大数据实战项目:中国移动运营分析实时监控平台|项目需求实现
2018-11-16 来源:raincent

1.项目背景
中国移动公司旗下拥有很多的子机构,基本可以按照省份划分. 而各省份旗下的充值机构也非常的多.
目前要想获取整个平台的充值情况,需要先以省为单元,进行省份旗下的机构统计,然后由下往上一层一层的统计汇总,过程太过繁琐,且统计周期太长. 且充值过程中会涉及到中国移动信息系统内部各个子系统之间的接口调用, 接口故障监控也成为了重点监控的内容之一.
为此建设一个能够实时监控全国的充值情况的平台, 掌控全网的实时充值, 各接口调用情况意义重大.
2.技术选型:
Apache Spark
Spark Streaming 是核心 Spark API 的一个扩展,它并不会像 Storm 那样一次一个地处理数据流,而是在处理前按时间间隔预先将其切分为一段一段的批处理作业。Spark 针对持续性数据流的抽象称为 DStream(DiscretizedStream),一个 DStream 是一个微批处理(micro-batching)的 RDD(弹性分布式数据集);而 RDD 则是一种分布式数据集,能够以两种方式并行运作, 分别是任意函数和滑动窗口数据的转换。
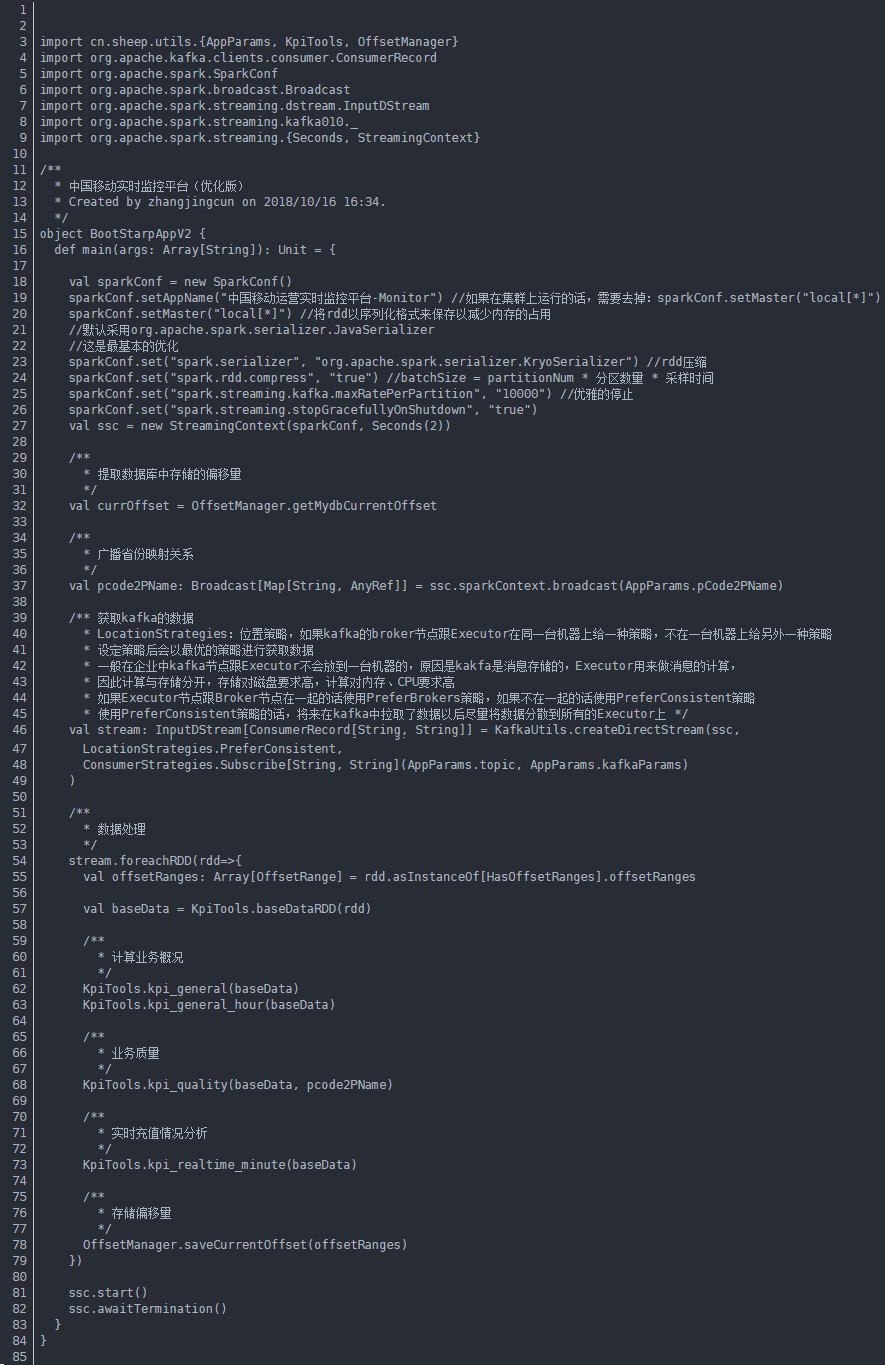
3.项目架构
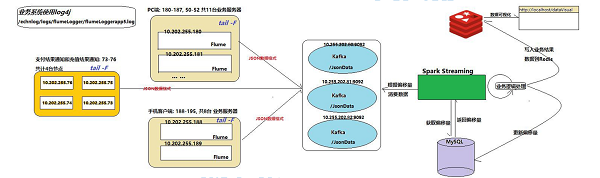
4.项目数据量
? 数据量每天大概 2000 到 3000 万笔的下单量, 每条数据大概在 0.5KB 左右,下单量数据大概在 15GB 左右.
? 最后充值成功的大概 500 到 1000 万,平时充值成功的大概五六百万笔.
? 月初和月末量比较大
5.目需求实现1.业务概况(显示总订单量、订单成功量、总金额、花费时间)
2.业务详细概述(每小时的充值订单量、每小时的充值成功订单量)
3.业务质量(每个省份的充值成功订单量)
4.实时统计每分钟的充值金额和订单量
整体步骤:
提取数据库中存储的偏移量–>广播省份映射关系–>获取kafka的数据–>数据处理(JSON对象解析,省份、时间、结果、费用)
–>计算业务概况(显示总订单量、订单成功量、总金额、花费时间)–>业务概述(每小时的充值总订单量,每小时的成功订单量)
—>业务质量(每个省份的成功订单量)—>实时统计每分钟的充值金额和订单量

项目需求实现:
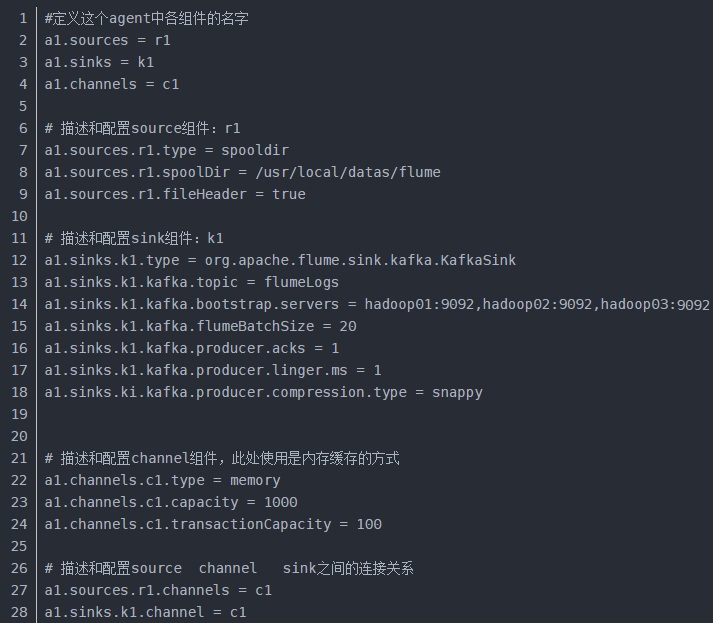
1)用flume收集数据,放入到kafka,下面是详细配置。
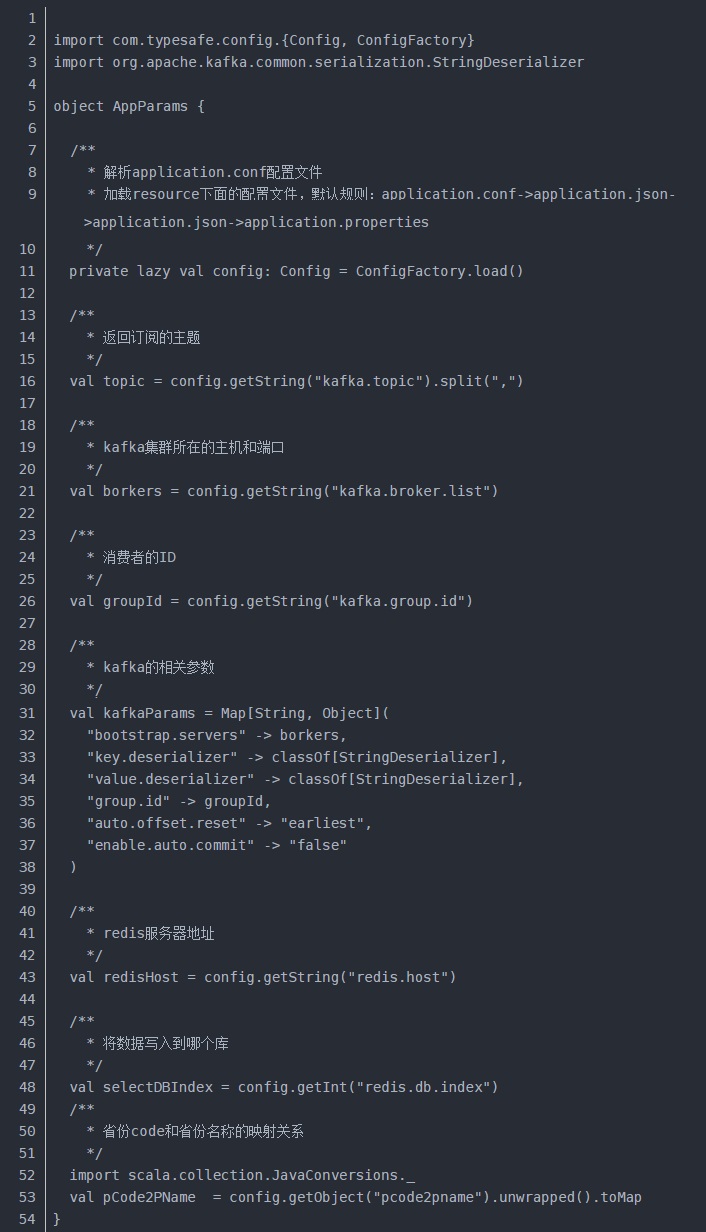
2)用SparkStreaming去消费kafka里面的数据前,做一些Kafka参数的配置以及放入Redis数据库所需要的配置。
(1)在IDEA中配置kafka和Redis相关参数,方便获取kafka里面的数据并且存储到redis里面
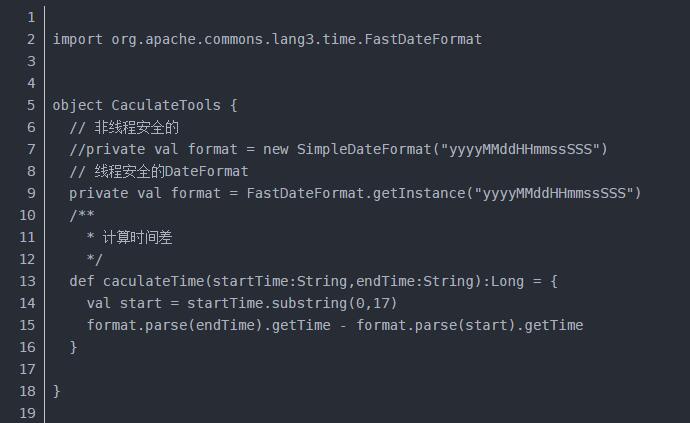
(2)方便计算订单完成所需要的时间,封装了一个类
(3)做一个Redis池去操作Redis中的数据
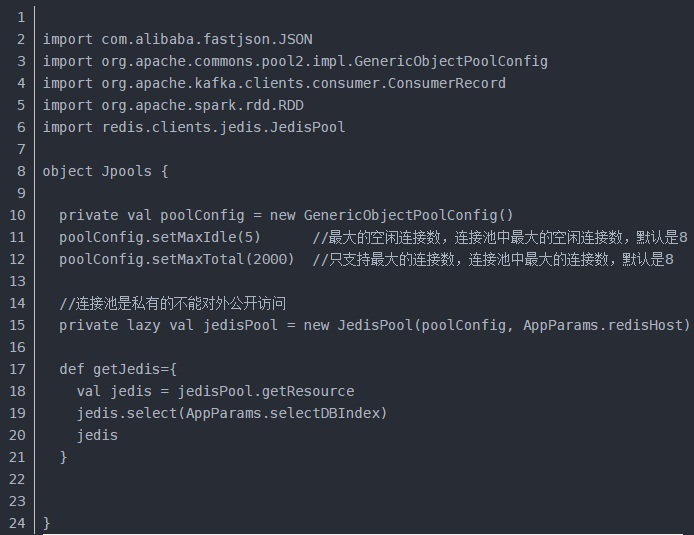
(4)每次放入Redis前需要判断偏移量,防止数据重复以及消耗资源
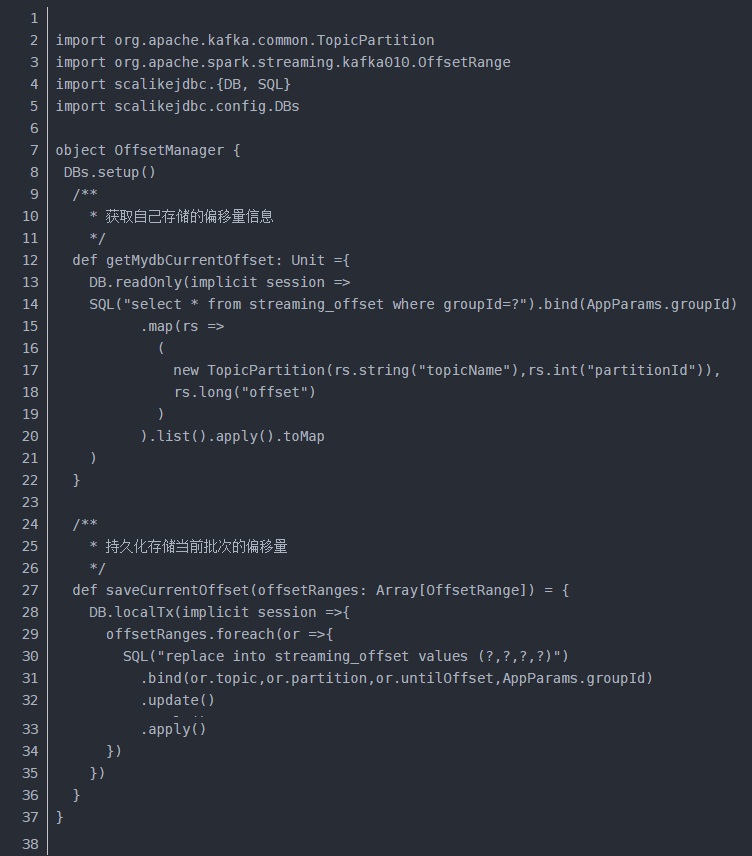
(5)设置自己的kafka、mysql(存储偏移量)、redis的配置
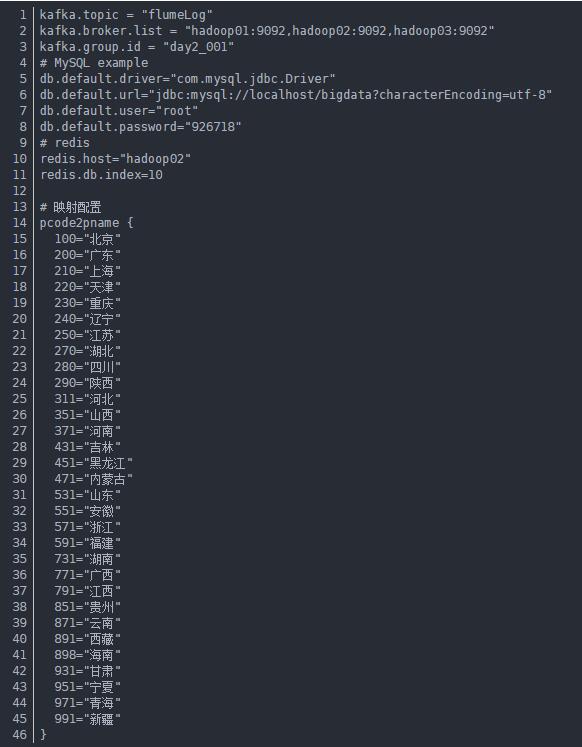
3)做好一系列配置之后就开始SparkStreaming数据处理的核心
先说明一下日志文件中字段的含义

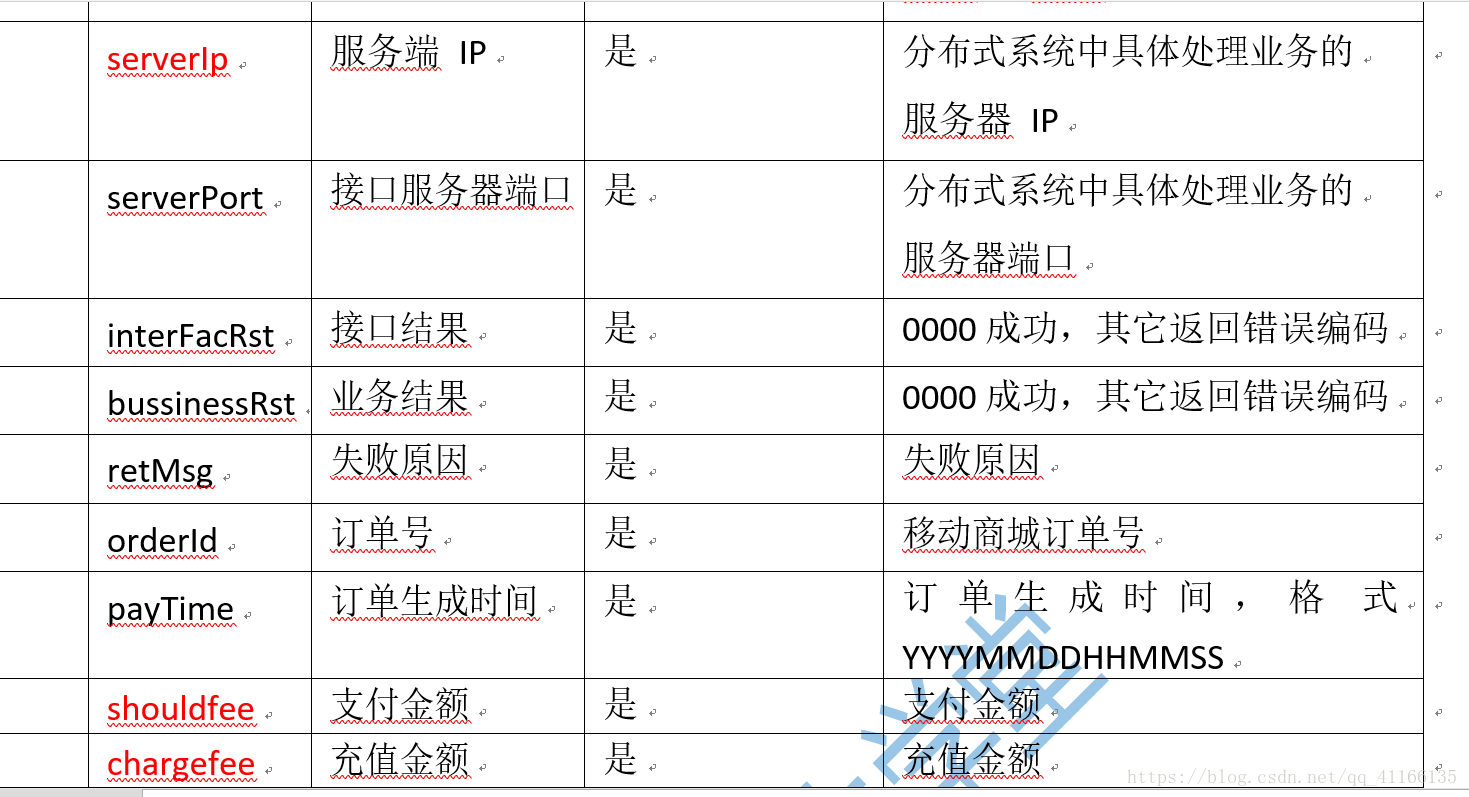
(1)下面是SparkStreaming核心代码
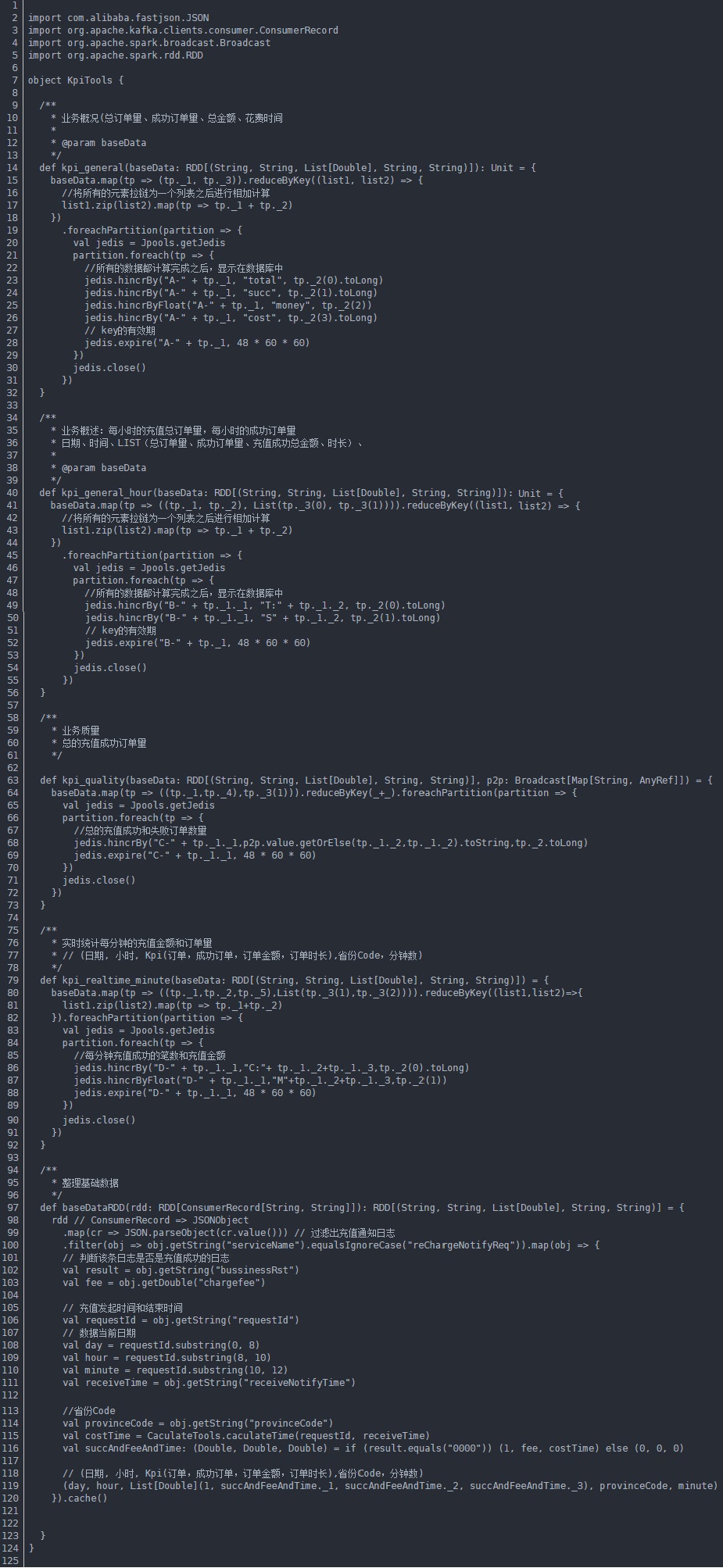
(2)将封装好的方法调用
pom文件
4.0.0

版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

