美国资深数据科学家畅聊:数据分析与北美电商
2019-02-22 来源:raincent

电商现在已经是无所不在了,可以说是贯穿于大家的吃穿住行,什么都和它离不开。电商可以被简单的定义为:Business model enabling a firm or individual to conduct businesses。这篇文章我们来讲数据科学与AI技术在电商中的运用。
数据科学,也就是数据驱动科学(data driven class),是一种跨科学的方法。通常它结合多种算法和系统领域,被使用于提供各种形式的数据支持和连接。

一次交易行为对于电商来说的第一步是Customer在电脑前浏览物品下单,放在购物车。然后是第二步的刷卡、买单,到之后的这个单被接收,刷卡成功,确认邮件的发送和接收,到最后的warehouse打包准备及发货。
整个流程会产生很多的流量数据(Traffic Data)。比如说用户的行为,包括Impression(看到的印象流量)、Click Though(点击的行为)、Session(花多少时间在看相应的物品)、Email Activity(邮件端的traffic),包括打开点击,订阅,或者取消订阅等等,这些都是流量数据。
相应的交易数据有这样几种:Order History(下单的记录,买卖过什么样的东西)、Membership Subscription(会员订阅,从什么时间开始、订阅多久、是什么样的会员)、等等。
最后还有个人相关的用户信息数据,分为Demographic和Geographic。Demographic是人口调查,比如用户的性别、年龄、还有收入情况,住在哪里、有没有买房、有没有车,这些都算人口普查数据。Geographic就是地理信息,常用住址是住在大城市,还是二三线城市,或者是在郊外,这些是地理信息。

同样的,每个顾客都会有自己的Traffic/Transaction Data,就是浏览的信息和下单交易的数据。在电商里有很多种不同的数据,数据科学AI技术就应用在这里,就是从数据里面提取出知识和一些有用的见解。
实例分析:三个电商应用AI的实例:
Amazon GO(今年年初亚马逊才正式开放的无人售货店)
Smart Speaker(现在已经比较流行的智能音响)
Netflix Artwork (做关于影片的用户推荐)
Amazon GO 是一家无人商店,国内像阿里巴巴也有开这种相应的无人商店,使用的是差不多的技术形态。Amazon Go目前只在西雅图开了一家试用店。进门是需要排队的,因为想去看的人太多。

像这一幅图展示的,这家店没有营业员在出门的时候结算。它主要的技术是Computer Vision做动态识别、用Deep learning做动作的一些行为判断、还有各种Sensor、Sensor Fusion进行会员身份和物品的探测。
进门之前顾客要下载一个Amazon GO的APP,登陆以后就可以通过Sensor把用户的形态、相关的信息、买过什么东西、是会员还是非会员等等信息都查到。扫了门口的二维码以后,用户就可以进入。进去以后天花板上到处都是摄像头,照片里没有体现,但是顾客的一举一动都是被完全记录下来的。
那么Computer Vision(动态识别技术)的技术是什么原理呢?它主要的技术核心是用卷积神经网络(Convolutional Neural Network)。

举一个简单的例子:一幅图片从最基础开始可以分成三个颜色:RGB(红绿蓝);有些时候你可能会有些图案,有些透明度:RGBA。每个RGB都会有相应的数值。卷积实际上是对每一层的颜色做了一个滤镜。
用3×3的滤镜,滤镜的意思是把图像的各个框框角角的特征抽取出来。像图中所描述的,它将3×3的滤镜从左到右规定一个Stride(步数)。从左到右再从上到下,全部扫出来以后,相应的图层就会简化成一个Convolved Feature,就是一个缩小的矩阵。那这种矩阵通常可以做卷积层(Convolved)。
套用滤镜做卷积,也可以简单直接地取它的最大值。这里的例子是2×2的滤镜,和两步的部署。每个2×2的框里就取最大的值,像左上角的框我们就取6,相应右上角的取8。每一个图层里面取最大的值。这种做法可以帮助减小整个图片,把图片的各种颜色的各种特征提取出来。
从这里看到,用不同的滤镜和不同的步数可以得到缩小化的矩阵图。然后可以使用相应的图层,做convolution和pooling,并放到不同的矩阵里。这样直接输出结果到下一层神经网络,就可以把图片里从各个角度、各个方向相应的特征都提取出来。

上图的例子就是卷积神经网络的功能:它把一幅静态的图片分成3个图层以后,每个图层做卷积和max pooling,然后提取图片最大的特征,再做几次的卷积和max pooling。卷积神经网络还可以做不同的结合来保证识别范围的广度。最后的输出结果是这个图里面是有狗还是有猫,还是有船和鸟。
每一个识别都带有一个概率值,概率值越高说明这个图片里有这个物品的概率就越大。极高的概率就可以确认这个图片里面有什么样的物品。
卷积神经网络是一个静态的图片的一个判断,但实际上Amazon GO商店里的顾客都是移动的。大家挑选商品的时候都是走来走去的,所以亚马逊必须要进一步的利用CNN卷积神经网络的动态识别。

动态识别算法近十年发展的很快。最初的Sliding Windows(一种滑动窗口的算法)的概念是:每一幅静态的图片里,定义一个像滤镜一样的窗口,在这个窗口从左到右,从上到下不断的扫描,每个窗口都会做一个判断,每个小窗口都有对应的图片,来判断这里面有没有想要的物品。上图是判断图片里有没有车。滑动窗体算法中的窗体是固定扫动,一直扫描到找到目标物体为止。比如这辆车的匹配度是零点九几,那么通过找出最高概率的窗口就可以确认这里确实是有一辆车。这个算法的缺点效率非常的低下。因为要把一幅大图分解成很多小图,并不断的扫描。这对计算能力来说的确是个挑战。
最近几年来比较流行的算法叫做YOLO,就是You Only Look Once(只扫一眼)。任意一幅图片或视频中某个时段的样片,YOLO可以很快的去判断这个图片里面的物体。YOLO主要的精神是把图片按照网格(grid)分析。通过在每个网格里判断物品的重心(Center),可以精确的定位物体在图片中的位置。以刚刚的车子作为例子,YOLO判断这些网格的重心在哪里。同样它也会判断小网格里面有没有目标物体,如果有的话就会提供一个很高的概率。
当把这些发现有车的小窗口全部合在一起,变成一个大的窗口,那就需要设一个相应的域值。当域值超过一定的量,就说明物品确实存在于此小窗口。把小窗口全部连接起来,就会得到大一点的图片。同样再通过CNN做一次判断,判断这是不是对概率有所提高,或者降低。这样就可以通过每个小图拼凑起来个完整的物品。
这里面还有很多复杂的地方。比如说,YOLO有可能会发现其他框也可以体现一个车,可以有很多的连接各种小的grid也可以得到一个比较完整的物体,这个时候就要判断哪一个框最能代表这个物品。
总而言之,YOLO再加上目前最火的算法GPU可以很快的把动态的图片提取出包含这个物品的小框,进而确定是什么样的物品。是人、还是商品、还是人和商品。这样的话,可以很快地确定这张图里面的顾客有没有拿东西。2014年Amazon就已经申请了相关的专利。
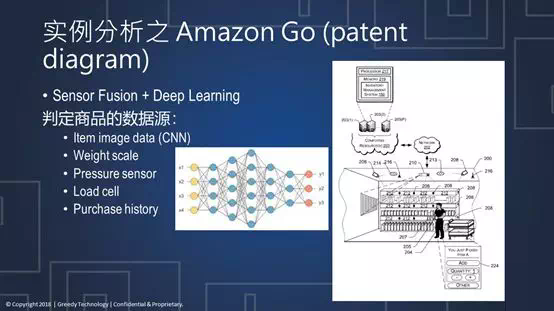
从图中可以看到:每一个物品都是有编号的;摄像头还有网络有相关的代码;录像机、摄像头全部都可以实时的处理。顾客每走到不同的货架旁边,从相应的货架取下一个物品,之后系统就知道这个物品是否还存在,它的重量会变化,它相应的图像也会有变动。
每个物品都有自己对应的编码,以此帮助系统来判断该物品是不是已经被拿走。这里可以判断商品的数据源有很多,首先从卷积神经网络得出来自图片的判定,还有来自重量和压力变化的判定,同时还可以结合用户过去的交易记录来判断是不是有可能的交易行为。
这里也可以用到DeepLearning(深度学习),作为input可以判断出用户是否有购买能力,从而做出相应的判断。
下一个实例是SmartSpeaker。
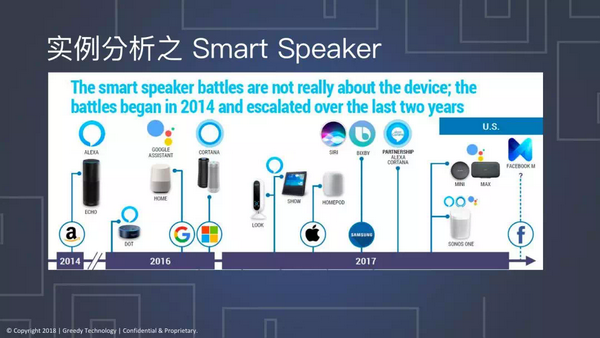
从2014年开始,Amazon就投入了大量的资金研发Alexa这个智能音箱的产品。紧跟着大家发现这个市场特别的好,Google也推出了Google assistant,微软也是在2016年推出了音箱Cortana。到去年为止,亚马逊又提出升级版本,推出了Show还有Look这种带摄像头的产品。苹果也推出了自家的智能音箱Homepod,今年会推出它的更新版,和Siri联系在一起。三星也是相应的推出Bixby,广告上也经常在提到。
智能音箱是非常火爆的产品,各大电商技术巨头都推出相应产品,帮助大家在网上下单,买卖东西。Amazon Echo这个最先驱的产品,或者说从Echo开始智能音箱才打开了市场。

Echo现在的功能已经非常的强大了,图像化的它可以连上手机的各种APP,听音乐、听电台、听新闻、看电视、叫车,放在家里可以用来看Amazon fireTV,同时智能家电像温度开关,还有家里的电灯开关,都可以通过智能音箱去控制。
Echo主要的技术背景就是语音识别和语义分析。语音识别就是通过不管是英语还是中文,还是其他阿拉伯语、日本语都可以让智能音箱能了解到大家想要做什么样的事情。

语音识别的技术近几年也是发展迅猛。最初的语音识别就是把每个语音波段提取相应的音素(Phoneme)并提取特征。就像拼音的元音、辅音,一些比较有代表性的发音都是由音素组成。把这些元素提取出来,拼凑成相应的字,或者词组。这是刚开始的语音识别的比较工程化的技术,现在已经发展到用RNN(递归神经网络)。
递归神经网络不同于传统的神经网络,它是有递归性的。意思就是说每一个神经元(见上图)是互相连接的。上一层的a(激活函数)处理完的输出可以直接输出到下一个函数,这样不断的迭代。同时每一个相应的输入,不同的单词、词组都会分别输入到每个神经元里面,但是这些神经元又是跟之前的神经元相连。更复杂一点的网络可以从正方向相连,也可以从反方向互相联系。
最后训练成功的这个网络里每个神经元都会输出Y1Y2这样的值。如果需要提取名字的话像“Teddy bear”输出可以这样表示:0011000。更复杂的情况里Y可以变成一整个向量性的输出。在一个词库里面,比如“Teddy”对应的值为1,词库里面其他不相关的词就会判断为0。
当递归神经网络判断出来某个词在相对应的阶段的语音接近于对应的单词,它直接跳过音素这种比较传统的步骤,直接通过整个语音的长度和广度判断出这段声音代表的什么意思。这个就是语音识别的大概的工作原理。
有了语音识别,识别出的相应的文字就可以做NLP(自然语言分析),也是语义分析。

语义分析也是很热门的学科,可以做各种各样的事情,比如说最常见的:
词频统计:通过公式计算词频在某个文件、某个文档里面出现多少次,或是通过统计某篇文章或者整个文库里边该词出现的频率做一个层级,就可以算出它正交化的词频统计。有了这个相关的数据可以作为数据输入。
NER(Name Entity Recognition):是专门做名字、名词相关的物品的一个识别。
POS(Part Of Speech,词性解析):像中文的主谓宾是主语,在英语里边就是形容词、名词、代名词。
N-Gram(组合词频):比如Cat就是一个单词;Running Cat,就是一个词组,它是有两个单词进行,就是2-gram,N-gram就是把这些高频组合的词去挖掘出来。
Word embedding:把各个词,按照它们的类别进行分类。比如Man、Woman可以按照性别等等进行分类,可以把它作为一个相关性的向量展开,这就是单词嵌入,每个词就赋予了更深的意义。
有了以上的这些就可以做进一步的分析。比如情绪分析,喜欢还是不喜欢,正面的色彩还是负面的色彩。像一些打分系统,就是用情绪分析来做。
也可以使用Word Embedding继续做GloVe/Word2Vec。把词展开到对应的向量空间,从而可以判断它在整个句子的成分;或者通过联系上下文来判断该词在一段内容里表示的具体意思,或者对将要出现的下文做判断预测。
同样还可以开发聊天机器人,有了这些NLP的手段可以去跟真人聊天,或者是解决一些简单的与真人互动的问题。比如开灯关灯、开电视,从语音分析里面提取想要的重点,达到想要完成的愿望。
最后一个实例是Netflix Artwork。这也是很有意思的一个实例。Netflix用上了数据科学和AI技术。

对不同的人群来说,这些海报应该怎么样宣传?这里就可以把影片的各个情节都提取相应的插图作为海报,喜欢恐怖片的朋友可能会更爱看点带血腥的,或者带火焰的;喜欢小朋友的观众可能看到有很多小孩的海报;还有的人喜欢某一个明星,那么他个人的海报对于作为粉丝的你来说更容易感兴趣。因此这里需要一个有效的推荐引擎来给不同的用户推荐,来让用户看了这个宣传海报以后更有可能点击播放。
传统的方法就是首先收集数据,建好模,做好各种A/B testing,然后把这个Model正式出品,执行在前端。这个方法会耗时很久,短暂来说可能也要花上几星期,长一点可能是数月。在这段时间内,可能用户的喜好就会发生很大的变化。可能在这个模型推出以后跟之前预测的用户在这个时间点的品位又不一样,模型反而不清晰,产生很大的分歧。
Netflix最新的算法是一种强化学习的手段叫Reinforcement Learning(RL)。它的主要特点就是可以快速的迭代,持续的优化。
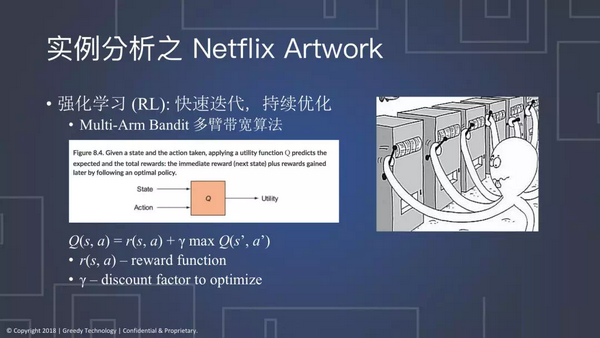
它的核心思想简单来说是就是多臂带宽(Multi-Arm Bandit)的算法。在RL里面定义一个state,通过rewardfunction Q,就会得出reword是多少。像这个章鱼一样,每执行不同的步骤就会有不同的效果,每一台都像赌博机一样,启动了赌博机A和赌博机C,可能会输或者都会赢,value都不一样。
上图中的公式在这里就定义了:功效应该等于reward加上γ乘以未来的功效。假如γ是0,就不考虑未来期望值,上一次得到的reward是多少,就一直按照这个方式去进行,不会去考虑其他的可能性。
现在看来要达到最好的办法,Netflix采用了一个叫做Contextual Bandit(环境带宽算法)。
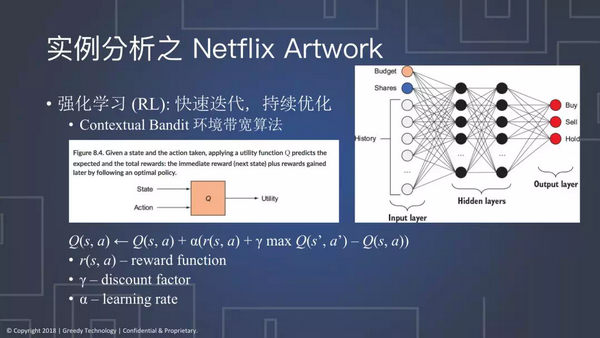
环境带宽算法实际上是来定义用户是一种环境变量,因为每一个用户都有不同的背景和喜好,Netflix就把刚才的公式复杂化,加入了learning rate。意思就是说顾客未来的这个Q’,需要通过建模来达到通预测的功效。
加入了learning rate之后,α如果等于1,就可以去掉两边,换成多臂带宽算法;如果模型不需要太考虑未来,那就用刚才简单优化算法,按照每一次的结果,来选每次得到最高效用的那个模型;如果想让RL模型去学习更多、探索更多未来的未知的情况,就假设α不是1,这个时候Q’ 的作用就能够体现出来。
Q’用一个类似于深度神经网络这样的模型来做预测,例如把数以百万的客户的浏览记录,个人背景,还有年龄性别这些相应的信息作为输入,用这样的方法对这些信息做一个深度学习的Training
另外一个简单的例子是股市交易,输入信息是budget和shares,加上交易的记录,可以做出一个深度学习的网络。它可以做出需要买还是卖还是hold的决策。最后可以用Q’作为未来回报的预测。有了整套系统之后,只要知道了近期的return,就可以预测的未来的Return。当然,这个Q’太初级,可能要在不断的迭代之后才可以正式地被使用。通过比刚才提到的单一的建模考虑到更多的变量,它会更加快速的迭代。
电商行业的新宠,就是深度神经网络、卷积神经网络以及递归神经网络,以及强化学习。在未来的电商行业里,通过积极的发展,它们运用的方向是非常广阔的。像行为预测,智能图像、还有语音识别、个性化推荐,在电商各个环节都是必不可少的。未来应该会很快的看到这些AI的技术运用于顾客的体验和买卖活动当中。
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

