一文读懂机器学习中的贝叶斯统计学
2019-05-06 来源:raincent

你有没有问过自己,以前从未发生过的事件发生的概率是多少?
在本文中,我们将深入探讨贝叶斯统计的神秘世界以及它的一些原则,Bernstein-von Mises定理和Cromwell规则,以及用它们分析现实世界的机器学习问题。
“贝叶斯统计之所以困难,是因为思考是困难的”
- Don Berry

如果你想深入了解贝叶斯统计背后的数学原理,那么这篇文章不是你要找的(尽管未来我将发表关于这个的文章)。本文主要是给刚刚接触这个概念的人介绍贝叶斯方法。
想象一下,你正在设计一座核电站。你的任务是使用数据来确定工厂是否正常运转。这看起来似乎是一个相对简单的任务,直到你意识到你实际上没有任何关于核电站发生核泄露时的数据。你怎么能预测这样的事情呢?
如果你是一个精明的机器学习专家,你可能会提出某种无监督的方法,如(受限制的)波耳兹曼机,它能够了解“正常”的发电厂是什么样的,从而知道什么时候发生了错误(事实上,这是正人们预测核电厂正常运行情况的一种方式)。
然而,如果我们从更广泛的意义上考虑这个问题,当我们没有什么负面例子可以比较时,我们该怎么办?出现这种情况有几个原因:
低概率情景:该事件发生的概率如此之低,以至于在(有限的)样本数据中根本没有观察到该事件的发生。
数据稀疏情景:观察已经发生,但很少。
灾难情景:失败的结果将是灾难性的,它只能发生一次,例如,太阳的毁灭。
传统的统计方法不适用于这类问题,我们需要不同的方法。
一个更普遍的问题是,我们如何处理极低(但严格非零)或极高(接近1但严格非1)的概率?让我们首先看一下由数学家Pierre-Simon Laplace提出的为研究著名问题而制定的一些规则。
日出问题
想象一下,有一天早上你醒来,太阳决定休息一天。这不仅(最有可能地)会毁了你的一天,打乱你的生物钟,还会直接改变你对太阳的感觉。你可能会更有可能预测也许第二天太阳也不会升起。或者,如果太阳刚刚度过了糟糕的一天,然后第二天又回来了,那么你对太阳会再休息一天的期望就会比之前高很多。
这里发生了什么?基于新的证据,我们改变了对事件发生概率的看法。这是所有贝叶斯统计的关键,并使用一个称为贝叶斯规则的方程来正式描述。
贝叶斯规则
贝叶斯规则告诉我们,我们必须从某一事件发生的固有概率开始(事前)。我们称之为先验概率。逐渐地,当我们获得新的观察结果和证据时,我们会在这些证据和判断我们当前情况的可能性的基础上更新我们的信念。这种更新的信念被称为后验概率(事后)。
回到我们的日出问题,每天我们都观察到太阳升起,并且每一次太阳升起的时候,我们都更确定它会在第二天再次升起。然而,如果有一天我们发现太阳没有升起,这将极大地影响我们基于新证据的后验概率。
这可以用下面的数学形式来表示,乍一看令人生畏,但可以抽象出来:我们更新的信念是基于我们最初的信念和基于我们当前的信念(可能性)的新证据。可能性是指我拥有的新证据,我的信念正确的可能性有多大?如果我相信明天太阳不升起的概率是一百万分之一,然后它发生了,我的信念(我的模型)是错的可能性会非常高,然后后验概率将被更新来预测它更有可能会再次发生。
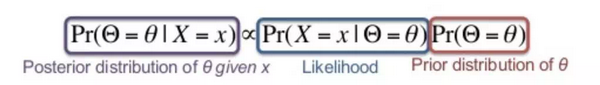
贝叶斯理论
这是一个非常棒的想法,它存在于许多不同的地方,尤其是涉及到人类和他们的信仰时。例如,假设你的朋友告诉你,你最喜欢的一位名人去世了。一开始,你可能会感到沮丧,并且有点怀疑。随着你的一天,你读报纸,它告诉你,这位名人去世了,这种信念将进一步加强。也许你会在电视上看到他们家人哀悼的新闻,你的信念会更加坚定。然而,如果你看到电视上被采访的人说他死亡的谣言正在被扩散,你对朋友告诉你的话的可信度就会被降低。
这是科学的一个重要方面,理论通过实验和模拟得到证实,做这些实验和验证这些理论的人越多,这些理论就越强大和可信。然而,比如有宗教信仰的人可能认为他们不需要经验证据(至少是同类的)来相信某些东西,我们称之为信仰。
有趣的是,在我们日常生活中如此普遍的事情对统计学和机器学习如此重要,但它确实如此,我们将讨论原因。然而,首先我们需要研究一些贝叶斯定理中出现的概率非常低的问题。
Cromwell 规则
Oliver Cromwell是英国历史上的一位杰出人物,1658年在苏格兰国教大会上他曾说过一句名言:
“我恳求你,在基督的内心中,认为你可能会被误解。“
这个句子的使用导致了Dennis Lindley 定义的Cromwell规则,该规则提出了这样的想法:如果一个人由等于零(我知道这些事件不是真的)或一(我知道这些事件是正确的)的先验概率开始,那无论向你展示什么证据,你的信念将不会被动摇。
这向我们展示了在观察可以以经验观察的事物时绝对主义观点的危险性。如果我坚信自己是正确的,那么任何人说的或做的都不能使我信服。这是无知的高度,而不是我们想要融入机器学习模型的东西。如果我们回头看贝叶斯定理我们就能明白为什么会这样,如果先验概率是0,那么乘以任何数之后后验概率仍然是0。
原则上(见Cromwell规则),任何可能性都不应将其概率设为零,因为在现实世界中,任何事情都不应被严格假定为不可能(尽管它可能是不可能的)——即使与所有观察结果和当前理论相悖。
神经网络就是一个理想的例子。当你初始化一个神经网络时,你的节点以一些固有值开始。如果将这些节点的权值都赋值为零,则节点将无法自行更新,因为梯度下降算法的所有迭代都将乘以零。相反,执行随机初始化(通常对用户不可见)通常可以防止出现这样的问题。
贝叶斯定理的另一个有趣的性质是源自当我们观察无穷次观察之后会发生什么,通常被称为Bernstein-von Mises定理。
Bernstein-von Mises定理
简而言之,Bernstein-von Mises定理告诉我们,当我们获得更多的数据时,我们的后验估计将渐进地独立于我们最初(先前)的信念——当然,前提是它遵循Cromwell规则。这在某种程度上类似于频率统计中的律数定律,它告诉我们,当我们获得越来越多的数据时,样本的均值最终将等于总体的均值。
那么贝叶斯统计与普通统计之间的最大区别是什么?为什么机器学习专家和数据科学家需要贝叶斯统计?
贝叶斯统计与频率统计
对于那些不知道贝叶斯和频率论是什么的人,让我详细说明一下。频率论方法是从频率的角度看数据。例如,假设我有一枚两面都是正面的偏置硬币。我抛10次硬币,得到10次正面。如果我取所有抛硬币的平均结果,得到1,表示下一次抛硬币正面的概率是100%,反面的概率是0%,这是一种频率论的思维方式。
现在用贝叶斯的观点。一开始我的先验概率是0.5,因为我假设硬币是均匀的。但是,不同的是我如何选择更新我的概率的方式。每次抛完硬币后,我都会看看我的下一个观察结果在我目前的信念(我有一枚均匀的硬币)下出现的可能性有多大。渐进的,当我抛到更多的正面,我的概率会趋向于1,但它永远不会明确地等于1。
贝叶斯方法和频率方法的根本区别在于随机性存在的位置。在频率论领域内,数据被认为是随机的,参数(如均值、方差)是固定的。在贝叶斯领域中,参数是随机的,数据是固定的。
我现在非常想强调一点。
它不被称为贝叶斯(Bayesian),因为你使用的是贝叶斯定理(这在频率论的观点中也很常用)。
它被称为贝叶斯(Bayesian),因为方程中的项有不同的潜在含义。从理论的差异来讲,最终你会得到一个非常有意义的实际区别:虽然之前仅有一个参数作为估计器的结果(数据是随机的,参数是固定的),现在你有一个分布参数(参数是随机的,数据是固定的),所以你需要集成它们以获得在数据上的分布。这是贝叶斯统计背后的数学变得比普通统计更混乱的原因之一,我们必须使用马尔可夫链Monte Carlo方法对分布进行抽样,以估计难以处理的积分的值。其他巧妙的技巧,如无意识统计学家定律(多么伟大的名字,对吧?)又名LOTUS,可以在数学方面提供帮助。
那么哪种方法更好呢?
这些方法本质上是同一枚硬币的两面(双关语),它们通常会给出相同的结果,但实现方法略有不同。不是一个比另一个好。事实上,我在哈佛的课堂上甚至有教授经常争论哪个更好。普遍的共识是,“这取决于问题本身”,如果你能把它当成一个共识的话。就我个人而言,我发现贝叶斯方法更直观,但其背后的数学要比传统的频率方法复杂得多。
现在你(希望)已经理解了其中的区别,也许下面的笑话会让你发笑。

贝叶斯与频率论的笑话
什么时候应该使用贝叶斯统计?
贝叶斯统计包含了一类可以用于机器学习的特定模型。通常,人们基于一个或多个原因使用贝叶斯模型,例如:
拥有相对较少的数据点
对事物如何运作有强烈的直觉(来自已有的观察/模型)
具有高度不确定性,或强烈需要量化特定模型或模型比较的不确定性水平
想要声明关于替代假设的可能性,而不是简单地接受或拒绝零假设
看了这个清单,你可能会认为人们总是想在机器学习中使用贝叶斯方法。然而,事实并非如此,我怀疑贝叶斯机器学习方法的相对薄弱是因为:
大多数机器学习都是在“大数据”的背景下完成的,而贝叶斯模型的特征——先验——实际上并没有发挥多大作用。
在贝叶斯模型中采样后验分布计算量大且速度慢。
我们可以清楚地看到,频率分析和贝叶斯方法之间存在着许多协同作用,尤其是在当今世界,大数据和预测分析已经变得如此突出。我们为各种系统提供了大量的数据,我们可以不断地对系统进行数据驱动的推断,并随着越来越多的数据可用而不断更新它们。由于贝叶斯统计为“知识”的更新提供了一个框架,实际上它在机器学习中被大量使用。
一些机器学习技术,如高斯过程和简单线性回归,都有贝叶斯和非贝叶斯版本。也有纯频率的算法(如支持向量机、随机森林)和纯贝叶斯的算法(如变分推理、期望最大化)。学习什么时候使用这些工具,以及为什么使用这些工具,可以让你成为一名真正的数据科学家。
你是贝叶斯主义者还是频率方法主义者?
就我个人而言,我并不属于任一阵营,这是因为有时我在一个拥有数千个特性的数据集上使用统计数据/机器学习,而我对这些特性一无所知。因此,我没有先验的信念,贝叶斯推理似乎是不合适的。然而,有时我处理很少的特征并且我对它们很了解,我想把它加入我的模型-在这种情况下,贝叶斯方法将给我更多我相信的确定的区间/结果。
我应该去哪里学习更多关于贝叶斯统计的知识?
有几个很棒的在线课程深入研究机器学习的贝叶斯统计。我推荐的最好的资源是我在哈佛上的AM207课程:高级科学计算(随机优化方法,用于推理和数据分析的蒙特卡罗方法)。你可以在这里找到所有的课程资源,笔记,甚至Jupyter笔记。
这里还有一个很棒的视频,讲的是贝叶斯域和频率之间的转换(在视频的11分钟处)。
视频链接:
https://www.youtube.com/watch?time_continue=674&v=kLmzxmRcUTo
如果你想成为一名真正伟大的数据科学家,我建议你牢牢掌握贝叶斯统计以及它如何被用来解决问题。这是一个艰难的过程,也是一个陡峭的学习曲线,但这是一个让你从其他数据科学家中脱颖而出的好方法。在与同事进行数据科学访谈的讨论中,贝叶斯建模经常出现,所以请记住这一点!
原文标题:
Will the Sun Rise Tomorrow? Introduction to Bayesian Statistics for Machine Learning
原文链接:
https://towardsdatascience.com/will-the-sun-rise-tomorrow-introduction-to-bayesian-statistics-for-machine-learning-6324dfceac2e
标签: [db:TAGG]
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

