使用Apache Kafka和KSQL实现流处理普及化――第二部分
2018-09-24 来源:raincent

本文要点
- 针对客户操作、操作仪表板、在线分析等应用场景,使用Apache Kafka和KSQL构建数据集成和处理应用程序。
- 流处理的主要好处包括:数据增强一次性完成、低延迟处理、向客户Ops团队实时发送通知。
- 你可以使用变化数据捕获(CDC)工具把数据库的数据以及任何后续的变化镜像到Kafka主题。
- 使用KSQL,很容易把业务数据流和源自数据库、在Kafka主题中维护的相关信息合流。
- 扩展应用程序使其可以处理更多的通知,而不必修改过滤逻辑。
这是文章“使用Apache Kafka和KSQL实现流处理普及化”的第二部分。第一部分在这里。
在本文中,我们将介绍如何使用Apache Kafka®和KSQL构建数据集成和处理应用程序。这是一个来自电商领域的简单示例:在一个网站上,通过一系列事件跟踪用户评论。关于这些用户的信息,如姓名、联系方式、尊贵客户俱乐部资深会员,保存在数据库的某个地方。对于这类评论数据,至少有三种用途:
- 客户操作——如果一个尊贵客户俱乐部资深会员留下了差评,我们希望可以马上做些事情,降低流失这类客户的风险。我们希望应用程序在出现满足此条件的评论时立即通知我们。这样,我们就可以马上为客户提供服务,这远远好于我们等待一段时间后才运行的批处理为我们标记出需要联系的用户。
- 操作仪表板实时展示评论输入,滚动聚合,计算数量和平均分数,等等,并按用户区域划分。
- 结合其他数据(不论在数据湖中,还是在数据仓库中)在线分析分析评论数据。这可以扩展到更广泛的数据科学实践和机器学习应用。所有这些都需要访问评论信息及用户的详细信息。
我们将介绍下如何使用一种更为现代化的模式基于流平台实现上述功能。我们将使用开源项目Apache Kafka和KSQL来实现。KSQL是一个面向Apache Kafka的流SQL引擎,基于Kafka Streams API实现,后者是Apache Kafka的一个组成部分。
下图展示了流应用程序示例的工作原理。

图1.流数据应用程序
事件是用户提交到网站的评论,它们被以流的方式直接传递给Kafka。从这里,它们可以实时和用户信息联系起来,经过充实的结果数据会写回到Kafka。转换完成后,这些数据就可以用于驱动上述应用和目标了。转换逻辑只需要执行一次。数据一次性从源系统提取。转换后的数据可以供不相关的应用程序多次使用。不用对现有组件做任何修改,就可以添加新的源和目标。所有这些操作的延迟都非常低。
因此,高层设计是这样的:
- Web应用直接向Kafka发送评论;
- Kafka Connect把数据库用户数据快照以流的方式发送给Kafka,并且直接与CDC保持同步;
- 流处理把用户数据添加到评论事件,并写回到一个新的Kafka主题;
- 流处理会针对VIP用户的差评筛选出充实后的Kafka主题,并写入一个新的Kafka主题;
- 事件驱动应用会监听Kafka主题,在VIP用户留下差评后立即推送通知;
- Kafka Connect把数据以流的方式传入Elasticsearch,供操作仪表板使用;
- Kafka Connect把数据以流的方式传入S3,供长期在线分析使用以及和其他数据集一起使用。
其中,主要好处包括:
- 数据增强一次性完成,可供任何应用程序消费;
- 数据处理延迟低;
- 可以在VIP客户留下差评后立即通知客户Ops团队——提供更好的客户体验,增加业务保留机会;
- 容易扩展,可以按需增加新节点,实现更大的吞吐量。
实现
让我们看一下构建这个应用程序的详细过程。GitHub上提供了所有示例的代码以及docker-compose文件。
把数据写入Kafka
Web应用程序有多种方式可以使事件流入Kafka。
- 许多客户端库都提供了Producer API,面向的语言包括Java、.NET、Python、C/C++、Go、node.js等;
- 开源REST代理,可以发起HTTP调用把数据发送到Kafka。
在我们的例子中,应用程序使用了Producer API。
Web应用程序发送给Kafka主题“评级(ratings)”的消息格式如下:

使Kafka可以访问数据库中的数据
在构建应用程序的时候,经常需要使用存储在数据库中的数据。在我们的例子中,用户数据保存在MySQL中,不过,设计模式都是一样的,与采用哪种具体的RDBMS技术无关。
在使用Kafka编写流处理应用程序时,集成保存在数据库中的数据的标准方法是,确保数据本身在Kafka中保存和维护。这比听上去简单——我们只需要使用数据变化捕获(CDC)工具把数据库中的数据和任何后续的变化镜像到一个Kafka主题。
这样做的好处是隔离了数据库和流处理。这主要有两个好处:数据库不会因为我们的请求增加开销,我们可以自由使用我们选取的数据,而又不会使我们的开发和部署流程和数据库所有者的相耦合。
CDC技术和工具不止一种,我们这里就不介绍了。由于数据在MySQL中,我们使用Debezium项目作为我们的CDC工具。它会把用户表的内容快照到Kafka,并使用MySQL的binlog即时检测后续MySQL中数据的变化并复制到Kafka。
图2详细展示了数据变化捕获过程的数据流动。
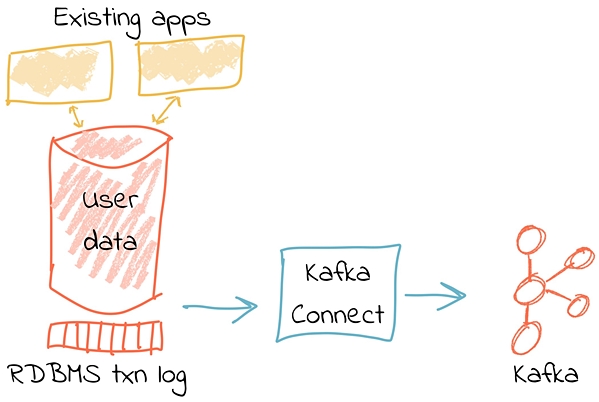
图2.流应用程序变化数据捕获
从数据库流出、流入Kafka主题asgard.demo.CUSTOMERS的消息格式如下:
{ 
使用数据库信息充实事件流
使用KSQL,很容易就可以把源于数据库、在Kafka主题中维护的相关信息合并到评级中。
合并细节如图3所示:
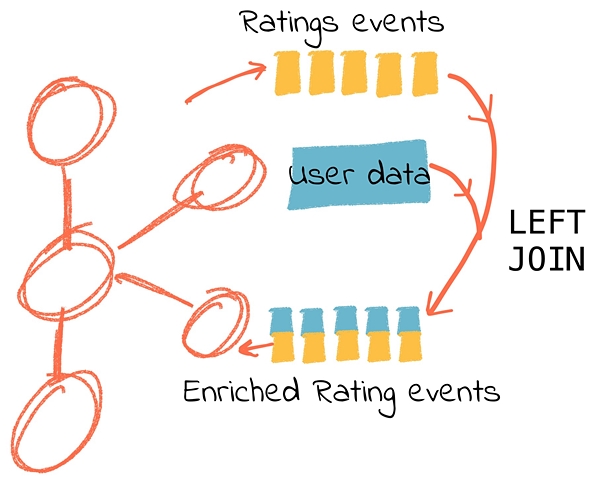
第一步是确保客户主题中的消息以关联列为键,在这个例子中是客户ID。我们实际上可以使用KSQL进行重新分区。KSQL CREATE STREAM的输出被写入一个Kafka主题,在默认情况下,会以流本身的名称命名:

现在,到达asgard.demo.CUSTOMERS主题的每条信息都将写入正确设置了消息键的Kafka主题CUSTOMERS_SRC_REKEY。注意,我们不一定要声明任何模式,因为我们在使用Avro。KSQL和Kafka Connect都无缝集成了开源的Confluent Schema Registry,序列化/反序列化Avro数据,并在Schema Registry中保存/检索模式。
为了进行合并,我们使用标准的SQL联合查询语法:

我们可以查看这条查询处理的消息数量:

实际上,这条SQL语句本身就是一个应用程序,就像我们在Java、Python、C……中编写的代码一样。它不断地执行,接收输入数据、处理数据、输出数据。我们在上面看到的输出是该应用程序的运行时指标。
使用KSQL过滤数据流
我们前面创建的JOIN查询其输出是一个Kafka主题,在源自源主题ratings的事件的驱动下实时填充,如下图4所示:

我们可以构建第二个KSQL应用程序,由这个派生主题所驱动,并对数据做进一步地处理。这里,我们将简单地过滤所有评级流,识别那些同时满足如下两个条件的评级:
- 差评(评级范围1到5,小于3即为差评)
- “铂金”客户留下的评级
SQL给出的语义几乎可以从字面上表达上述需求。我们可以首先使用KSQL CLI验证该查询:

然后,和以前一样,这个持续查询的结果可以持久化到一个Kafka主题,只需为语句加上CREATE STREAM ... AS(通常使用缩写CSAS)前缀。注意,我们可以选择所有的源列(SELECT *),或者创建一个可用字段的子集(SELECT COL1, COL2),使用哪一个取决于创建流的目的。此外,我们将把目标消息写成JSON格式:

查看生成的Kafka主题,我们可以看到,它只包含我们感兴趣的事件。再次强调一下,这是一个Kafka主题——我们可以使用KSQL查询它——这里,我将跳过KSQL,使用流行的kafkacat工具查看它:

在离开KSQL之前,我们给自己提个醒,我们实际上仅写了三个流应用程序:

由Kafka主题驱动的推送通知
我们在上面创建的主题UNHAPPY_PLATINUM_CUSTOMERS可以用于驱动一个应用程序,如果有重要客户留下了差评,它就会给客户运营团队发送警报。这里的关键是,我们基于一个刚刚发生的事件驱动了一个实时的动作。基于批处理的分析下周才告诉我们,上周我们让一位客户失望了,这就没用了。我们希望现在就知道,以便我们现在就可以采取行动,向那位客户提供更好的体验。
Kafka客户端库有面向各种语言的——你几乎可以选择任何语言。这里,我们使用面向Python的开源Confluent Kafka库。这是一个构建事件驱动应用程序的简单例子。它在一个Kafka主题上监听事件,然后生成一个推送通知。我们将使用Slack作为我们的通知发送平台。为了简化说明,下面的代码片段删除了所有的错误处理代码。我们可以把一个API(如Slack的API)和一个Kafka主题集成,在这个主题上监听事件,从而触发一个动作。

下图5展示了使用Slack API发送用户通知。
[点击查看大图]

这里有必要重申一下,我们正在构建的应用程序(如果你愿意,可以把它称为微服务)是事件驱动的。就是说,该应用程序会等待一个事件,然后执行动作。它不是尝试处理所有数据并查找特定的条件,也不是一个响应某个命令的同步请求-响应服务。我们已经分离出了这些职责:
- 根据确定的条件过滤实时事件流是由KSQL完成的(使用我们前面介绍的
CREATE STREAM UNHAPPY_PLATINUM_CUSTOMERS语句),匹配的事件被写入一个Kafka主题; - 通知服务有一个唯一的职责,它负责从Kafka主题获得事件,并基于它生成一个推送通知。这是异步完成的。
这样做的好处很明显:
- 我们可以横向扩展应用程序,使其处理更多通知,而不必修改过滤逻辑;
- 我们可以使用可选的其他应用程序替换这个应用程序,而不必修改过滤逻辑;
- 我们可以替换或修改过滤逻辑,而不必触及通知应用程序。
Kafka和请求/响应模式
对于基于Kafka平台编写应用程序,有一种常见的质疑,就是事件驱动模式不适用于应用程序的流程,并由此推论,Kafka也不适合。这种观点是错误的,有两个关键点需要记住:
- 事件驱动模式和请求/响应模式都完全可以使用——它们不是互斥的,有些需求需要使用请求/响应模式;
- 决定因素应该是需求;应该挑战现有方法的惯性。在部分或全部应用程序的消息传递中使用事件驱动架构,你可以从它带来的异步性、可扩展性以及与Kafka的集成中受益,其他所有使用Kafka的系统和应用程序也是如此。
要了解有关这个问题的进一步讨论,可以查阅Ben Stopford的系列文章及其最新著作《事件驱动系统设计》。
使数据从Kafka流入Elasticsearch,用于操作分析
使用Kafka Connect很容易就可以使数据从Kafka流入Elasticsearch。它提供了一个由配置文件控制的可扩展的流集成。有一个开源的Elasticsearch连接器,既可以单独存在,也可以作为Confluent平台的一部分。这里,我们将使原始评级及警告信息流入Elasticsearch:
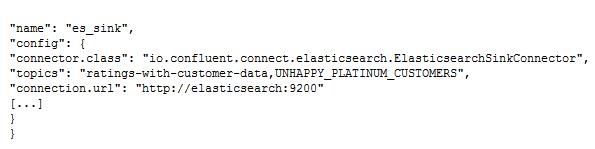
在从Kafka Connect到Elasticsearch的数据流上,使用Kibana很容易在经过充实、过滤的数据上构建一个实时仪表板,如图6所示。
[点击查看大图]

使数据从Kafka流入数据湖
最后,我们将使充实后的评级流入数据湖。在这里,它可以用于在线分析、训练机器学习模型和数据科学项目,等等。
Kafka中的数据可以流入使用Kafka Connect的各种类型的目标。这里,我们将看下S3和BigQuery,但是,使用HDFS、GCS、Redshift、Snowflake DB等也同样简单。
就像前面介绍的使数据从Kafka流入Elasticsearch一样,针对每项目标技术的设置只是一个简单的配置文件设置:
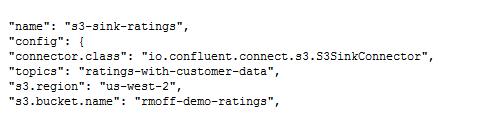
数据流入S3后,我们可以在桶里查看,如图7所示。
[点击查看大图]

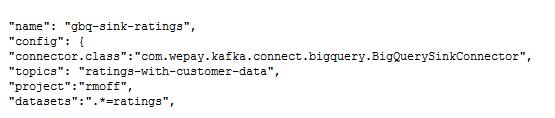
我们还可以使同样的数据流入谷歌的BigQuery:
[点击查看大图]

谷歌的Data Studio是众多可以用于分析这些来自云对象存储的数据的应用程序之一:
[点击查看大图]

这里的重点不是上面介绍的具体技术,不管你选择使用什么样的数据湖技术,使用Kafka Connect都很容易使数据流入它。
和KSQL及流平台一起走向未来
在这篇文章中,我们已经看了把流平台作为数据架构核心组成部分的其中多个有力的论据。它提供了一个可扩展的基础,由于其解耦特性,使系统可以灵活地集成和演进。分析工作可以从流平台的强大集成能力中获益。它是流平台,因此,实时不是其主要动因。应用程序可以从流平台获益,因为它是实时的,而且也因为它的集成能力。
借助KSQL,可以使用许多开发人员都熟悉的语言编写流处理应用程序。这些应用程序可以是简单的Kafka事件流过滤器,也可以是复杂的充实模式,从包括数据库在内的其他系统获取数据。
要了解更多有关KSQL的信息,你可以观看教程并自己试一下。文档中介绍了调整和部署实践。在Confluent Community Slack群组中,有一个与此相关的活跃社区。GitHub上提供了本文的示例。
关于作者
Robin Moffatt 是Confluent的一名开发大使,该公司由Apache Kafka的创建者发起成立。他还是Oracle ACE总监和开发冠军。职业生涯至今,他一直在跟数据打交道,从以前的COBOL和DB2到Oracle和Hadoop,再到如今的Kafka。他的主要研究领域是分析、系统架构、性能测试和优化。
查看英文原文:Democratizing Stream Processing with Apache Kafka® and KSQL - Part 2
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

