深度学习中不均衡数据集的处理
2018-12-21 来源:raincent

在深度学习中,数据是非常重要的。但是我们拿到的数据往往可能由大部分无关数据和少部分我们所关心的数据组成。那么,如何对这些数据集进行处理,才能得到我们所需要结果呢?工程师 George Seif 认为,可以通过权重平衡法和采样法来解决这个问题。下面是他的观点,雷锋网 AI 科技评论整理。

像萨诺斯一样给你的数据集带来平衡
并非所有的数据都是完美的。事实上,如果你得到一个完全平衡的真实世界的数据集,你将是非常幸运的。在大多数情况下,您的数据将具有一定程度的类不平衡,即每个类具有不同数量的样本。
为什么我们希望我们的数据集是平衡数据集?
在深度学习项目中,在投入时间到任何可能需要花费很长时间的任务之前,很重要的一点是要理解我们为什么应该这么做,以确保它是一项有价值的研究。当我们真正关心少数种类数据时,类平衡技术才是真正必要的。
例如,假设我们试图根据市场现状、房子属性和我们的预算来预测我们是否应该买房。在这种情况下,我们做出正确的购买决定是非常重要的,因为它是一项如此巨大的投资。同时,在我们本该买的时候,模型告诉我们不要买,这并不是什么大事。如果我们错过一栋房子,总会有其他房子可以买,但是在如此巨大的资产上做出错误的投资是非常糟糕的。
在这个例子中,我们绝对需要产生购买行为的少数类的数据非常精确,而那些不产生购买行为的类的数据,就没什么大不了的。然而在当我们观察实际数据的时候,「购买」类数据比「不购买」类数据少得多,我们的模型倾向于将「不购买」类数据学习的非常好,因为它拥有最多的数据,但在对「购买」类数据的学习上表现不佳。这就需要平衡我们的数据,以便我们能够对「购买」的预测更加重视。
那么如果我们真的不关心少数类数据呢?例如,假设我们正在进行图像分类,并且您的类分布类似于:

乍一看,似乎平衡我们的数据是有帮助的。但是我们可能对那些少数类并不感兴趣。也许我们的主要目标是获得尽可能高的准确率。在这种情况下,做任何平衡都没有意义,因为我们的大部分准确率都来自于具有更多训练示例的类。其次,即使数据集不平衡,当目标达到最高百分比准确率时,分类交叉熵损失也往往表现得很好。总之,我们的少数类对我们的目标影响不大,因此平衡不是必须的。
在所有这些情况下,当我们遇到一个我们想要平衡数据的案例时,有两种技术可以用来帮助我们。
(1)权重平衡法
权重平衡法通过改变每个训练样本在计算损失时的权重来平衡我们的数据。通常,我们的损失函数中的每个样本和类具有相同的权重,即 1.0。但是有时候,我们可能希望某些更重要的特定类别或特定训练实例拥有更大的权重。再次参照我们买房的例子,既然「购买」类的准确率对我们来说是最重要的,那么该类中的训练示例应该对损失函数有显著的影响。
我们可以简单地通过将每个示例的损失乘以取决于它们的类的某个因子来给类赋权。在 Keras,我们可以做这样的事情:
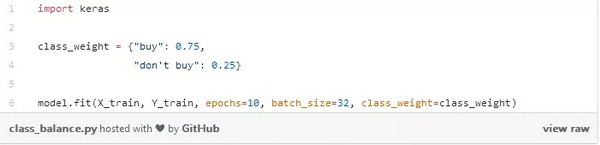
我们创建了一本字典,基本上说我们的「购买」类应该占了损失函数重量的 75%,因为更重要的是「不购买」类,我们相应地设置为 25%。当然,这些值可以很容易地进行调整,以找到应用场景中的最佳设置。如果其中一个类的样本明显多于另一个类,我们也可以使用这种方法进行平衡。我们可以尝试使用权重平衡法来使所有的类都对我们的损失函数产生一样大的影响,而不必花费时间和资源去收集更多的少数类实例。
另一个我们可以用来平衡训练实例权重的方法是如下所示的焦距损失法。它的主要思想是:在我们的数据集中,总会有一些比其他示例更容易分类的训练示例。在训练期间,这些例子将被有 99% 的分类准确率,而其它更具挑战性的示例可能表现不佳。问题在于,那些容易分类的训练示例仍会引起损失。当存在其他更具挑战性的数据点时,如果正确分类,那么这些数据点能够对我们的总体准确性做出更大的贡献,为什么我们仍然给予它们相同的权重?
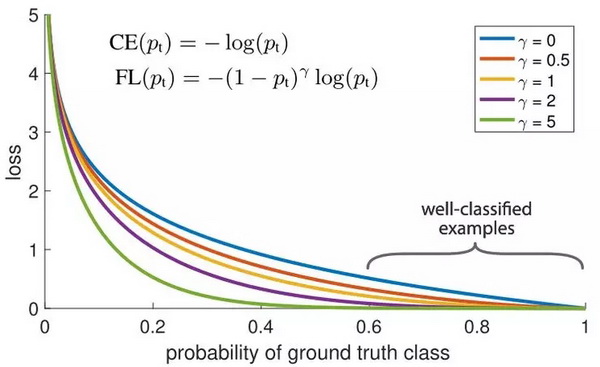
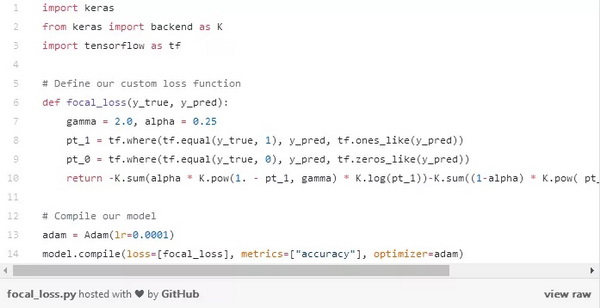
这正是焦距损失法可以解决的问题!焦距损失不是对所有训练实例赋予同等的权重,而是对分类良好的实例进行降权。这样做的直接效果是将更多的训练重点放在那些难以分类的数据上!在存在数据不平衡的实际环境中,大多数类将很快被很好地分类,因为我们有更多的训练样本数据。因此,为了保证我们对少数类的训练也达到较高的准确度,我们可以利用焦距损失在训练中给那些少数类更大的相对权重。焦距损失在 Keras 中可以很容易地实现为自定义损失函数:
(2)过采样和欠采样
选择合适的类权重有时是很复杂的事情。做简单的反向频率处理并不总是有用的。焦距损失法是有用的,但是即便这样,也还是会减少相同程度地减少每个类里面分类良好的示例的权重。因此,另一种平衡数据的方法是直接通过采样来实现。下图就是一个例子。
在上面的图像的左侧和右侧,我们的蓝色类比橙色类有更多的样本。在这种情况下,我们有两个预处理选项,它们可以帮助训练我们的机器学习模型。
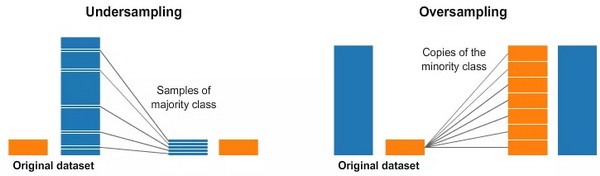
欠采样意味着我们将只从多数类中选择其中一些数据,而使用少数类所具有的示例数据。这个选择可以用来保持类的概率分布。这是很容易的!我们仅仅靠减少示例样本就平衡了我们的数据!
过采样意味着我们将给少数类创建数个副本,以便少数类和多数类相同的示例数量。副本的数量要达到使少数类对准确率的影响可以一直维持。我们只是在没有获得更多数据的情况下整理了我们的数据集!如果发现很难有效地设置类权重,那么抽样可以替代类平衡。
via:George Seif's blog
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

