum_of_squares, range(10)) 285
��һ���Ա����ǽ��������Ա����ĺ�����������һ���ۻ�ֵ��������һ����ֵ��ij�ַ�ʽ��ϳ�һ�����µ��ۻ�ֵ��Ȼ�ش�ֵ���ڴ����У��ۻ�ֵ�ǵ�ĿǰΪֹ�����ƽ���͡�
��������������ʽ�Ŀɶ��Ա� map �Ŀɶ��Ը�ǿһЩһ����ͨ����һЩ�ɶ��Ը�ǿ���������������ʵ�ֽ�ά�����˺�������ijЩ�ض���;�����ã����ڸ������� map �Ķ�Ӧ���
map ����һ��������������һ��������������reduce ����һ���������������������������ĵ���ֵ����Щ���ͬ����һ�ִ����������ݵ�ǿ����
string.join ����
�������һ�����ڽ�ά�����ⷽ����
>>> tenletters = ( chr(ord('a')+i) for i in range(10) )
>>> '!'.join(tenletters)
'a!b!c!d!e!f!g!h!i!j'
����ַ����� join ��������һ������������ͨ����ָ���ļ���ַ��������������ַ���������һ�����������ַ�����������һ�㣺
>>> '!'.join(tenletters)
''
>>> tenletters = ( chr(ord('a')+i) for i in range(10) )
>>> ''.join(tenletters)
'abcdefghij'
>>> tenletters = ( chr(ord('a')+i) for i in range(10) )
>>> ' and '.join(tenletters)
'a and b and c and d and e and f and g and h and i and j'
��һ�е������ȷ�����˵������ǵ���ģ�һ�����꣬�Ͳ������յ��κ��������ע�⣬��ʹ�õ������Ĵ����У������������ij���ԭ������һ���У���������һ���µ��������������Կ�����Կ��ַ���������ֻ�ǽ������������е������ַ���������һ�������������Ӹ������ַ��������������ʾ��
����
���ﻹ��һ�����ú����������ڴ���������һ��������ĵ��������� �� 1 �����У����ṩ������ʾ����
>>> import math >>> notby2or3 = ( n for n in range(1, 20) if math.gcd(n, 2) == 1 and math.gcd(n, 3) == 1 ) >>> list(notby2or3) [1, 5, 7, 11, 13, 17, 19]
�������Ҫ�ع� notby2or3 �������뷵�ز��鿴�� 1 ������������ʹ�� filter ����ʵ���������������ʽ��ͬ�ȹ��ܣ�����һ�飬filter �����dz�ֵ�����ǹ�ע��
>>> import math >>> def notby2or3(n): ...return math.gcd(n, 2) == 1 and math.gcd(n, 3) == 1 ... >>> list(filter(notby2or3, range(1, 20))) [1, 5, 7, 11, 13, 17, 19]
�ҿ���ʹ����ν�� lambda ��������һ��������д�˹��ܣ����ⳬ���˱��̳�ϵ�еķ�Χ��
itertools ���
ʹ�õ�������ǰ�淴���ᵽ��ʱ������ʹ������Сģʽ��itertools ģ���ṩ��һ�ָ����ܷ�����ʵ����������ģʽ���dz�ֵ��ѧϰ��
��������Ҫ����һ�������ĵ���������������һϵ��������������
>>> import itertools >>> it = itertools.chain(range(5), range(5, 0, -1), range(5)) >>> list(it) [0, 1, 2, 3, 4, 5, 4, 3, 2, 1, 0, 1, 2, 3, 4]
����������Ϊ�����Ա������ݸ� itertools.chain���⽫������Щ�����������������������е��������б���Ԫ�����У���ô����ʹ�� Python �����������ʾ����λ�ú����Ա�����
>>> list_of_iters = [range(5), range(5, 0, -1), range(5)] >>> it = itertools.chain(*list_of_iters) >>> list(it) [0, 1, 2, 3, 4, 5, 4, 3, 2, 1, 0, 1, 2, 3, 4]
�����Խ��κε��������ں��������Ա������������б���Ԫ�顣ճ���������ݣ�
def forth_back_forth(n): yield range(n) yield range(n, 0, -1) yield range(n)
������ʹ�ô�������Ϊ itertools.chain �ṩ�Ա�����
>>> it = itertools.chain(*forth_back_forth(3)) >>> list(it) [0, 1, 2, 3, 2, 1, 0, 1, 2]
��������
����֪�������ʹ�� forth_back_forth �� itertools.chain������һ��ִ�к���/ǰ��/��������ģʽ����������Ľ����ճ���������ݣ�
def zigzag_iters(period): while True: yield range(period) yield range(period, 0, -1)
Ȼ����һ�£�
>>> it = zigzag_iters(2) >>> next(it) range(0, 2) >>> next(it) range(2, 0, -1) >>> next(it) range(0, 2) >>> next(it) range(2, 0, -1) >>> next(it) range(0, 2)
������������� next(it)�������������������Χ֮�䷴��ѭ������Ϊ while True ��ʵ������ѭ�������ڲ�û�д���������ж�ѭ����ִ�С������������������ݹҺͻָ�״̬��ֱ�� Python ���̣��ڴ�����Ϊ����ʽ����������ֹ�����ߣ������Զ��κ�����������ʹ�� close() �����������������������ںδ�ִ�С�
�������Ѿ�ע�����û��ʹ�� list ��˵�������������ݡ���������������������������ڳ��Դ���һ�������б�����Ȼ�������ľ��ڴ档
�������ס���⽫���ص������������������ forth_back_forth������ʹ�� itertools.chain ����Щ�������л�ȡ�������ʹ�� zigzag_iters ���������������Ϊ��Ҳ�᳢�Դ���һ��������ļ��ϣ�������ִ�к���֮ǰ��������֪�������������Ա�������ʹ�ڱ����Ա����������Ҳ����ˡ�����ζ�� Python ����ʱ�����Դ����������л�ȡ��������Dz����ܵġ�
�ڿ�ʼʹ������������������ʵ������һ�����õĸ�����ǣ�������֪��Ҫ����ͨ����������������ݹ����κμ��ϵIJ�����
����������
��Ϊ���ܽ� itertools.chain �� zigzag_iters һ��ʹ�ã�����봴��һ����ֱ�ӵİ汾��
def zigzag(period): while True: for n in range(period): yield n for n in range(period, 0, -1): yield n
ճ���������ݲ��鿴������������ؼ�����ȥ��
>>> it = zigzag(2) >>> next(it) 0 >>> next(it) 1 >>> next(it) 2 >>> next(it) 1 >>> next(it) 0 >>> next(it) 1 >>> next(it) 2 >>> next(it) 1 >>> next(it) 2 >>> next(it) 1 >>> next(it) 0 >>> next(it) 1
������һ�ֳ���ģʽ�������ⲿ��������һ�������ڲ��������ļ�����ʽ��Python Ϊ���ṩ�˱������ yield from ��䣬��������������д�Ĺ�����ͬ�� zigzag �п�������䡣
def zigzag(period): while True: yield from range(period) yield from range(period, 0, -1)
�������Ҫһ�������������ṩ��һ�����������뿼��ʹ�� yield from���ڴ����У�������ʹ�����ṩ�ĵ��������������һ��������������ô�ⲿ������Ҳ���������������������ؼ���ִ�� yield from ��䡣
itertools.chain �ı���
Ҫע������һ���������ԣ���ǰ�����������ܽ� zigzag_iters ������ itertools.chain һ��ʹ�ã���Ϊ��᳢�Դ���һ�����ĺ����Ա������ϡ�itertools ���������Ҳ���ǵ�����һ�㣬���ṩ��һ�����еı��� itertools.chain.from_iterable��
>>> it = itertools.chain.from_iterable(zigzag_iters(2)) >>> next(it) 0 >>> next(it) 1 >>> next(it) 2 >>> next(it) 1 >>> next(it) 0 >>> next(it) 1 >>> next(it) 2 >>> next(it) 1 >>> next(it) 0 >>> next(it) 1 >>> next(it) 2 >>> next(it) 1
itertools ���ṩ����������
������ itertools ���ҵ�һЩ�����ڴ������������ļ����̡�����֮һ���� itertools.islice��������ʹ�ô����̴ӵ������������������������г�ȡ�Ӽ����С�
>>> it1 = zigzag(5) >>> it2 = itertools.islice(it1, 0, 20) >>> list(it2) [0, 1, 2, 3, 4, 5, 4, 3, 2, 1, 0, 1, 2, 3, 4, 5, 4, 3, 2, 1] >>> it2 = itertools.islice(it1, 1, 20) >>> list(it2) [1, 2, 3, 4, 5, 4, 3, 2, 1, 0, 1, 2, 3, 4, 5, 4, 3, 2, 1] >>> it2 = itertools.islice(it1, 0, 20, 2) >>> list(it2) [0, 2, 4, 4, 2, 0, 2, 4, 4, 2]
�ú��������Ҫժ¼�ĵ���������ʼ�����ͽ�����������������ѡ���ṩ��������ij�̶ֳ��ϣ��������� range����Ҫע�⣺�� range ��ͬ����������ʹ�ø�����ֵ��
����
���� itertools ��������Ҳ����ӵIJ���֮һ���dz�ֵ�ù�ע��
ʹ�� itertools.groupby������ijЩ�����Ե��������зֶΡ�����ʾ����Сʱ����Ϊʮ����Сʱ�������ޡ�
>>> hours = range(12) >>> def divide_by_3(n): return n//3 ... >>> it = itertools.groupby(hours, divide_by_3) >>> next(it) (0, <itertools._grouper object at 0x1075ac9e8>)
��Ϊ itertools.groupby �ṩ��һ�������������һ�����麯��������Ըõ������е�ÿ����ִ�д˺����������麯���Ľ����һ�������Ϊ��һ����ʱ��������һ�����飬���а��������ֱ����һ�θ��ķ��麯��ֵ�����麯�� divide_by_3 ʹ��ȡ����������� // ��ִ�г�����Ȼ���������뵽��һ����С������
ͼ 1 ������ֱ��չʾ��ʾ���� itertools.groupby �����й��̡�
ͼ 1. ֱ��չʾ itertools.groupby
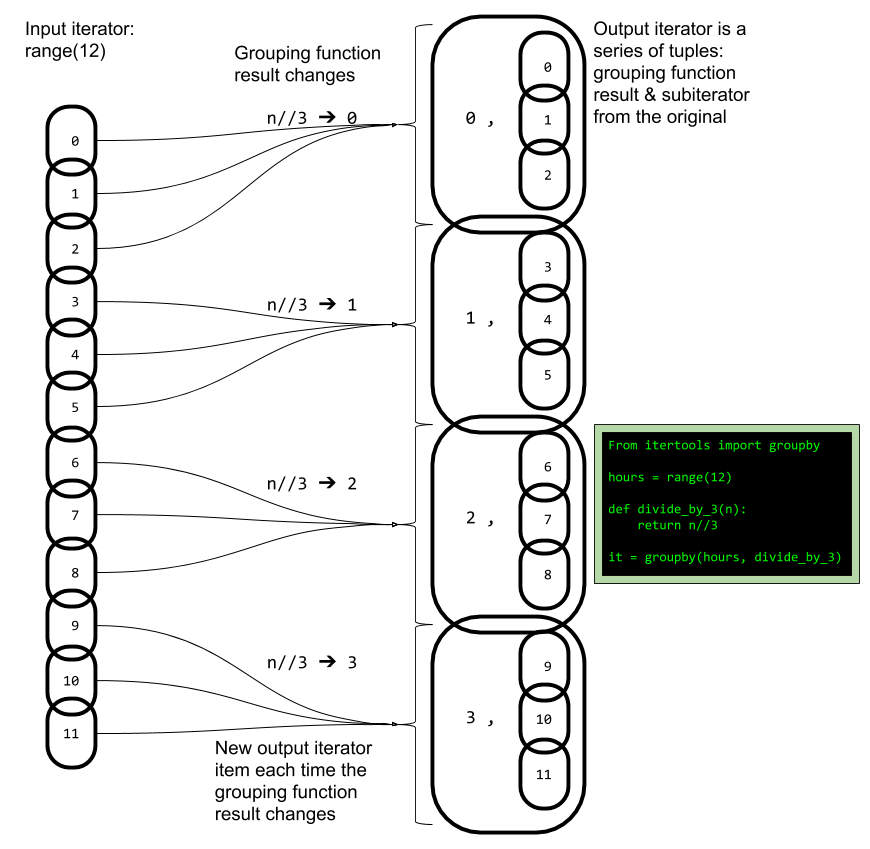
���� itertools.groupby �Ĺؼ��Ǽ�ס���麯��ֵ�ı仯�ǵ�������еķ������ԭ��ͨ��һЩ��ϰ�������ܹ�������Ϊ����������д���麯����
�����Ǹ�������о�һ�� itertools.groupby ʾ����
>>> hours = range(12)
>>> for quadrant, group_it in itertools.groupby(hours, divide_by_3):
...print('Items in quadrant', quadrant)
...for i in group_it:
...print(i)
...
Items in quadrant 0
0
1
2
Items in quadrant 1
3
4
5
Items in quadrant 2
6
7
8
Items in quadrant 3
9
10
11
�˴����ⲿѭ������ itertools.groupby����ѭ���е�ÿһ���һ��Ԫ�顣��Ԫ���еĵڶ���Ԫ�� group_it ����һ������������ͼ 1 ����ʾ����ˣ��ڲ�ѭ��������ÿ����ĵ�������
ʹ�������������з���
Ҫȫ�����ձ��̳��еļ�����������Խ������������������ʹ�á����ȿ�һ�� itertools �е�һ�����ܣ���������ش�������������
>>> inf_it = itertools.cycle(range(12)) >>> print(list(itertools.islice(inf_it, 32))) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 1, 2, 3, 4, 5, 6, 7]
�ڵ�һ���У���ʹ���� itertools.cycle����ͨ�����ṩ��������������������ѭ�����ڴ����У���ֻ�Ƿ������� 0 �� 11 ������С���ʹ���� itertools.islice ����ȫ�ؽ�������һ���Ӽ���������ʾΪ�б����һ�ʹ���� itertools.repeat��������һ��ֵ������������ֵ��
���̳�Ҫ̽�������һ�������ǽ��ʹ�� itertools.groupby �� itertools.cycle��
>>> inf_it = itertools.cycle(range(12))
>>> hours_32 = itertools.islice(inf_it, 32)
>>> for quadrant, group_it in itertools.groupby(hours_32, divide_by_3):
...print('Items in quadrant', quadrant, ':', list(group_it))
...
Items in quadrant 0 : [0, 1, 2]
Items in quadrant 1 : [3, 4, 5]
Items in quadrant 2 : [6, 7, 8]
Items in quadrant 3 : [9, 10, 11]
Items in quadrant 0 : [0, 1, 2]
Items in quadrant 1 : [3, 4, 5]
Items in quadrant 2 : [6, 7, 8]
Items in quadrant 3 : [9, 10, 11]
Items in quadrant 0 : [0, 1, 2]
Items in quadrant 1 : [3, 4, 5]
Items in quadrant 2 : [6, 7]
��ϸ�о����γ̣��ص�������Щ���������ߵĽ�����ʽ�����磬�����Բ鿴Сʱ����ѭ����ε��·��麯�������ѭ����
�����Կ�ʼ�˽���ν�������������յ������һ�����γ���Ȥ�ĵ�����ģʽ����������������Լ���ר�����������ʹ��ʱ�������Ϊһ��ǿ��ķ��������Ը�Ч�ؽ��������������ʱ���������⡣
ǰ��������
itertools ������Զ��ֹ���ڱ��̳��н��ܵ���Щ�������������Ѿ������˽�������һЩ���ߣ����Һܺõ��˽���������ӵ��������м�ֵ�Ĺ��� groupby��
����������һ�������������ҵ���ģ��������ĵ�������ͨ���ǹ��������Ա������ϸ��Ϣ�ġ�����Ϊ��ѧ����ơ��ҽ������ӱ��̳̺���һ���̳��еĹ����鿪ʼ�������� itertools �Ĺ����Լ����ù��ܺͱ����п����ڵ��������������ߡ�
�ڱ�ϵ�еĵ� 3 �����У������������֮�ء�����̽��Э�̣�����һ��������������������������˽���һ������ǿ��ʮ�ָ��ӵı���ģ�飺asyncio.
��Ȩ��������վ���²��������磬������Ȩ������ϵ��west999com@outlook.com
�ر�ע�⣺��վ����ת���������۲�������վ�۵㣡
��վ���ṩ��ͼƬ���زģ���Ȩ��ԭ�������У�����ʹ�ã�����ԭ������ϵ��

