Apache Spark 实现可扩展日志分析,挖掘系统最大潜力
2019-05-06 来源:raincent

几乎每个大大小小的组织都有多个系统和基础设施日复一日地运行。为了有效地保持业务运行,组织需要知道他们的基础设施是否发挥了最大潜力。这包括分析系统和应用程序日志,甚至可能对日志数据应用预测分析。

引言
现如今,在利用分析的案例中,日志分析是最流行、最有效的企业案例之一。几乎每个大大小小的组织都有多个系统和基础设施日复一日地运行。为了有效地保持业务运行,组织需要知道他们的基础设施是否发挥了最大潜力。这包括分析系统和应用程序日志,甚至可能对日志数据应用预测分析。根据运行在上面的组织基础设施和应用程序的类型,日志数据的数量通常是巨大的。以前,由于计算资源限制,我们只能在一台机器上分析数据样本,这种日子已经一去不复返了。
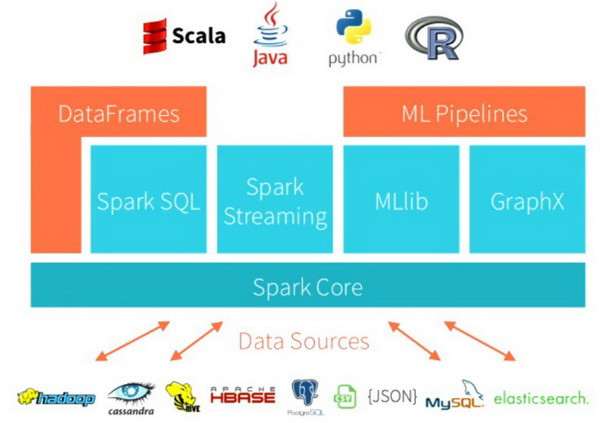
在大数据、更好的分布式计算、大数据处理和 Spark 等开源分析框架的支持下,我们每天可以对潜在的数百万乃至数十亿条日志消息执行可扩展的日志分析。本教程面向案例研究,目的是采用一种实际操作的方法,展示如何利用 Spark 在半结构化日志数据上执行大规模日志分析。如果你对使用 Spark 的可扩展 SQL 感兴趣,请查阅Spark 上的大规模 SQL。
本文将主要探讨以下几个主题。
主要目标——NASA 日志分析
设置依赖项
加载和查看 NASA 日志
数据清理
Web 日志数据分析
尽管有很多优秀的开源框架和工具可以用于日志分析,包括 ElasticSearch,但本教程的目的是展示如何利用 Spark 对日志进行大规模分析。在现实世界中,你可以在分析日志数据时自由选择你的工具箱。让我们开始吧!
主要目标——NASA 日志分析
正如我们前面提到的,Apache Spark 是一个优秀的、理想的开源框架,用于结构化和非结构化数据清理、分析和建模——大规模的!在本教程中,我们的主要目标是关注业界最流行的案例研究之一——日志分析。通常,服务器日志是企业中非常常见的数据源,是常常包含可操作见解和信息的金矿。企业中的日志数据有许多来源,比如 Web、客户端和计算服务器、应用程序、用户生成的内容、平面文件。它们可以用于监视服务器、改进业务和客户智能、构建推荐系统、欺诈检测等等。

Spark 让你能以很低的成本将日志转储并存储在磁盘上的文件中,同时提供丰富的 API 来执行大规模的数据分析。这个实践案例研究将向你展示如何在 NASA 的实际生产日志上使用 Apache Spark,并学习数据清理和探索性数据分析中基本但强大的技术。在本案例研究中,我们将分析来自佛罗里达州 NASA 肯尼迪航天中心 Web 服务器的日志数据集。完整的数据集可以在这里免费下载。
这两个数据集包含了佛罗里达州 NASA 肯尼迪航天中心 WWW 服务器上两个月内的所有 HTTP 请求。你可以到网站下载以下文件(或直接点击以下链接)。
7 月 1 日到 7 月 31 日,ASCII 格式,gzip 压缩 20.7MB,未压缩 205.2MB:ftp://ita.ee.lbl.gov/traces/NASA_access_log_Jul95.gz
8 月 4 日到 8 月 31 日,ASCII 格式,gzip 压缩 21.8MB,未压缩 167.8MB:ftp://ita.ee.lbl.gov/traces/NASA_access_log_Aug95.gz
请确保这两个文件与包含教程的笔记本在同一个目录中,该教程可以从我的 GitHub上找到。
设置依赖项
第一步是确保你能够访问 Spark 会话和集群。为此,你可以使用自己的本地设置或基于云的设置。通常,现在大多数云平台都会提供一个 Spark 集群,你还可以选择免费的Databricks 社区版。本教程假设你已经安装了 Spark,因此我们不会花费额外的时间从头配置或设置 Spark。
通常,在启动你的 jupyter 笔记本服务器时,预配置的 Spark 设置已经预先加载了必要的环境变量或依赖项。在我的例子中,我可以在笔记本中使用以下命令来检查它们。
spark

这说明我的集群目前正在运行 Spark 2.4.0。我们还可以使用以下代码检查sqlContext是否存在。
sqlContext
#Output:
现在,如果你没有预先配置这些变量并得到一个错误,你可以加载它们并使用以下代码配置它们。除此之外,我们还加载了一些用于处理数据流和正则表达式的其他库。
# configure spark variables
from pyspark.context import SparkContext
from pyspark.sql.context import SQLContext
from pyspark.sql.session import SparkSession
sc = SparkContext()
sqlContext = SQLContext(sc)
spark = SparkSession(sc)
# load up other dependencies
import re
import pandas as pd
使用正则表达式将是解析日志文件的主要方面之一。正则表达式是一种非常强大的模式匹配技术,可以用于提取和发现半结构化和非结构化数据中的模式。

正则表达式非常有效、非常强大,但有时也会让人不知所措或感到困惑。不过不用担心,通过更多的练习,你可以真正充分地利用它的潜力。下面的示例展示了在 Python 中使用正则表达式的一种方法。
m = re.finditer(r'.*?(spark).*?', "I'm searching for a spark in PySpark", re.I)
for match in m:
print(match, match.start(), match.end())
<_sre.SRE_Match object; span=(0, 25), match=“I’m searching for a spark”> 0 25
<_sre.SRE_Match object; span=(25, 36), match=’ in PySpark’> 25 36
让我们进入下一部分的分析。
加载和查看 NASA 日志数据集
假设我们的数据存储在下面提到的路径中(以平面文件的形式),让我们将其加载到一个 DataFrame 中。我们将分步骤来做。下面的代码获取磁盘中的日志数据文件名。
import glob
raw_data_files = glob.glob('*.gz')
raw_data_files
[‘NASA_access_log_Jul95.gz’, ‘NASA_access_log_Aug95.gz’]
现在,我们将使用sqlContext.read.text()或spark.read.text()来读取文本文件。这将生成一个 DataFrame,其中只有一个名为value的字符串列。
base_df = spark.read.text(raw_data_files)
base_df.printSchema()
root
|-- value: string (nullable = true)
这使我们能够看到日志数据的模式,它看起来很像我们将很快要检查的文本数据。你可以使用以下代码查看保存日志数据的数据结构类型。
type(base_df)
#Output:
pyspark.sql.dataframe.DataFrame
我们将在整个教程中使用 Spark DataFrame。但是,如果需要,还可以将数据 DataFrame 转换为 RDD,即 Spark 的原始数据结构(弹性分布式数据集)。
复制代码base_df_rdd = base_df.rddtype(base_df_rdd)
#Output
pyspark.rdd.RDD
现在让我们看一下 DataFrame 中实际的日志数据。
base_df.show(10, truncate=False)
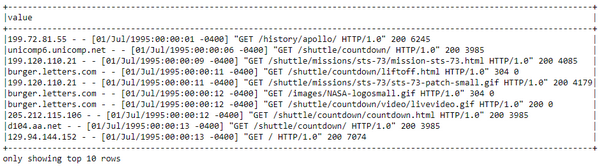
这看起来绝对像标准的服务器日志数据,它是半结构化的,在使用它们之前,我们肯定需要做一些数据处理和清理。请记住,从 RDD 访问数据略有不同,如下所示。
base_df_rdd.take(10)
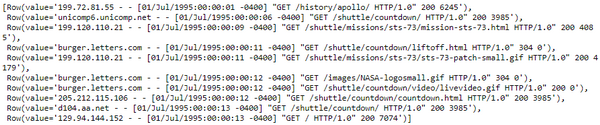
现在我们已经加载并查看了日志数据,让我们对其进行处理和清理。
标签: [db:TAGG]
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

