从数据中心基础设施的视角来看 Facebook 机器学习的应用
2019-01-10 来源:raincent

据国外媒体报道,Facebook 的 20 亿用户中,绝大多数人不清楚 Facebook 有多少服务在多大程度上依靠人工智能来运作。更没多少人知道,在庞大的 Facebook 帝国,机器学习占有多大的分量。今天,我们翻译了 Hazelwood 等人撰写的文章,从数据中心基础设施的角度,来窥视在 Facebook 内部的机器学习应用的情况。希望这篇文章能够起到管中窥豹、抛砖引玉的作用。

这是一种奇妙的体验:机器学习几乎渗透到业务的每一个环节,从头到尾贯穿了整个堆栈。回顾过去十年来,软件系统在这方面已经发生了这么多根本性的变化,真让人感到惊讶啊!
在 Facebook,机器学习到底有多普及呢?
“在 Facebook,机器学习提供了驱动用户体验几乎所有方面的关键能力…… 机器学习广泛应用于几乎所有的服务。”
“Facebook 通过机器学习管道汇集了所有存储数据的大部分,随着时间的推移,这一比例还在不断增加,以提高模型的质量。”
“展望未来,Facebook 预计现有的和新增的服务应用的机器学习将会快速增长…… 随着时间的推移,大多数服务显示出利用更多用户数据的趋势…… 训练数据集有持续、有时是急剧增长的趋势。”
现代用户体验越来越受到机器学习模型的支持,而这些模型的质量直接取决于为其提供数据的数量和质量:“对于 Facebook 的许多机器学习模型来说,能否取得成功,要取决于广泛、高质量数据的可用性。” 数据(当然是相关数据)是现代公司能够拥有的最有价值的资产之一。
正如我们上个月看到的文章 Continuum:a platform for cost-aware low-latency continual learning(《Continuum:成本感知低延迟持续学习的平台》)所讲的那样,将最新数据纳入到模型中的延迟也非常重要。在这篇文章中有一段写得很好,作者研究了在一段时间内失去训练模型的能力以及必须满足陈旧模型的请求的影响。例如,社区诚信团队依靠经过频繁训练的模型来跟上对手,寻找试图绕过 Facebook 保护并向用户展示令人反感的内容的不断变化的方式。在这里,训练迭代需要几天的时间。更依赖于将最近的数据合并到模型中的是消息来源(News Feed)排名。“陈旧的消息来源模型对质量有可衡量的影响。” 如果我们看一看业务最核心的部分:广告排名模型,“我们就会了解到,利用陈旧的机器学习模型的影响,是以小时为单位来衡量的。换言之,对于这个模型来说,使用一天比使用一个小时要槽糕得多。” 该文章这段的结论之一是,训练工作负载的灾难恢复和高可用性非常重要。(另一个练习混沌工程的地方。)
为了有助于理解这种普遍影响,只需看看 Facebook 上使用的一些机器学习的例子即可。
在 Facebook 使用机器学习的例子
消息来源中的故事排名是通过机器学习模型完成的。
通过机器学习模型确定向给定用户显示哪些广告:“广告模型经过训练,以了解用户特征、用户背景、先前的交互和广告属性如何最能预测单击广告、访问网站和 / 或购买产品的可能性。”
各种各样的搜索引擎 (例如视频、照片、人物、事件等等) 都是由机器学习模型驱动的,而一个整体的分类器模型位于所有这些引擎之上,以决定对于任何给定的请求应该搜索哪些垂直领域。
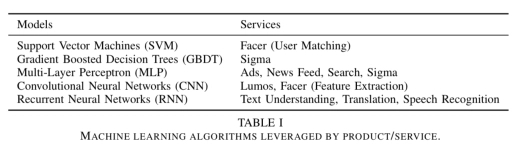
Facebook 的一般分类和异常检测框架 Sigma 用于许多内部应用程序,包括网站完整性、垃圾邮件检测、支付、注册、未授权员工访问、广告事件建议。Sigma“每天都有数百种不同的模型在生产中运行”。
Lumos 从图像中提取属性和嵌入。(我不确定 Lumos 和 Rosetta 的关系)
Facer 是 Facebook 的人脸检测和识别框架。
超过 45 种源语言和目标语言之间的翻译,由每种语言对特有的模型提供支持,目前支持大约 2000 种翻译方向。每天大约有 45 亿份翻译后的帖子。
语音识别模型将音频流转换成文本,为视频提供自动字幕。
而这些只是亮点……
除了上面提到的主要产品之外,更多的长尾服务还以各种形式利用机器学习。产品和服务的长尾达数百个。
AI 前线注:“长尾”(long-tail)这一概念是由 Chris Anderson 在 2004 年发表的《The Long Tail》一文中最早提出的,他通过对 Amazon、iTunes 等电子商务零售商的销售数据进行研究,发现了一种符合统计规律中大数定律的现象。这种现象恰如价值、品种而为坐标上的一条需求曲线,向代表 “品种” 的横轴尽头延伸,一直没有坠落至零点。这种曲线在统计学中被称作 “长尾分布”。因为相对头部来讲,它的尾部特别长,就好像拖着一条长长的尾巴。“长尾” 也是因此而得名的。
常用的模型有哪些?
Facebook 使用的主要机器学习算法包括逻辑回归、支持向量机、梯度提升决策树(gradient boosted decision trees)和 DNN。在 DNN 家族中,MLP 用于对结构化数据进行操作(如排序),CNN 用于空间任务(如图像处理),RNN/LSTM 用于序列处理(如语言处理)。
从研究到生产:PyTorch,Caffe2 和 FBLearner
Facebook 内部的 FBLearner 工具套件包括一个 feature store(特征存储库),它充当特征生成器的目录,可以用于训练和实时预测:“它相当于一个市场,利用它,多个团队可以共享和发现特征。”FBLearner Flow 基于工作流描述对模型进行训练,并内置了对实验管理的支持。预测器使用 Flow 中训练的模型来提供实时预测。
训练模型的频率远低于推理——时间尺度各不相同,但通常是几天左右。训练也需要相对较长的时间来完成——通常是几小时或几天。同时,根据产品的不同,在线推理阶段可能每天运行数万亿次,并且通常需要实时执行。在某些情况下,特别是在推荐系统方面,还以持续的方式在线进行额外的训练。
在研究和探索方面,Facebook 使用 PyTorch:“它的前端专注于灵活性、调试和动态神经网络,这使得快速实验成为可能。” 不过 PyTorch 并没有针对生产和移动部署进行优化,因此一旦开发出一个模型,它就会被转换为 Caffe2,这是 Facebook 用于训练和部署大规模机器学习模型的生产框架。
Facebook 并不是简单重写模型了事,而是积极构建 ONNX 工具链(Open Neural Network Exchange,开放神经网络交换格式),用于跨不同框架和库的深度学习模型的标准交换。
在 Facebook 内部,我们使用 ONNX 作为将研究模型从 PyTorch 环境转移到高性能生产环境的主要手段。
基础设施的影响
训练需要混合使用 CPU 和 GPU,而模型服务主要是由 CPU 完成的。对于训练来说,随着模型使用的数据量持续增长,数据源的局部性就会变得非常重要。用于机器学习训练的 GPU 的物理位置是有意多样化的,是为了能够提供弹性以及在丢失区域 / 数据中心时能够继续训练的能力。
对于复杂的机器学习应用(如广告和新闻来源排名),每个训练任务需要获取的数据量超过了数百 TB。
数据量也意味着分布式训练变得越来越重要。“这不仅是 Facebook 的一个活跃的研究领域,在一般人工智能研究领域中也是如此。” 在推理过程中,模型通常被设计成在一台机器上运行,不过 Facebook 的主要服务也在不断评估是否有必要开始扩展超出单台机器容量的模型。
除了数据量之外,还需要许多复杂的处理逻辑来清理和归一化数据,以实现高效传输和轻松学习。这对存储、网络和 cpu 提出了非常高的资源需求。数据(准备)工作负载和训练工作负载在不同的机器上保持分离。
这两个工作负载具有非常不同的特征。数据工作负载非常复杂、特殊、依赖于业务,而且变化很快。另一方面,训练工作量通常是有规律的、稳定的、高度优化的,而且更喜欢 “干净” 的环境。
硬件
摩尔定律(Moore’s law)可能已经失效了,但是,比较一下 Facebook 在 2015 年设计使用的 “Big Sur” GPU 服务器和 2017 年使用的 “Big Basin” GPU 服务器在这两年内所取得的进展还是很有意思的:
♦ 每 GPU 的单精度浮点运算从 7 万亿次到高达 15.7 万亿次。
♦ 高带宽内存提供 900 GB/s 的带宽(为 Big Sur 的 3.1 倍)。
♦ 内存从 12 GB 增加到 16 GB。
♦ 高带宽 NVLink 间 GPU 通信。
♦ 与 Big Sur 相比,在训练 ResNet-50 图像模型时,吞吐量提高了 300%。
未来的发展方向
机器学习工作负载的需求会影响到硬件选择。例如,计算绑定机器学习工作负载受益于更广泛的 SIMD 单元、专用卷积或矩阵乘法引擎以及专用协处理器。模型压缩、量化和高带宽内存等技术有助于在 SRAM 或 LLC 中保留模型,并在不执行时减轻影响。
为了减少将最新数据合并到模型中的延迟,需要进行分布式训练,而分布式训练反过来又 “要求对网络拓扑和调度进行仔细的协同设计,以有效地利用硬件,实现良好的训练速度和质量。”
解决这些和其他新出现的挑战仍然需要跨越机器学习算法、软件和硬件设计的各种努力。
原文链接:
https://blog.acolyer.org/2018/12/17/applied-machine-learning-at-facebook-a-datacenter-infrastructure-perspective/
作者:Hazelwood 等
译者:Sambodhi
标签: 电子商务 服务器 媒体 排名 搜索 搜索引擎 通信 网络
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

上一篇:2019年大数据发展趋势预测
