�����ѧ�����ݿ��ӻ���������һ��4Сʱ��Kaggle�γ�
2019-04-29 ��Դ��raincent

��Ҫ����Ư���Ŀ��ӻ�ͼ����?Kaggle ƽ̨����һ�����ݿ��ӻ����γ̣���ʱ���� 4 Сʱ������ѧϰ��!
�γ̵�ַ��https://www.kaggle.com/learn/data-visualization-from-non-coder-to-coder

�γ̼��
�ÿγ�Ϊ��ѿγ̣������� 15 �ڿΣ�ʱ�� 4 Сʱ�������� Alexis Cook ���Ͷ��ڶſ˴�ѧ����Ъ����ѧ�Ͳ��ʴ�ѧ���ڶ������ѧϰƽ̨(�� Udacity �� DataCamp)�������ݿ�ѧ��
���ſγ�ʹ�õ����ݿ��ӻ������� Seaborn������ѧԱ��Ҫ���˽����д Python ���롣����û���κα�̾������Ҳ����ͨ���ÿγ�ѧ�����ݿ��ӻ�������γ�����������Data Visualization: from Non-Coder to Coder�������ݿ��ӻ���֤��̵�������
�ÿγ̰��� 15 �ڿΣ���Ϊ�γ̽������ϰ���࣬ÿһ�ý���κ���һ����ϰ�Σ���ѧԱ��ʱ���̺�Ӧ����ѧ֪ʶ��
�γ��漰�����ݿ��ӻ����� Seaborn �Ľ��ܣ���λ�������ͼ����״ͼ����ͼ��ɢ��ͼ���ֲ�ͼ�����ѡ��ͼ�����ͺ��Զ�����ʽ���γ���ĩ��Ŀ���Լ���ξ�һ����Ϊ�Լ�����Ŀ���� notebook���γ�Ŀ¼������ʾ��


���棬���ǽ�ѡȡ����һ�ڿ�——ɢ��ͼ(Scatter Plots)���м��ܡ�
��δ�����ɢ��ͼ
���ȥ�����������ڿεĴ������ݣ�����ͼ��ʾ����ɢ��ͼ��������������֣�

btw���ۼ�Ķ��ᷢ�֣����滹��һ�� comments ��顣���ԣ��ÿγ̻��ǽ���ʽ���أ�����Ա�ѧϰ�����ۡ�
ͨ����ڿΣ��㽫ѧϰ��δ�������ɢ��ͼ��
���� notebook
���ȣ�����Ҫ���ñ��뻷����
���룺
import pandas as pdimport matplotlib.pyplot as plt%matplotlib inlineimport seaborn as snsprint("Setup Complete")
�����
Setup Complete
���غͼ������
���ǽ�ʹ��һ�����շ���(�ϳ�)���ݼ���Ŀ�����˽�Ϊʲô��Щ�ͻ���Ҫ��������֧���ø��ࡣ���ݼ���ַ��https://www.kaggle.com/mirichoi0218/insurance/home

���룺
# Path of the file to readinsurance_filepath = "../input/insurance.csv"# Read the file into a variable insurance_datainsurance_data = pd.read_csv(insurance_filepath)
��ӡǰ���У��Լ�����ݼ��Ƿ���ȷ���ء�
���룺
insurance_data.head()
�����

ɢ��ͼ
Ϊ�˴�����ɢ��ͼ������ʹ�� sns.scatterplot ���ָ������ֵ��
ˮƽ x ��(x=insurance_data['bmi'])
��ֱ y ��(y=insurance_data['charges'])
���룺
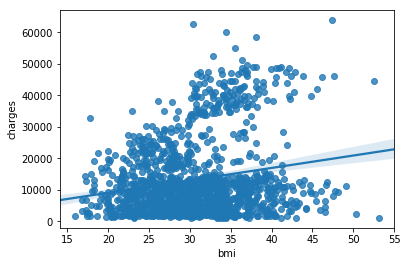
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'])
�����

�����ɢ��ͼ������������ָ��(BMI)�ͱ��շ���������صģ�BMI ָ�����ߵĿͻ�ͨ����Ҫ֧������ı��շ��á�(��Ҳ�������⣬�� BMI ָ��ͨ����ζ�Ÿ��ߵ����Բ����ա�)
���Ҫ�ٴμ�����ֹ�ϵ��ǿ�ȣ��������Ҫ����һ���ع��ߣ�������������ݵ��ߡ�����ͨ�������������Ϊ sns.regplot ��ʵ����һ�㡣
���룺
sns.regplot(x=insurance_data['bmi'], y=insurance_data['charges'])
�����
/opt/conda/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result. return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
��ɫɢ��ͼ
���ǿ���ʹ��ɢ��ͼչʾ��������֮��Ĺ�ϵ��ʵ�ַ�ʽ���Ǹ����ݵ���ɫ��
���磬Ϊ���˽����̶� BMI �ͱ��շ���֮���ϵ��Ӱ�죬���ǿ��Ը����ݵ� 'smoker' ������ɫ���룬Ȼ��'bmi'��'charges'��Ϊ�����ᡣ
���룺
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'], hue=insurance_data['smoker'])
�����

����ɢ��ͼչʾ�˲����̵������� BMI ָ�������ӱ��շ��û��������ӣ������̵��˵ı��շ���Ҫ���ӵö�öࡣ
Ҫ���һ����ȷ��һ��ʵ�����ǿ���ʹ�� sns.lmplot �������������ع��ߣ��ֱ��Ӧ�����ߺͲ������ߡ�(��ῴ�������ߵĻع��߸��Ӷ��͡�)
���룺
sns.lmplot(x="bmi", y="charges", hue="smoker", data=insurance_data)
�����
/opt/conda/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result. return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval

sns.lmplot ����������������һЩ��ͬ��
����û���� x=insurance_data['bmi'] ��ѡ�� insurance_data �е�'bmi'�У��������� x="bmi"��ָ���е����ơ�
���Ƶأ�y="charges" �� hue="smoker"Ҳ�����е����ơ�
����ʹ�� data=insurance_data ��ָ�����ݼ���
�����һ��ͼҪѧ������ͨ��ʹ��ɢ��ͼ��ʾ������������(��"bmi"�� "charges")֮��Ĺ�ϵ�����ǣ����ǿ��Ե���ɢ��ͼ����ƣ�������ijһ��������(��"smoker")�����ǽ�����ͼ�����ͳ������ɢ��ͼ(categorical scatter plot)����ʹ�� sns.swarmplot �������
���룺
sns.swarmplot(x=insurance_data['smoker'], y=insurance_data['charges'])
�����

����֮�⣬���ͼ������չʾ�ˣ�
�����̵��˱ȳ��̵���ƽ��֧���ı��շ��ø���;
֧����ౣ�շ��õĿͻ��dz��̵��ˣ���֧�����ٵĿͻ��Dz����̵��ˡ�
��ǩ�� [db:TAGG]
��Ȩ��������վ���²��������磬������Ȩ������ϵ��west999com@outlook.com
�ر�ע�⣺��վ����ת���������۲�������վ�۵㣡
��վ���ṩ��ͼƬ���زģ���Ȩ��ԭ�������У�����ʹ�ã�����ԭ������ϵ��

