2018 �����̵㣺���Ǵ���һ��ʲô���ļ����˳����У�
2018-12-21 ��Դ��raincent


������ú�����˵��Խ��Խ�࣬���ߵĻ�������ҵ��Ա��Ҳ�в��٣�Խ�Ǻ���������Խ��Ҫ�˽����ƣ���ǰ���ķ���ȥ���꣬����������“���”����˷���������Щ��������������?��ƪ�������ҽ���ͼ����Ŀǰ�����������ķ�չ���ҳ����DZ����ԭ�������
����㳤�ڸ����������ǰ�ؼ�������ᷢ�ֽ�ʮ�������������������˷dz���ı仯�����ֱ仯������ÿһ�����������
�������ܹ��������˴ӵ���Ӧ�õ� SOA �ٵ�����;
���Ƽ����������˴������������;
�����ݿ����ӹ�ϵ���ݿ NoSQL �ٵ� NewSQL;
�ڴ�����������������������;
����ά�����ֹ���ά�� DevOps��AIOps;
��ǰ������ jQuery �� React ��������;
……
����֮�⣬����һЩ���˵������� AI�����������Ӳ������ӵ���Ϊ��ѧ��������һ����һ���ķ�ڡ�
����ȥ����Щ����ķ�չ������÷�����û��ͷ�����������������ȥ�����ᷢ�������֮������ϵ�����ǵķ�չԴ��һ�ֹ�ͬ���ƶ�������ѭ�����Ƶ�����
���Ҫ������ƶ������Խ�����������˳���һ�����֣��ڵ�ǰ���Ҿ��ÿ�����“��ԭ��”����������ﱻ����ʹ���ڸ���Ӫ���ᄈ�У����Ķ���ᷢ��ƫ�룬���Ժ����Ҳ������������������������Ƽ�����仰��
���ǵ�ǰ�����˳�����ʵ���壬�����������������������Ƽ���ʱ������������ķ�չ���ɴ˶��������Ҫ������һ�㣬���ǣ�
�Ƽ���ļ�����չ��Ϊ���������е�ģ��;
�Լ�������������ƥ��������ܹ�;
�Լ��������ļܹ���ƥ��Ŀ��������뷽���ۡ�
���棬�һ����������Ҫ�ļ����������ǵķ�չ������������
�Ƽ��㣺�����⻯�������� Serverless
�ȴ��Ƽ���˵��
2005 ������ѷ������ AWS�������������Ƽ������Ļ�����ǣ��ںܳ�һ��ʱ�����Ƽ��㶼û�ж����Լ���“�Զ����ݡ���ʹ�ø���”�������
�Ƽ�������Ҫ�ļ����Ƿֲ�ʽ����ͷֲ�ʽ�洢���ֲ�ʽ���㷽�棬�ʼ�ļ��������⻯��Ҳ������ν��“Software defined xxx”��ͨ���Լ��� / �洢��������Դ�����⻯��ͬʱ�ܹ����û����������Դ����������һ��ʼ������õ�ֻ���ļ��洢��һ�飬AWS S3 �����ƵĶ���洢��Ʒ�����Ǵ�������ʱ����һЩʵ�ʵ����飬���Ʒ�������������������������·��
��Ȼ�� ������Ʒ������ʹ�ͳ��������Ȼ��������Ƶģ�������ά����Ҫǧ�������ܵ�����ȥ�Ų����⡣����������Ҫ���Ʒ�����Ȼ���ĺ�Զ����ֻ�Ǵ�ͳ�����ڹ��ɵ���ʱ�������Ʒ�����⻯�����½���������ʱ���������ݷ������ƺܴ������������������ڽ������һ���⡣������һЩ MicroVM ��ʼ���֣����� AWS �ոշ����� FireCracker����ͼ�ں���������������ŵ㣬��Ҳ�ǵ�ǰ�Ƽ��㼼����һ����Ҫ��ע�㡣
�ֲ�ʽ�洢���棬��Ϊ�ļ������ݿ⣬�ļ�ͨ������洢�ķ�ʽ����ͽ���ˣ����ݿ������������ķ�չ���̣���ͳ�����ݿ���Ҫ��ֲ�ʽ�ܹ�ת�䣬ͬʱ��ᷢ���Ƽ��㳧�̳�Ϊ�����ݿ���з���������Щ�����ݿ��������Ƿֲ�ʽ������������֧���Ƽ������Եġ�
���Ƽ���ķ�չ�����У���һ����֧�� PaaS�������� 2007 ���Ƴ��� Heroku������̬����˵������һ�� App Engine���ṩӦ�õ����л�����PaaS �������Ϊ�������������Ƽ��㣬�����ʹ�����⻯���Ʒ�����������ȻҪ�Լ�����Ӧ�÷ַ����������ά��Ҫ����ֵײ�ӿڡ���Դ������ PaaS �ϣ���Щ�����ù��ˣ���ֻ��Ҫ��Ӧ���ϴ����ƶ˾��С�
���ǣ�֮ǰ�� PaaS ����ϲ�������ƽ̨������֧�ִ���Ӧ�ã����Բ�û�г�Ϊ��������Щ����ֱ�� Kubernetes ���ֺ�ŵ��Խ����
�� 2015 ��֮ǰ��OpenStack ���Ƽ���������������ܶ˾���� IBM/ ��ñ����������Ͷ����ע��Ȼ���������������������ֹ۵�һЩ��˾��˼�ƣ�������ͼ���� OpenStack ���빫�����г���������ʵ��ǰѸ�ٰ��ˣ��Լ���Ҫ������ Nebula �Ĺرգ��г������������ش졣�ټ��� Docker �� Kubernetes �Ŀ�������OpenStack �������Ѿ�����ǰ�ˡ�
Ȼ������ô�೧�̵�֧���� OpenStack �Ƿ��������?���ƽ��ܵ������볧��֮��Ĺ�ϵ������������µļ����ȵ���ǰ�����ɻ��ơ����̲����� Pure Play OpenStack��������������Ҳ�����ἰ��
——���ǹ� ��OpenStack �����̵㣬�ȳ���ȥ�����������?��
���ǣ�Kubernetes ����̫�ײ��ˣ��������Ƽ��㲢��Ӧ�������û��ṩ�� Kubernetes ��Ⱥ��
2014 �� AWS �Ƴ� Lambda ����Serverless ��ʼ��Ϊ�ȴʣ���������˵��Serverless �������� NoOps���Զ����ݺͰ�ʹ�ø��ѣ�Ҳ����Ϊ�Ƽ����δ�������ǣ�Serverless ������һЩ���⣬�������Խ�����������������⣬��ˣ�Χ�� Serverless ���з����Լ��� Serverless �����������ں�Ҳ�ǵ�ǰ��ǰ�ؿ��⡣
Serverless �����ǹ�ȥ 25 ������ SaaS ���ߵ����һ������Ϊ�����Ѿ�������Խ��Խ���ְ���˷����ṩ�̡�
——Joe Emison ��Ϊʲô Serverless �������������������������ơ�
�ܹ�������Service Mesh �� Serverless
�Ƽ���ΪӦ�ô����˷ֲ�ʽ�Ļ�����ʩ�����ǣ����Ӧ�û����Դ�ͳ�ĵ���Ӧ�õ�˼·���������Ƽ������岢����
��Щ��������ܹ��� SOA ���������ܶ�����Ϊ������һ��ϸ���ȵ� SOA����ȥ���� SOA �е� ESB ֮�������ø��������ܸ�ǿ�����ǣ�ʵʩ������ҪһЩǰ�ᡣ
Martin Fowler �����ܽ������ʵʩ��ǰ�������
������Դ�Ŀ��ٷ���
�����ļ��
���ٲ���
��������� Kubernetes ������Ҫ���ã���Ȼ�� Spring Cloud��Dubbo �������ڸ������Ѿ��dz����ƣ���������ԭ�����������׳���� Kubernetes �������������е��ȶ�Խ��Խ�ߣ�Ҳ��ʼ�кܶ˾��ʼ������һ����ջ����������
�� 2016 �꣬Service Mesh ��ʼ����������ע�⣬Kubernetes ���� Service Mesh���ټ��� CNCF ��һЩ��Դ��Ŀ������ k8s ��������ջ�����������ˡ�2018 �� Istio 1.0 ����������Ϊ����˳�����һ�ѻ�δ���������� k8s �� Service Mesh �����¡�
���������������۷�Ĺ����У���������ս���Ѿ����֡�Serverless ����˵ FaaS �ʼֻ�� AWS �Ƴ���һ�����ܣ�������������ҵ��ĸ����������˽�����Ϊ������Ľ���������Ҳ�ܼ��� SOA ��������һ������������ֵø�С�Ĺ��̣�FaaS ��� Function ������Ϊ��С�ġ�ԭ�ӻ��ķ�������Ȼ���������������һЩ���
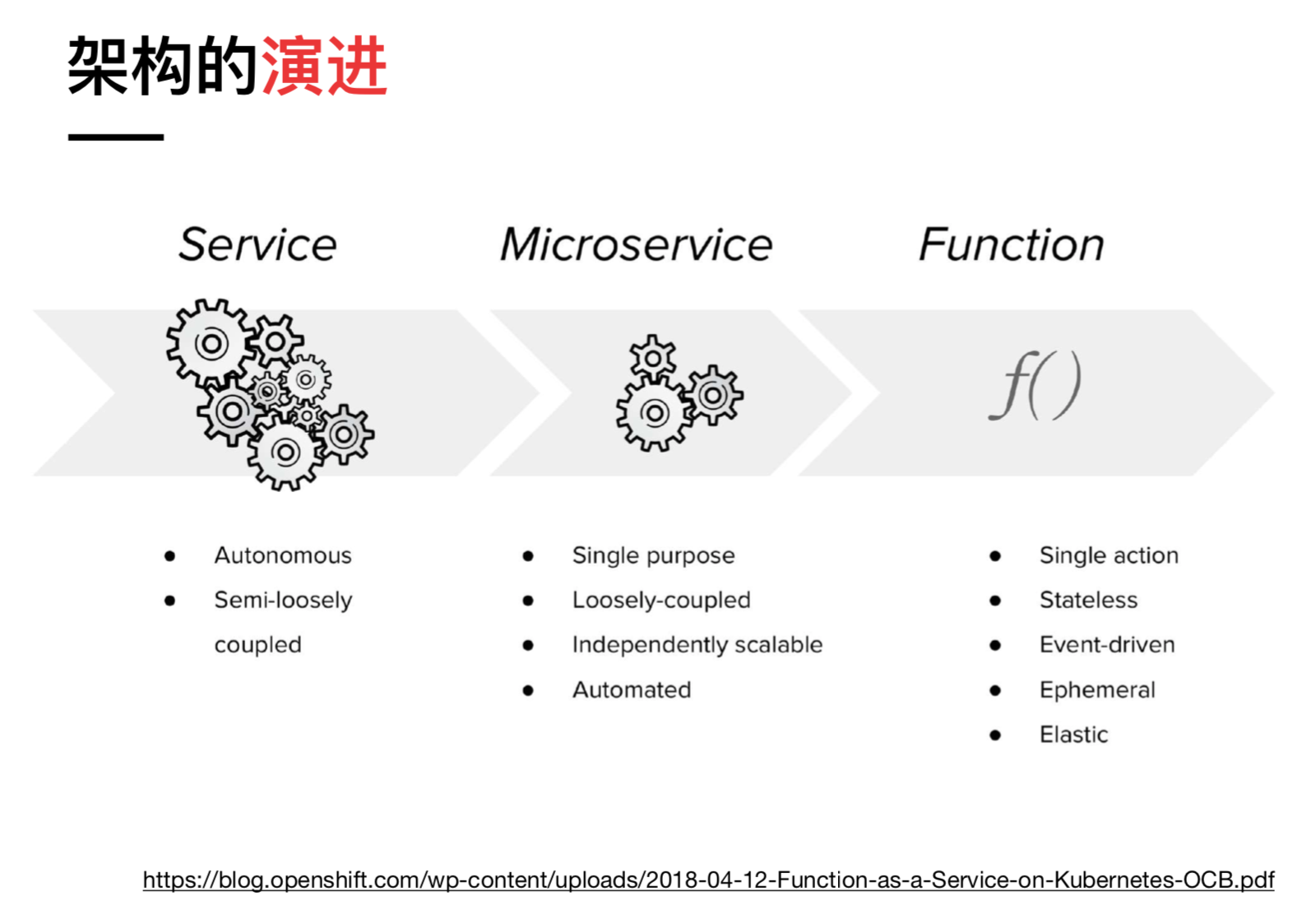
(������ �������� FaaS��)
��Ȼ������ Serverless ������뵽���мܹ���Ŀǰ��û�г���ľ��飬Serverless ����Ҳ����һЩ���⣬��������������ҵ���ע���ص㡣
���ݿ⣺�� NoSQL �� NewSQL
�ڹ�ȥ���꣬���ݿ�ķ�չͬ��������Ŀ��
2009 �� MongoDB ��Դ���ƿ��� NoSQL ����Ļ��һʱ֮�� NoSQL �ĸ�����������MongoDB Ҳ��Ϊ��������Ѹ���������ռ���NoSQL �����˴�ͳ��ϵ���ݿ��е����������һ���ԣ��Ӷ���������ȡ���˼���������������Ȼ֧�ֲַ�ʽ��Ⱥ��
Ȼ������֧������ʼ���� NoSQL ��ʹ�㣬�������ڹؼ�ϵͳ��ʹ�á�2012 �꣬Google ������ Spanner ���ģ��Ӵ˼�֧�ֲַ�ʽ��֧����������ݿ��������� TiDB��������ݿ��Ϊ������ NewSQL ���洫ͳ��ϵ���ݿ�� NoSQL ���ŵ㣬��ʼո¶ͷ�ǡ�
��Ŀǰ���е� SQL ���ݿ�ʵ�ַ���������NewSQL Ӧ�����������������ݿ������ʵ�֡�NewSQL �������� SQL��ACID �� Scale ����������Ȼ�;߱��������ݿ��һЩ�ص㡣���ǣ��� NewSQL �������ݿ⣬��Ȼ�кܶ���Ҫ��ս�����⣬������⻧�����ܵȡ�
——�����ʱ�����ݿ�ĺ����ص㡷
�������鷢չ������ͽ����ˣ��� 2014 ������ѷ���Ƴ�һ���ذ�ը������������ NVME SSD ����洢��� Aurora����ʵ������ȫ���� MySQL(������ bug ������)�ij������ݿ⣬ͬʱ�������ϸ߳� 5 �����ϡ�
���⣬���ֲ�ͬ��;�����ݿ�Ҳ������ȡ���˽ϴ�ķ�չ���������� LBS �ĵ�����Ϣ���ݿ⣬���ڼ�غ���������ʱ�����ݿ⣬����֪ʶͼ��ͼ���ݿ�ȡ�
����˵�����ݿ�Ŀǰ����һ���ٻ���ŵĽΣ��������Ƴ��̵�Ŭ�����������µ����ݿⶼ֧���Զ����ݡ���ʹ�ø��ѵ��Ƽ���������
�����ݣ�����������������
Google �� 03-06 �귢���˹��� GFS��BigTable��MapReduce ����ƪ���ģ������˴�����ʱ�����ڷ�չ�����ڣ��͵������� HDFS/HBase/MapReduce Ϊ���� Hadoop ����ջ����һֱ���������졣����У�����������ǿ��滻�ģ������еķ����˻����������У�����Ҫ�Ļ������Ǵ������档
�ʼ�����ݵĴ�����������ߴ�����MapReduce ������Ȼ�ã������������³��ֵ� Spark ץס��������ᣬ������ǿ��������ܵ�������������˳��ȡ���� MapReduce����Ϊ�����Ĵ����ݴ������档
����ʱ���ķ�չ��ʵʱ����������Խ��Խ�࣬��Ȼ Spark �Ƴ��� Spark Streaming ����������ģ��ʵʱ�������������ʱ�ϻ��Dz��������⡣2011 �꣬Twitter �� Storm �����������������ĺŽǣ��� Flink ��֮������
�����ڣ�Flink ��Ŀ��Ҳ���ٽ��Լ�������Ϊ���������棬���Ǹ�Ϊͨ�õĴ������棬��ʼ������ս Spark �ĵ�λ��
Apache Flink �Ѿ���ҵ�繫������õ����������档Ȼ�� Flink �ļ�����������������������������Apache Flink �Ķ�λ��һ���������������ѧϰ�ȶ��ּ��㹦�ܵĴ��������档�������һ��ʱ�䣬Flink ���������Լ�����ѧϰ���������ݳ������г����ͻ�ơ�
——�����Q(��ɳ)���������������㣺Apache Flink®ʵ������
Hadoop ����Ҳ������ Kubernetes ����ս��Hadoop ��������ר���ڴ��������ݵı���ϵͳ�� Yarn �ȣ����� Spark/Presto/Kafka ������Ҫ�� Hadoop �����Ѿ������� Kubernetes �����У�ʹ�� Kubernetes �����д����ݼ���ջ�����Ը��õ�������ҵ�ɡ�������ս�ı���֮һ���� Hadoop ����ջ��������Ҫ�ṩ�̣�Cloudera �� Hortonworks ��������ϲ������������������г����Ѿ��ݲ��������ṩ���ˡ�
Will Kubernetes Sink the Hadoop Ship?
��ά�����ֹ���ά�� DevOps
��ά�ڹ�ȥ�����������Ƽ��㼼����ǿ�ҳ������Щ�����Ƽ����ṩ�̵Ĺ�˾�����ǵ���ά��ְ�����������������Ƽ����Ĺ�˾�����ά��Ҫ������ߣ���ȥ�ľ����Ѿ����������ˡ�
����������Ҫ�ı仯���� DevOps �ij��֣���ά������ְ������ת�䣬��������ר��������ű���������������ˣ����DZ���� OpenStack ���� Kubernetes ��ר�ң�ͨ��� / ������صķֲ�ʽ��Ⱥ��Ϊ�з��ṩ�ɿ���Ӧ�����л�����
DevOps ����Ҫ�ķ��滹�Ǹı���Ӧ�ý��������̣��Ӵ�ͳ�Ĵ��ģʽ�������������Ӧ�õļܹ�����̬�ı��ˣ��䷽����Ҳ��֮���ı䡣DevOps �ͳ�������Ҳ����Ϊ����ԭ��Ӧ�õ�Ҫ�ء�
���� AIOps �� DevOps ��ʵ�� AI �����е�һЩӦ�ã��Ʋ����Ƿ�ʽ�ĸı䣬AI ����ά����ԶԶȡ�������˵����á�
ǰ�ˣ�ǰ��˷���
ǰ���ڹ�ȥ����ı仯ͬ���Ƶ����Ƿ��츲�أ�2008 �� Nodejs �ij��ֳ�������ǰ�˵���̬���� JavaScript �Ľ�����չ������˺����棬���մ�������ǰ�˵ĸ��
������⿴��ͳ��ǰ�˿����ı仯���������������� jQuery ת�Ƶ������ܣ�����Ҫ���� SPA ��ǰ��˷���ij��֡�
SPA ������ǰ�˵�Ӧ�û���Ҳ����ζ���ֿͻ��ˣ�����ҵ�������Դӷ����ת�Ƶ��ͻ�����ɡ�ǰ��˷�����ǽ�ǰ�˴Ӻ�˶�������������������߽硣��˶�ǰ����˵����Ϊ�����ݲ㣬ֻҪ�ӿ��ܹ���ȷ�������ݣ�ǰ�˲������ĺ������������ġ�
��ʵ�ϣ��ֿͻ��˵�ת���������˵Ľ��������Ǻϡ������������� Serverless����ǿ����״̬������ζ���㲻Ӧ���ú��ȥ������״̬�� UI�������ÿͻ������д���״̬��
Ϊ��Ӧ��Խ��Խ���͵Ŀͻ��˴��룬ǰ�˷�չ���ļ������� TypeScript��Redux/MobX��WebAssembly��WebWorker �ȣ���ЩҲ��ǰ���ص��ע�ļ�����
AI�����������»�����ʩ
�ִ��� AI �ǻ��ڴ����ݺͻ���ѧϰ�ģ��ںܶ˾������ݺ� AI ����ͬһ�����ݿ�ѧ���Ŷӡ��ڹ�ȥ���꣬AI �Ѿ��ø�����ijɼ�֤�������Գ�Ϊ�����������Ļ�����ʩ֮һ�����������ǵĻ��������ӵ����ܻ���
����� 2016 ��� AlphaGo �����ִ� AI ����㣬��ô AI ��չ����ʷ��ʵ�̡ܶ�ѧ���绹���о���ô���� AI ���㷨��������˾���Ǽ��ڽ� AI Ӧ�õ�����������
AI �Ӹ�֪����·�Ϊ����飬һ���Ǽ�����Ӿ�����һ���Ѿ��Ƚϳ��죬����������ʶ�������⡢�˶���ⶼ�Ѿ�������ʵ�ʳ����С���һ������ NLP����Ȼ����Google ���������ǵ� AI ����ȷ���Ѿ����ߣ���ʵ������Ȼ��̫���ã������ֻỰ������û�н����Chatbot ������������չ�������Ի���
��֮��������ͨ���˹����� AGI �����ǻ�Զ���������ڻ�������ͷ����AI ��Ȼ�ڳ������Ե���Щ���ȣ����似����Ӧ������ʵ�ġ�
ֵ��ע����ǣ��� 2018 �꣬���ڼ����漰������ҵ��Ĺ�˾�����ܹ�����֮ǰ���Ƽ��㲿������Ϊ�����Ƽ��㲿�ţ�
9 �� 30 �գ���Ѷ�ܹ��������³��������ǻ۲�Ʒ��ҵȺ;
11 �� 26 �գ����O�żܹ���������������ҵȺ����Ϊ������������ҵȺ;
12 �� 18 �գ��ٶȵ����ܹ�����֮ǰ����������ҵ������Ϊ��������ҵȺ��
�Ƴ�����֮���Խ� AI ��Ϊ���ǵĶ���ս�Բ����Ƽ������һ������Ϊ AI ������Ҫǿ��ġ�ר�Ŷ��ƵĻ�����ʩ�����Ƶ�һ���dz��ʺϵij���;ͬʱҲ��Ϊ AI ������һ���ż���������Ϊ�����Ƽ�����컯��һ���㡣��֮����Щ�Ƴ���ͨ�� AI �������ǵ��Ʒ���
����������ȷ����
2018 �����������������������Ļ��⣬��������Щ������ƭ�֣����Կ��������������� 2018 ���кܴ�ķ�չ��
����ɷ�Ϊ�����棺
һ�����ǹ�����һЩʹ����������̽����ͻ�ơ������� POW ���õĹ�ʶ���ơ������������ܡ����ݴ洢�ʹ������������ȵȡ���Ȼ�����ԶԶû�еõ��������������ǣ��̫�࣬��һ����Ҳû�й��ϵ��������������
��һ�����������������죬���д�������Ϊ�����˱���һ�������ڲ�������̽�������������ó�����һ��������������ˮ�����⣬�Ƴ� BlockChain as a Service��
���������ʱ�̣���������δ����̫��IJ�ȷ�����ˣ�������Ԥ�⣬�������ﲻ�ٶ�̸��
���������Ե���㣺Ϊ�η�չ������
�������ڹ�ȥ����һֱ���²����ƺ�һֱ�ڳ����У���������Ӱ�����IJ�Ʒ��Ӧ�ñȽ��١���������һ��Ŀ��������ջع�Ϊ���͵���ߡ������������ļ��������˸���ͨ��Э���Ƕ��ʽ����ϵͳ�Ϳ������֮�⣬�����곴�����ľ��DZ�Ե�����ˣ�Ȼ������Ե����Ҳ�dz�������������
��ʵ�ϣ���Ե����Ķ��岢û����������������Ե��ʲô��û�й�ʶ���е�˵�ն˽ڵ㡢�����豸�DZ�Ե���е�˵ CDN �DZ�Ե���е�˵·�������������DZ�Ե�����е�˵δ���� 5G ��վ�DZ�Ե��
��Ե����ļ���Ŀǰֻ����һ�� EdgeX Foundry��Ȼ���ڸ���Ŀ��Ŀǰ��������һ���д����Ե��������ļ�����������һЩ������ռ��ڵ�ռλ��Ϊ��
Ϊʲô��������?��ʵ�����⣬��Ϊ��������һ���ܺ�Ԥ���δ�����ơ�
�ӻ��������ƶ�����������һ���������ŵĹ��̣������ն˽ڵ�������ӣ�����ÿʱÿ�̶����ߣ���������������һ�¾����������ˣ��ն˴������ֻ�����κο��������豸��
����Ϊ���Ǵ�Ҷ����õ������ƣ��������еij��̶���ǰ�����������֣���ͼ��Ϊ��һ�������ߡ�
���������õĽ��������������������ûˮ�Եľ��ء���ʷ�ϣ�NFC �ƶ�֧����������ͨ��Э�鶼������������
NFC ���棬���й����������� miniSD ���� NFC ����������Ӫ�����ƴ� NFC �� sim �������ֻ����̸�Ը�⽫ NFC ����ֱ�Ӽ������ֻ��С��ڹ��⣬����������Ӫ���Ƴ����� NFC ���ƶ�֧������ Isis��ƻ���ȸ�������Լ��� NFC Ǯ������ Android ��Ӫ���ֻ�Ҳ��뽫 Android Pay �����滻Ϊ�Լҵ�֧�����ܡ�
������ͨ��Э�鷽�棬WiFi��������RFID��ZigBee����������˲�ͬ�����淽�����ڰ�����ҵ����������ҵ֮����˽��ͨ��Э������ʮ�֡�
������Ϊ������Э��������ᣬ���������Ƕ�û�а취�Ľ�������������֧���������豸����ӣ����������γ��� iOS �� Android һ����ƽ̨�����������������ķ�չ�����ض���Զ��
�ǻ۳�����������֮������ߣ�Ȼ�������ӵ�����������ʮ���ˣ�����û�ܿ���һ���ɹ�����ذ�����
���ԣ��������ķ�չ�������ƶ�������һ��һ�����ͣ�����ͨ���ڹ��������ϵ�Ӧ�ã�����һ�����������������������ǵ����
�ӵ��µļ�����δ��
����������̵㣬��ᷢ����ԭ������˵�������Ƽ��������ǵ��»�����������չ�Ĵ����ƣ������������֮�£��ƶ���ͬ�����������Ӧ�ķ�չ��
���еĴ������������ǻ���ѧϰ��Kubernetes��Serverless�������ǵ������ʱ��������չ�������ɣ��������ͬ����۵㣬����Եó�����һ��Ԥ�⣺
��ͳ��Ӧ�ÿ�����������������Serverless Ϊ�������������Ƽ��㣬�������ն˺��Ƶĸ���ȵļ��ɡ��������ķ�չ�����ܻ����������ƺͶ˵Ľ�����ģ�������Ǻ������еĻ���������ӽӽ���
��Ϣ�����ĸ������������ڼ��̺���ʾ���ļ������ų�����ʹ֮��Ϊ�����ܹ���֮��̸����֮һ�����У��ܹ����������ܹ������Ķ�����Щ��չ��������ǵ�ѧϰ��ʽ��������ʽ�����ַ�ʽ—һ�仰�����ǵ����ʽ��
——������ӵۡ����ֻ����桷
�����ֻ����桷�� 1996 �����ģ���������Ļ�������ǰ����ֻ��ƾ�յ�������������֪��ͨ�������ļ�����չ·���ִܵ�������롣
�����ı����뼼����չ����
�����ڲ��ϵ��Ƴ³��£������ۻ����ң������ץס����Щ�����ı��ʣ��ᷢ��̫�����²�û�������¡�
���������ĸ����������Ҫ�����������һ�£��ᷢ�����е�һЩ�й�ͬ�㣺
���⻯����Ӳ����Դ����Ϊ������Դ��Ȼ�����ͳһ���Ⱥ�����
���룺����������������ٵ�������������ںϣ�����ļ����������Ƶ���̬��
��������Ǻ�˵�����ǰ�˵�ǰ��˷��롢������ȵȣ����ǽ���ע����룬����ϵĹ��̡�
���ţ�������ͬ�ķ����������������һ�����壬��������õ�Э����
���ܻ����÷�����Ի����������Զ��������ǰ��Ҫ�˹���ɵ����顣
ʵʱ��������ʹ����ڼ���ʱ������ɣ��Ӷ�ʵʱ�ĸ��跴����
��Ȼ�����л���һЩ��©��������Щ�㲢����ͬ�������������ǣ���Щ��������һЩ��ͬ�ı��ʣ������Dz�ͬ����������չ�Ĺ�ͬ����
�ٽ�һ������ʲô���ƶ������ķ�չ?
���������Ѿ�֪���������ij��淢չ���ƣ����ǣ����Ԥ�������ĵ߸�ʽ����?ҪԤ�������������Ҫ��������ȥ�ھ�����������Դͷ��
����������ƾ�շ�չ�����ģ�������Ҫ�����ڸ���Ӳ���ϣ������ķ�չ��Ҳ�벻��Ӳ����֧�֡�
����˵������Ӳ���IJ��������ͱ�֧���������ķ�չ�������Ƽ���ĵ���������Դ�ڴ��ͻ��Ѿ���֧�Ÿ߲�������������ת������һ��Ӳ�������⻯���ֲ�ʽ������������
�����ĵ߸�ʽ���£�һ������Ӳ��֧�ֵĻ����ϣ��������е������ܹ�������Ӳ���������ھ��ٷ����߸��Ŀ������Ѿ���С�ˡ�
��Ȼ���Ⲣ����˵�����ڣ��� Docker �ͱ��رҵĵ�������û�������ر��µ�Ӳ�������������������������չ���۵�һ���̶ȵ��ʱ䡣
���������¸���Ŀ����ԣ�������Ӳ���ĵ߸��ϡ�
AWS �Ƴ��� Aurora ���ݿ����һ���ܺõ����ӣ����ĵ������ǻ��ڷ���ʧ�Դ洢�������ش���������ڵ������ǣ�Ӳ���Ĵ��������������ϵ�ʱ���Խ��Խ�̡�
Ӣ�ض���Ӣΰ���з�������оƬ��Ҳ���ᱻ�Ƴ��̵�һʱ�䶩�����������Ӳ����������������������
���������һ�����������������̷���������Ӳ���Ľ������ȸ衢�����Ϊ�ȶ���ʼ���������ƺ��ն˵�оƬ��
���ҪԤ�������ķ�չ�����Dz��ܲ�ȥ��Ӳ�����ܴ������������������Ǵ�����������Ҫ��������Դ���֣�
���㣺AI ���ڼ�������������������оƬ���з����������ͨ����оƬ���ƶ��������ͱ�Ե����ķ�չ������Զ���������ֵ����Ӽ��㣬һ�����ռ���Ҳ�ؽ������߸���
�洢��Nano Flash �����ʧ�Դ洢���������Ŀռ䣬���ƺͶ˵�����Ҳû���ռ����������ʧ�Դ洢�����ڴ���������ͻ�ƣ����������ܹ��ؽ�������һ�ε߸���
���磺���緽�棬WiFi �����������������������ӵ�����ϵĴ����������;�����������������Ӿ��뽫������ 300 ��;����Ҫ������ 5G������� 4G ���ٱ������ݴ����ٶȺ͵�����������ʱ���úܶ�Ӧ�ö����˸��������ռ䡣
���ڼ�����չ���ܽ�����͵������ˡ�
ѡ�������з��յģ������һ���� To B ���� To C �Ĺ�˾��ѡ���˷������ļ�����ֻ�ǻ��ݱ�ɳ��ڵļ�����ծ���������һ�������ߵ��Ƽ��㹫˾��ѡ����˼�����ע����֮���˥�䣬�����Ǽ����ȥ�����л�������������������Ϊ�������ʱ�����������ѡ���Ҳ�ǽ������¼����ܵ�����һ��ԭ��
��������Ҳ�����˼����������ٶ�Խ��Խ�죬������ֻҪ���겻��ע�¼���������һ�ֱ����������Ĵ���������ÿ���˶��ܽ��ǡ�
��ϣ������ƪ���£����������������ķ�չ��֪�����ڷ���ʲô���Լ����ᷢ��ʲô��ֻҪ֪������Щ����ز�����ô�����ˡ�
��Ȼ�����ڸ����������ޣ������в����д�©֮������ӭ���۽�����
��ǩ�� dns Google Mysql ssd ���������� ������ �����ݴ��� �����ݼ��� ������ʱ�� ���� ������ ������ �ȸ� ������ ���������� ��������ҵ ��
��Ȩ��������վ���²��������磬������Ȩ������ϵ��west999com@outlook.com
�ر�ע�⣺��վ����ת���������۲�������վ�۵㣡
��վ���ṩ��ͼƬ���زģ���Ȩ��ԭ�������У�����ʹ�ã�����ԭ������ϵ��

