纽约大学陈溪: AlphaGo Zero技术演进的必然性
2018-08-25 来源:raincent

本讲座选自纽约大学助理教授陈溪近日在2018第二届杉数科技AI大师圆桌会上所做的题为《 AlphaGo Zero技术演进的必然性-机器学习与决策的有机结合》的演讲。
陈溪:今天我要跟大家分享一下为什么要把机器学习和运筹学这两个学科结合起来,才能有效地解决很多实际的问题。
一、机器学习

什么是机器学习?首先需要有一堆数据,然后有机器学习的算法,对于数据的统计建模、概率建模和数据的假设来作为算法的支撑。机器学习一般常用的应用是对数据进行预测,比如预测明天股票的价格,这种都是一些基础的预测,更重要的是通过机器学习,去学习数据中的一些模式。

机器学习从大的角度分成两类:监督学习与无监督学习(Supervised Learning & Unsupervised Learning)。比如我们通过房间里的照片来识别人脸,用某些方式进行一定的标注来确定人脸在什么地方,这时候我们就叫做有监督的学习。监督学习的框架如上图所示,根据预测的函数,把机器学习的特征映射到值域上。

没有监督的学习是一个更加广泛的领域,比如我们需要把图片进行分类,这是完全根据人的需求和感觉,通过机器学习方法进行分类。

深度学习是一个自动提取特征的有效工具,比如图像的结构化让深度学习得以提取足够的特征。然而并不是每个领域的数据都能够通过深度学习的方式把有效的特征提取出来,比如在很多金融领域,一定要把深度学习与非深度学习的方法进行有效的比对。
二、从学习到决策
传统的机器学习通常处理静态数据,但是这并不能满足很多商业需求,许多商业应用最终需要做决策。

上面这张图把整个数据分析分成五个阶段:
第一阶段:Descriptive(描述性),对数据进行基本的描述;
第二阶段:Diagnostic(诊断性),对数据进行基本的诊断;
第三阶段:Discovery(发现),挖掘数据内在的模型;
第四阶段:Predictive(预测性),预测可能发生的情况的分析;
第五阶段:Prescriptive(指定性),数据驱动决策的过程。

在现实领域中,我们会遇到很多决策的问题,比如决策库存量、设施位置、路线规划、商品价格等。

AlphaGo Zero,作为围棋的一个重大进展,它不仅要对对手进行预测,同时还要对落子进行决策。所以Google设计了deep reinforcement learning(深度强化学习),它带有决策的成分,通过Monte Carlo tree search(蒙特卡洛树搜索),让机器和机器自己进行对战,从而进行学习。不管是学习还是决策,Simulation technique(模拟技术)在AlphaGo Zero中也很重要。
对于商业应用仍然很简单,这是为什么?在一个围棋的程序中,尽管搜索空间很大,信息是完整的,然后目标函数简单而明确(赢或输),而在商业决策过程中,目标函数可能会非常复杂。

这个研究工作叫Assortment optimization,基本上是一个推荐系统,比如搜索一个航班,它会自动帮我挑出性价比最高的几个航班。

做Assortment optimization?首先,我们要了解客户的购买行为,然后用choice model(选择模型)去做选择。

MNL是Logit类模型的基本型式,其选择一个产品的概率等于这个产品的效率(用户喜欢的程度)除上所有推荐产品的效率总和加1(S:推荐的产品,a:选择的产品,1:用户什么产品都不喜欢)。
在现实生活中还有很多复杂的情况,MNL不可能是一直有效的模型。

Nested logit models是先选择一个大类,然后在大类中再进行产品的选择,如上图所示,概率分成两部分,一部分是选择毛衣的概率,另一部分是选择毛衣的具体款式的概率,这样就构建了一个多层的选择过程。

给定choice model,如何选择最好的产品推荐给客户?我们选择一个S(推荐的产品)做组合优化,使得它数学期望值的收益最大化。然而,现实生活中更复杂的问题是你并不知道用户选择产品的概率。

Ruelala和唯品会是快消品的销售平台,销售时间很短,没有足够多的历史数据去学习用户对产品的喜好程度。Facebook在做在线广告的时候,若产品的选择数以百万计,这时候就无法估计用户对每一个产品的喜好程度。所以我们需要动态推荐系统,把机器学习和智能决策结合起来。

上图是简单的动态雏形,在每一个时刻我们假设给用户做一个产品的推荐,通过用户购买情况,不断的学习和做决策,一直到整个销售区间终止。如果知道用户的选择概率,可以把它做成静态的优化问题,如果不知道,就做成一个动态的优化问题。

怎么评估算法的好坏?在学术圈有一个叫Regret analysis的方法:将最佳分类与选择分类预期收益均差最小化。我们的目标是构造一个机器学习和决策的算法,使得在时间足够长的时候,收益差非常小,以及收益差怎么减少。
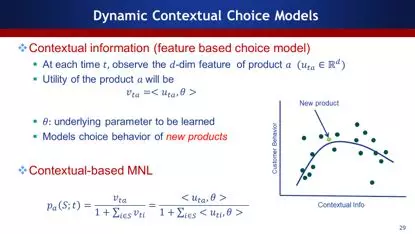
这些模型虽然很有用,但还不够复杂,机器学习的精髓在于特征的提取,比如利用上下文的信息,把用户和产品的特征提取出来,做一个动态的Choice Model,这样就能更好的服务于现实。
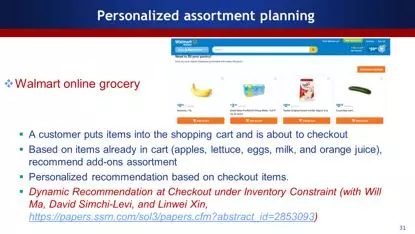
沃尔玛做过类似的工作,根据用户已经放在购物车里的产品,在最后结账的过程中再推荐产品。
三、总结

很多商业的问题极其复杂,我们要深入理解问题本质的结构,机器学习与决策要有机的结合起来。只有把机器学习过程,随机的建模和优化全部柔和在一起,我们才能对大数据进行更好的理解和处理。
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

