10 ����Ϊ��֪�� SQL ����
2019-09-19 ��Դ��raincent


�����ڿ�ʼ�������������߾���������Ը�������һ�����ԣ������������У�������������Ҫ�Ľ����ʲô(WHAT)�����������(HOW)��ý����SQL ����������㡣�� SQL �У����Dz��������ݿ�����μ�����Ϣ�ģ��Ϳ��Եõ���������Ľ�����ʹ������ʽ SQL10 ����Ϊ��֪�ļ��ɡ�
����
Ϊ�������� 10 �� SQL ���ɵļ�ֵ��������Ҫ�˽��� SQL ���Ե������ġ�Ϊʲô��Ҫ�� Java ���������� SQL ��?(�ҿ�����Ψһһ���� Java ���������� SQL ����)���潲��Ϊʲô��

�����ڿ�ʼ�������������߾������ֵ�Ը�������һ�����ԣ������������У�������������Ҫ�Ľ����ʲô(WHAT)�����������(HOW)��ý�������磬�� SQL �У����Ǹ����������Ҫ“����”(����)�û����͵�ַ���������Ҿ�ס����ʿ���û������Dz��������ݿ⽫��μ�����Щ��Ϣ(���磬���ȼ����û����أ������ȼ��ص�ַ��?������������Ƕ��ѭ���������أ�����ʹ�� hashmap ����?���Ƚ��������ݼ��ص��ڴ��У�Ȼ���ٹ��˳���ʿ�û��أ������ȼ�����ʿ��ַ?�ȵȡ�)
��ÿ������һ����������Ȼ��Ҫ�˽����ݿⱳ��Ļ���ԭ�����������ݿ��ڲ�ѯʱ������ȷ�ľ��ߡ����磬�������������б�Ҫ��
�ڱ�֮�佨�����ʵ����(���ܸ������ݿ�ÿ����ַ����һ����Ӧ���û�)
�������ֶ�����������������(���ܸ������ݿ������ O(log N) ������ O(N) �ĸ��Ӷ��ڲ��ҵ��ض��Ĺ��� )��
���ǣ�һ�����ݿ��Ӧ�ó����ó���֮�����ǾͿ���������Ҫ��Ԫ���ݷ����ʵ���λ�����ˣ�����ֻ��רע��ҵ�������ɡ������ 10 ������չʾ�ˣ����ü�������ʽ SQL ���ܱ�дǿ���˹��ܵ��������������������ɼ������Ҳ�������ɸ��ӵ������
1. һ�ж��DZ�
����һ����������ļ��ɣ���������˵�������ļ��ɣ�������ȫ������ SQL �Ļ�����һ�ж��DZ��������ǿ��������� SQL ���ʱ��
SELECT *
FROM person
……���Ǻܿ������ FROM �Ӿ����ҵ� person �����ܺã�����һ�ű�������������ʶ���������Ҳ��һ�ű���?���磬���ǿ�������д��
SELECT *
FROM (
SELECT *
FROM person
) t
���ڣ������Ѿ�������һ����ν��“������”���� FROM �Ӿ��е�Ƕ�� SELECT ��䡣
����������ģ����������ϸ���룬�����൱���ŵġ����ǻ�������ijЩ���ݿ�(���� PostgreSQL��SQL Server)��ʹ�� VALUES() ���캯����������ʱ�ڴ����
SELECT *
FROM (
VALUES(1),(2),(3)
) t(a)
��ʱ�������������ˣ�
a
—
1
2
3
�����Ӧ�����ݿⲻ֧�ָ��Ӿ䣬����Իص�ʹ���������ϣ����磬�� Oracle �У�
SELECT *
FROM (
SELECT 1 AS a FROM DUAL UNION ALL
SELECT 2 AS a FROM DUAL UNION ALL
SELECT 3 AS a FROM DUAL
) t
��Ȼ�����Ѿ������� VALUES() ��������ʵ��������ͬ�ģ���ô�Ӹ����ϣ����ǻع�һ�� INSERT ��䣬�����������ͣ�
-- SQL Server, PostgreSQL, some others:
INSERT INTO my_table(a)
VALUES(1),(2),(3);
-- Oracle, many others:
INSERT INTO my_table(a)
SELECT 1 AS a FROM DUAL UNION ALL
SELECT 2 AS a FROM DUAL UNION ALL
SELECT 3 AS a FROM DUAL
�� SQL �У�һ�ж��DZ��������ڱ��в�����ʱ��ʵ���ϲ����Dz��뵥�����С��Dz������ű����ڴ��������£�����ֻ�����ɲ�����һ�ŵ��б������û����ʶ�� INSERT ��������ʲô��
һ�ж��DZ����� PostgreSQL �У������������DZ���
SELECT *
FROM substring('abcde', 2, 3)
�������Ľ���ǣ�
substring
———
bcd
���������ʹ�� Java ��̣���ô����ʹ�� Java 8 Stream API ������һ������ȡ��������µȼ۸��
TABLE : Stream<Tuple<..>>
SELECT : map()
DISTINCT : distinct()
JOIN : flatMap()
WHERE / HAVING : filter()
GROUP BY : collect()
ORDER BY : sorted()
UNION ALL : concat()
�� Java 8 �У�“һ�ж�����”(�������㿪ʼʹ����ʱ������)���������ת���������磬ʹ�� map() �� filter() ת�����������ʼ�ն�������
����д��һƪ������������������ؽ�����һ�㣬���� Stream API �� SQL �����˶Աȣ� Common SQL C lauses and Their Equivalents in Java 8 Streams
���������Ѱ��“���õ���”(�������и��� SQL �������)����鿴 jOOλ����һ���� SQL ���ں������뵽 Java �еĿ�Դ�⡣
2. ʹ�õݹ� SQL ��������
����������ʽ(Common Table Expressions ��CTE���� Oracle ��Ҳ�����Ӳ�ѯ�ֽ�)�������� SQL ������������Ψһ����(����ģ�� WINDOW �Ӿ�֮�⣬WINDOW �Ӿ�Ҳֻ���� PostgreSQL �� Sybase SQL �п���)��
����һ������ǿ��ĸ���dz�ǿ��������������
-- ������
WITH
t1(v1, v2) AS (SELECT 1, 2),
t2(w1, w2) AS (
SELECT v1 * 2, v2 * 2
FROM t1
)
SELECT *
FROM t1, t2
���Ľ���ǣ�
v1 v2 w1 w2
-----------------
1 2 2 4
ʹ�ü� WITH �Ӿ䣬���ǿ���ָ��һϵ�б�����(���ס��һ�ж��DZ�)����Щ��������������������ġ�
����������⡣���Ѿ�ʹ�� CTE(Common Table Expressions)�dz������ˣ����ǣ������˲�����ǣ����ǻ������ݹ�!�������� PostgreSQL ʾ����
WITH RECURSIVE t(v) AS (
SELECT 1 -- ������
UNION ALL
SELECT v + 1 -- �ݹ�
FROM t
)
SELECT v
FROM t
LIMIT 5
���Ľ���ǣ�
v
—
1
2
3
4
5
������ι�������?һ���㿴����һЩ�ؼ��ʣ�������������ˡ����Ƕ�����һ������������ʽ����ǡ�������� UNION ALL �Ӳ�ѯ��
��һ�� UNION ALL �Ӳ�ѯ������ͨ����˵��“������”����“����”(��ʼ��)�ݹ顣����������һ�л���У��Ժ����ǽ�����Щ���ϵݹ顣��ס��һ�ж��DZ������Եݹ齫���������ű��ϣ������ǵ����� / ֵ�ϡ�
�ڶ��� UNION ALL �Ӳ�ѯ�ڷ����ݹ�ĵط����������ϸ�۲죬�ᷢ������ t ��ѡ��Ҳ����˵�������ڶ����Ӳ�ѯ�����Ǽ��������� CTE �еݹ��ѡ����ˣ��������Է���ʹ������ CTE �������� v��
�����ǵ�ʾ���У�����ʹ���� (1) �Եݹ�������Ӵ�����Ȼ��ͨ������ v + 1 �����еݹ顣���ͨ������ LIMIT 5 ����ֹ�ݹ�(��Ҫ����DZ�ڵ����ݹ� ������ʹ�� Java 8 ����һ��)��
��ע��ͼ���걸
�ݹ� CTE ʹ�� SQL:1999 ͼ���걸������ζ���κγ������� SQL ��д! (����㹻���Ļ�)
һ�����������ڲ����ϵ�����ӡ����̵������ǣ�Mandelbrot ������ http://explainextended.com/2013/12/31/happy-new-year-5/ ��ʾ��
WITH RECURSIVE q(r, i, rx, ix, g) AS (
SELECT r::DOUBLE PRECISION * 0.02, i::DOUBLE PRECISION * 0.02,
.0::DOUBLE PRECISION , .0::DOUBLE PRECISION, 0
FROM generate_series(-60, 20) r, generate_series(-50, 50) i
UNION ALL
SELECT r, i, CASE WHEN abs(rx * rx + ix * ix) &amp;lt;= 2 THEN rx * rx - ix * ix END + r,
CASE WHEN abs(rx * rx + ix * ix) &amp;lt;= 2 THEN 2 * rx * ix END + i, g + 1
FROM q
WHERE rx IS NOT NULL AND g &amp;lt; 99
)
SELECT array_to_string(array_agg(s ORDER BY r), '')
FROM (
SELECT i, r, substring(' .:-=+*#%@', max(g) / 10 + 1, 1) s
FROM q
GROUP BY i, r
) q
GROUP BY i
ORDER BY i
�� PostgreSQL ����������Ĵ��룬���ǽ��õ����½����
�p���ƴ��� .-.:-.......==..*.=.::-@@@@@:::.:.@..*-. =. ...=...=...::+%.@:@@@@@@@@@@@@@+*#=.=:+-. ..- .:.:=::*....@@@@@@@@@@@@@@@@@@@@@@@@=@@.....::...:. .-.:-.......==..*.=.::-@@@@@:::.:.@..*-. =.
...=...=...::+%.@:@@@@@@@@@@@@@+*#=.=:+-. ..-
.:.:=::*....@@@@@@@@@@@@@@@@@@@@@@@@=@@.....::...:.
...*@@@@=.@:@@@@@@@@@@@@@@@@@@@@@@@@@@=.=....:...::.
.::@@@@@:-@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@..-:@=*:::.
.-@@@@@-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.=@@@@=..:
...@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@@@@@:..
....:-*@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@::
.....@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-..
.....@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-:...
.--:+.@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@...
.==@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-..
..+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-#.
...=+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..
-.=-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..:
.*%:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:@-
. ..:... ..-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
.............. ....-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@%@=
.--.-.....-=.:..........::@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..
..=:-....=@+..=.........@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:.
.:+@@::@==@-*:%:+.......:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
::@@@-@@@@@@@@@-:=.....:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:
.:@@@@@@@@@@@@@@@=:.....%@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
.:@@@@@@@@@@@@@@@@@-...:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@:-
:@@@@@@@@@@@@@@@@@@@-..%@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
%@@@@@@@@@@@@@@@@@@@-..-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
@@@@@@@@@@@@@@@@@@@@@::+@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@+
@@@@@@@@@@@@@@@@@@@@@@:@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@..
@@@@@@@@@@@@@@@@@@@@@@-@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@-
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@.
ӡ���Dz��Ƿdz����?
3. �ۼƼ���
��������кܶ��ۼƼ����ʾ����������ѧϰ�� SQL ���н��������ʾ��֮һ����Ϊ������ʮ���ַ�������ʵ���ۼƼ��㡣
�ڸ����ϣ��ۼƼ�����������⡣

�� Microsoft Excel �У�����ֻ�����ǰ����(�������)ֵ�ĺ�(���)��Ȼ��ʹ�ÿ��õ�ʮ�ֹ�꽫�ù�ʽ�����������ӱ��������ڵ��ӱ�����“����”�����������һ��“�ۼ�”��
�� SQL �У���õķ�����ʹ�ô��ں�������Ҳ�Ǹò��Ͷ�����۵���һ���⡣
���ں�����һ������ǿ��ĸ��һ��ʼ���ܲ�̫�������⣬����ʵ�ϣ����Ƿdz��dz���
���ں���������Ե�ǰ�ж��Ե�һ���Ӽ��ϵľۺ�/����ǰ���� SELECT ת����
����������!
�������ϵ���˼�ǣ�һ�����ں������ԶԵ�ǰ�е�“��”��“��”��ִ�м��㡣Ȼ��������ͨ�ľۺϺ� GROUP BY ��ͬ�����Dz�ת���У���ʹ�����Ƿdz����á�
��ܽ����£������ǿ�ѡ�ģ�
function(...) OVER (
PARTITION BY ...
ORDER BY ...
ROWS BETWEEN ... AND ...
)
��ˣ����ǿ���ʹ���κ����͵ĺ���(�Ժ����ǽ����ܴ��ຯ����ʾ��)��������������� OVER() �Ӿ䣬���Ӿ�ָ�����ڡ�������� OVER() �Ӿ䶨�����£�
PARTITION ������ֻ�����뵱ǰ����ͬһ�����е���
ORDER������������Զ���������ѡ�������
ROWS(�� RANGE )��ܶ��壺���ڿ��Ա������ڹ̶��������е�“ǰ��”��“����”��
����Ǵ��ں�����ȫ�����ܡ�
��ô��������ΰ��������ۼƼ������?�����������ݣ�
| ID | VALUE_DATE | AMOUNT | BALANCE |
|------|------------|--------|------------|
| 9997 | 2014-03-18 | 99.17 | 19985.81 |
| 9981 | 2014-03-16 | 71.44 | 19886.64 |
| 9979 | 2014-03-16 | -94.60 | 19815.20 |
| 9977 | 2014-03-16 | -6.96 | 19909.80 |
| 9971 | 2014-03-15 | -65.95 | 19916.76 |
���� BALANCE ��������� AMOUNT ��������
ֱ���Ӿ��ϣ����ǿ�������������������dz����ģ�

��ˣ�ʹ�ü�Ӣ��κ�������������α SQL ��ʾ��
TOP_BALANCE – SUM(AMOUNT) OVER (
“all the rows on top of the current row”
)
�������� SQL �����������
SUM(t.amount) OVER (
PARTITION BY t.account_id
ORDER BY t.value_date DESC,
t.id DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND 1 PRECEDING
)
˵����
��������ÿ�������ʻ����ܺͣ��������������ݼ����ܺ�
����ȷ�����������֮ǰ(�ڷ�����)�������
�����֮ǰ��rows �Ӿ�ֻ����ǰ�����(�ڷ����ڣ�����˳��)
������Щ���������ڴ��е����ݼ��ϣ������ݼ�������ͨ�� FROM … WHERE �Ӿ�ѡ�����������ٶȷdz��졣
����
�����ǿ�ʼ�����������ʼ���֮ǰ���ȿ���һ�£������Ѿ�ѧϰ��
(�ݹ�)����������ʽ(CTE)
���ں���
���������ܶ��ǣ�
�dz���
���ܼ���ǿ��
����ʽ
SQL ����һ����
�����ڴ�������е� RDBMS(���� MySQL)
�dz���Ҫ�Ĺ�����
����ܴӱ����еó�ʲô���ۣ��Ǿ�������Ӧ����ȫ�˽��ִ� SQL �������������顣Ϊʲô��?��Ϊ��

4. ��������������
Stack Overflow ��һ���dz��õĹ��ܣ����£������Լ������Ǿ����ܳ�ʱ��ش������ǵ���վ�ϡ�

��ģ���ԣ�����Կ������ж��ٻ��¡�
��Ҫ��ô������Щ������?�����ǿ���“������”��“������”����Щ�����ǰ䷢����Щ������ƽ̨������ͣ��һ��ʱ����ˡ����۽������ջ����������գ��㶼�����¼��������������ٴδ��㿪ʼ��
�����ǽ�������ʽ���ʱ���Dz���Ҫά���κ�״̬���ڴ�������ġ����ڣ������������߷��� SQL ����ʽ��������һ�㡣���������������ݣ�
| LOGIN_TIME |
|---------------------|
| 2014-03-18 05:37:13 |
| 2014-03-16 08:31:47 |
| 2014-03-16 06:11:17 |
| 2014-03-16 05:59:33 |
| 2014-03-15 11:17:28 |
| 2014-03-15 10:00:11 |
| 2014-03-15 07:45:27 |
| 2014-03-15 07:42:19 |
| 2014-03-14 09:38:12 |
��ûʲô�á����Ǵ�ʱ�����ɾ��Сʱ����ܼ�
SELECT DISTINCT
cast(login_time AS DATE) AS login_date
FROM logins
WHERE user_id = :user_id
�õ��Ľ���ǣ�
| LOGIN_DATE |
|------------|
| 2014-03-18 |
| 2014-03-16 |
| 2014-03-15 |
| 2014-03-14 |
���ڣ������Ѿ�ѧϰ�˴��ں���������ֻ��Ϊÿ����������һ�����������ɣ�
SELECT
login_date,
row_number() OVER (ORDER BY login_date)
FROM login_dates
������£�
| LOGIN_DATE | RN |
|------------|----|
| 2014-03-18 | 4 |
| 2014-03-16 | 3 |
| 2014-03-15 | 2 |
| 2014-03-14 | 1 |
���Ǻ����İɡ����ڣ�������Dz�����ѡ����Щֵ�����Ǽ�ȥ���ǣ��ᷢ��ʲô?
SELECT
login_date -
row_number() OVER (ORDER BY login_date)
FROM login_dates
����õ����½����
| LOGIN_DATE | RN | GRP |
|------------|----|------------|
| 2014-03-18 | 4 | 2014-03-14 |
| 2014-03-16 | 3 | 2014-03-13 |
| 2014-03-15 | 2 | 2014-03-13 |
| 2014-03-14 | 1 | 2014-03-13 |
��ġ�����Ȥ�����ԣ�14–1=13��15–2=13��16–3=13������ 18–4=14��û�����ܱ� Doge ˵�ø����ˣ�

��һ������������Ϊ�ļ�ʾ����
ROW_NUMBER() û�м������������Ķ���
���ǣ����ǵ������м��
���ԣ������Ǵ�һ�����������ڵ�“gapful”�����м�ȥһ������������“gapless”����ʱ�����ǽ��õ�����������ÿ��“gapless”�����е���ͬ���ڣ���������һ���µ����ڣ����������������м���ġ�
�š�
����ζ���������ڿ��Լ� GROUP BY ����������ֵ�ˣ�
SELECT
min(login_date), max(login_date),
max(login_date) -
min(login_date) + 1 AS length
FROM login_date_groups
GROUP BY grp
ORDER BY length DESC
���������ˡ���������������б��ҵ��ˣ�
| MIN | MAX | LENGTH |
|------------|------------|--------|
| 2014-03-14 | 2014-03-16 | 3 |
| 2014-03-18 | 2014-03-18 | 1 |
�����IJ�ѯ���£�
ITH
login_dates AS (
SELECT DISTINCT cast(login_time AS DATE) login_date
FROM logins WHERE user_id = :user_id
),
login_date_groups AS (
SELECT
login_date,
login_date - row_number() OVER (ORDER BY login_date) AS grp
FROM login_dates
)
SELECT
min(login_date), max(login_date),
max(login_date) - min(login_date) + 1 AS length
FROM login_date_groups
GROUP BY grp
ORDER BY length DESC

���û��ô�Ѱ�?��Ȼ������Ҫ������������뷨�����Dz�ѯ������ķdz������š�û�б�������ķ�����ʵ��һЩ����ʽ�㷨�ˡ�
5. �����еij���
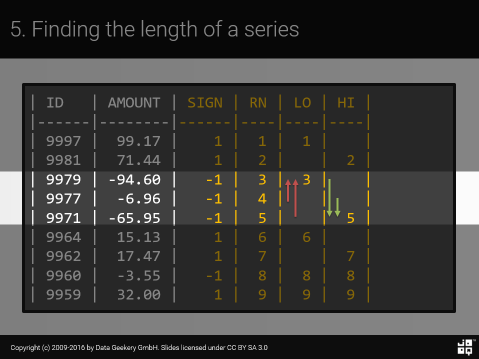
��ǰ�棬���ǿ�����һϵ��������ֵ��������״�������Ϊ���ǿ������������������ԡ����һ��“����”�Ķ��岻��ôֱ�ۣ����ҳ���֮�⣬�������а�����ͬ��ֵ��?�����������ݣ����� LENGTH ��Ҫ�����ÿ�����еij��ȣ�
| ID | VALUE_DATE | AMOUNT | LENGTH |
|------|------------|--------|------------|
| 9997 | 2014-03-18 | 99.17 | 2 |
| 9981 | 2014-03-16 | 71.44 | 2 |
| 9979 | 2014-03-16 | -94.60 | 3 |
| 9977 | 2014-03-16 | -6.96 | 3 |
| 9971 | 2014-03-15 | -65.95 | 3 |
| 9964 | 2014-03-15 | 15.13 | 2 |
| 9962 | 2014-03-15 | 17.47 | 2 |
| 9960 | 2014-03-15 | -3.55 | 1 |
| 9959 | 2014-03-14 | 32.00 | 1 |
�ǵģ���¶��ˡ� “����”��������(�� ID ����)���Ҿ�����ͬ�� SIGN(AMOUNT) ��һ��ʵ������ġ��ٴμ�����µ����ݸ�ʽ��
| ID | VALUE_DATE | AMOUNT | LENGTH |
|------|------------|--------|------------|
| 9997 | 2014-03-18 | +99.17 | 2 |
| 9981 | 2014-03-16 | +71.44 | 2 |
| 9979 | 2014-03-16 | -94.60 | 3 |
| 9977 | 2014-03-16 | - 6.96 | 3 |
| 9971 | 2014-03-15 | -65.95 | 3 |
| 9964 | 2014-03-15 | +15.13 | 2 |
| 9962 | 2014-03-15 | +17.47 | 2 |
| 9960 | 2014-03-15 | - 3.55 | 1 |
| 9959 | 2014-03-14 | +32.00 | 1 |
������ô����?��“��”�����ȣ�����ȥ�����е���������������һ���кţ�
SELECT
id, amount,
sign(amount) AS sign,
row_number()
OVER (ORDER BY id DESC) AS rn
FROM trx
���Ľ���ǣ�
| ID | AMOUNT | SIGN | RN |
|------|--------|------|----|
| 9997 | 99.17 | 1 | 1 |
| 9981 | 71.44 | 1 | 2 |
| 9979 | -94.60 | -1 | 3 |
| 9977 | -6.96 | -1 | 4 |
| 9971 | -65.95 | -1 | 5 |
| 9964 | 15.13 | 1 | 6 |
| 9962 | 17.47 | 1 | 7 |
| 9960 | -3.55 | -1 | 8 |
| 9959 | 32.00 | 1 | 9 |
���ڣ���������Ŀ�����������±���
| ID | AMOUNT | SIGN | RN | LO | HI |
|------|--------|------|----|----|----|
| 9997 | 99.17 | 1 | 1 | 1 | |
| 9981 | 71.44 | 1 | 2 | | 2 |
| 9979 | -94.60 | -1 | 3 | 3 | |
| 9977 | -6.96 | -1 | 4 | | |
| 9971 | -65.95 | -1 | 5 | | 5 |
| 9964 | 15.13 | 1 | 6 | 6 | |
| 9962 | 17.47 | 1 | 7 | | 7 |
| 9960 | -3.55 | -1 | 8 | 8 | 8 |
| 9959 | 32.00 | 1 | 9 | 9 | 9 |
�ڸñ��У�����ϣ�����к�ֵ���Ƶ�����“ĩ”�˵�“LO”������“��”�˵�“HI”�С�Ϊ�ˣ����ǽ�ʹ������� LEAD() �� LAG()��LEAD() ���Է��ʵ�ǰ�����µĵ� n �У��� LAG() ���Է��ʵ�ǰ�����ϵĵ� n �С����磺
SELECT
lag(v) OVER (ORDER BY v),
v,
lead(v) OVER (ORDER BY v)
FROM (
VALUES (1), (2), (3), (4)
) t(v)
������ѯ���ɵĽ����

̫����!��ס��ʹ�ô��ں���������Զ�����ڵ�ǰ�е��Ӽ�ִ�������ۺϡ��� LEAD() �� LAG() ������£�ֻҪ������ǰ�е�ƫ�������Ϳ��Է�������ڵ�ǰ�еĵ����С����ںܶ�����¶������á�
�������ǵ�“LO”��“HI”ʾ�������ǿ��Լ�����д��
SELECT
trx.*,
CASE WHEN lag(sign)
OVER (ORDER BY id DESC) != sign
THEN rn END AS lo,
CASE WHEN lead(sign)
OVER (ORDER BY id DESC) != sign
THEN rn END AS hi,
FROM trx
……���ǽ�“ǰһ��”sign (lag(sign)) ��“��ǰ”sign (sign) ���бȽϡ�������Dz�ͬ�����ǽ��кŷŵ�“LO”�У���Ϊ�������е��½硣
Ȼ�����DZȽ�“��һ��”sign (lead(sign)) ��“��ǰ”sign (sign)��������Dz�ͬ�����ǽ��кŷŵ�“HI”�У���Ϊ�������е��Ͻ硣
�����һЩ���ĵ� NULL ��������ȷ��һ�������������������:
SELECT -- With NULL handling...
trx.*,
CASE WHEN coalesce(lag(sign)
OVER (ORDER BY id DESC), 0) != sign
THEN rn END AS lo,
CASE WHEN coalesce(lead(sign)
OVER (ORDER BY id DESC), 0) != sign
THEN rn END AS hi,
FROM trx
��һ��������ϣ��“LO”��“HI”�������������У����������������е�“�½�”��“�Ͻ�”�ϡ����磬��������
| ID | AMOUNT | SIGN | RN | LO | HI |
|------|--------|------|----|----|----|
| 9997 | 99.17 | 1 | 1 | 1 | 2 |
| 9981 | 71.44 | 1 | 2 | 1 | 2 |
| 9979 | -94.60 | -1 | 3 | 3 | 5 |
| 9977 | -6.96 | -1 | 4 | 3 | 5 |
| 9971 | -65.95 | -1 | 5 | 3 | 5 |
| 9964 | 15.13 | 1 | 6 | 6 | 7 |
| 9962 | 17.47 | 1 | 7 | 6 | 7 |
| 9960 | -3.55 | -1 | 8 | 8 | 8 |
| 9959 | 32.00 | 1 | 9 | 9 | 9 |
����ʹ�õ����������� Redshift��Sybase SQL Anywhere��DB2��Oracle ���ǿ��õġ�����ʹ�õ���“IGNORE NULLS”�Ӿ䣬�����Դ��ݸ�ijЩ���ں�����
SELECT
trx.*,
last_value (lo) IGNORE NULLS OVER (
ORDER BY id DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS lo,
first_value(hi) IGNORE NULLS OVER (
ORDER BY id DESC
ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING) AS hi
FROM trx
�кܶ�ؼ���!�����ʶ���һ���ġ����κθ�����“��ǰ”���У����Dz鿴����“֮ǰ��ֵ”(ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)�����������п�ֵ����֮ǰ��ֵ�У�����ȡ���һ��ֵ����������ǵ���“LO”ֵ�����仰˵������ȡ“�����ǰһ��”“LO”ֵ��
“HI”Ҳ��һ���ġ����κθ�����“��ǰ”���У����Dz鿴����“����ֵ”(ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)�����������п�ֵ��������ֵ�У�����ȡ��һ��ֵ���������ǵ���“HI”ֵ������֮������ȡ“�������һ��”“HI”ֵ��
ʹ�ûõ�Ƭ�������£�
100% ��ȷ�����ϵ����ĵ� NULL ������
SELECT -- With NULL handling...
trx.*,
coalesce(last_value (lo) IGNORE NULLS OVER (
ORDER BY id DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW), rn) AS lo,
coalesce(first_value(hi) IGNORE NULLS OVER (
ORDER BY id DESC
ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING), rn) AS hi
FROM trx
���������һ�����裬��ס���һ�����Ĵ���
SELECT
trx.*,
1 + hi - lo AS length
FROM trx
���������ˣ�������£�
| ID | AMOUNT | SIGN | RN | LO | HI | LENGTH|
|------|--------|------|----|----|----|-------|
| 9997 | 99.17 | 1 | 1 | 1 | 2 | 2 |
| 9981 | 71.44 | 1 | 2 | 1 | 2 | 2 |
| 9979 | -94.60 | -1 | 3 | 3 | 5 | 3 |
| 9977 | -6.96 | -1 | 4 | 3 | 5 | 3 |
| 9971 | -65.95 | -1 | 5 | 3 | 5 | 3 |
| 9964 | 15.13 | 1 | 6 | 6 | 7 | 2 |
| 9962 | 17.47 | 1 | 7 | 6 | 7 | 2 |
| 9960 | -3.55 | -1 | 8 | 8 | 8 | 1 |
| 9959 | 32.00 | 1 | 9 | 9 | 9 | 1 |
�����IJ�ѯ������£�
WITH
trx1(id, amount, sign, rn) AS (
SELECT id, amount, sign(amount), row_number() OVER (ORDER BY id DESC)
FROM trx
),
trx2(id, amount, sign, rn, lo, hi) AS (
SELECT trx1.*,
CASE WHEN coalesce(lag(sign) OVER (ORDER BY id DESC), 0) != sign
THEN rn END,
CASE WHEN coalesce(lead(sign) OVER (ORDER BY id DESC), 0) != sign
THEN rn END
FROM trx1
)
SELECT
trx2.*, 1
- last_value (lo) IGNORE NULLS OVER (ORDER BY id DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
+ first_value(hi) IGNORE NULLS OVER (ORDER BY id DESC
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
FROM trx2

�š���� SQL ��ʼ�����Ȥ��!
���ý�������ѧϰ����?
6. SQL ���Ӽ��������
��������ϲ���IJ���!
ʲô���Ӽ����������?�������ҵ�һ����Ȥ�Ľ��ͣ� https://xkcd.com/287
����һ���Ƚ����ĵĽ��ͣ� https://en.wikipedia.org/wiki/Subset_sum_problem
�����ϣ�����ÿһ������…
| ID | TOTAL |
|----|-------|
| 1 | 25150 |
| 2 | 19800 |
| 3 | 27511 |
…����ϣ���ҵ�������“���”(����ӽ���)����ͣ����������¸����������ϣ�
| ID | ITEM |
|------|-------|
| 1 | 7120 |
| 2 | 8150 |
| 3 | 8255 |
| 4 | 9051 |
| 5 | 1220 |
| 6 | 12515 |
| 7 | 13555 |
| 8 | 5221 |
| 9 | 812 |
| 10 | 6562 |
�����������ĵ���ѧ�����ٶȺܿ죬�������ǿ��������������Щ����õ���ͣ�
| TOTAL | BEST | CALCULATION
|-------|-------|--------------------------------
| 25150 | 25133 | 7120 + 8150 + 9051 + 812
| 19800 | 19768 | 1220 + 12515 + 5221 + 812
| 27511 | 27488 | 8150 + 8255 + 9051 + 1220 + 812
����� SQL Ҫ������һ����?�ܼ�ֻ��Ҫ����һ���������� 2n possible sums �� CTE��Ȼ��Ϊÿ�� TOTAL �ҵ���ӽ���һ�����ɣ�
-- All the possible 2N sums
WITH sums(sum, max_id, calc) AS (...)
-- Find the best sum per “TOTAL”
SELECT
totals.total,
something_something(total - sum) AS best,
something_something(total - sum) AS calc
FROM draw_the_rest_of_the_*bleep*_owl
�����ڶ���ƪ���µ�ʱ������ܻ����ҵ�����һ��:

���������ģ��������Ҳ������ô��(���������㷨�����ʣ�����ִ��)��
WITH sums(sum, id, calc) AS (
SELECT item, id, to_char(item) FROM items
UNION ALL
SELECT item + sum, items.id, calc || ' + ' || item
FROM sums JOIN items ON sums.id < items.id
)
SELECT
totals.id,
totals.total,
min (sum) KEEP (
DENSE_RANK FIRST ORDER BY abs(total - sum)
) AS best,
min (calc) KEEP (
DENSE_RANK FIRST ORDER BY abs(total - sum)
) AS calc,
FROM totals
CROSS JOIN sums
GROUP BY totals.id, totals.total
�ڱ����У��ҽ������ʹ˽����������ϸ��Ϣ����Ϊ��������Ǵ���һƪ������ѡȡ�ģ������������鿴:���ʹ�� SQL ������ӽ����Ӽ���
ϣ���������õ��Ķ�����Ӧϸ�ڣ���һ��Ҫ�����鿴���� 4 �����ɣ�
7. �����ۼƼ���
��ĿǰΪֹ�������Ѿ�ѧϰ�����ʹ�ô��ں����� SQL ����“��ͨ”���ۼƼ��㡣�Ǻ����ס����ڣ�������ǰ��ۼƼ�����������Զ�������������»���ô����?ʵ���ϣ���������Ҫ�õ����µļ��㣺
| DATE | AMOUNT | TOTAL |
|------------|--------|-------|
| 2012-01-01 | 800 | 800 |
| 2012-02-01 | 1900 | 2700 |
| 2012-03-01 | 1750 | 4450 |
| 2012-04-01 | -20000 | 0 |
| 2012-05-01 | 900 | 900 |
| 2012-06-01 | 3900 | 4800 |
| 2012-07-01 | -2600 | 2200 |
| 2012-08-01 | -2600 | 0 |
| 2012-09-01 | 2100 | 2100 |
| 2012-10-01 | -2400 | 0 |
| 2012-11-01 | 1100 | 1100 |
| 2012-12-01 | 1300 | 2400 |
��ˣ�����ȥ AMOUNT -20000 �����ĸ����ǣ�����û����ʾ -15550 ���ʵ�ʵ� TOTAL��������ʾ�� 0�����仰˵�������ݼ���ʾ���£�
| DATE | AMOUNT | TOTAL |
|------------|--------|-------|
| 2012-01-01 | 800 | 800 | GREATEST(0, 800)
| 2012-02-01 | 1900 | 2700 | GREATEST(0, 2700)
| 2012-03-01 | 1750 | 4450 | GREATEST(0, 4450)
| 2012-04-01 | -20000 | 0 | GREATEST(0, -15550)
| 2012-05-01 | 900 | 900 | GREATEST(0, 900)
| 2012-06-01 | 3900 | 4800 | GREATEST(0, 4800)
| 2012-07-01 | -2600 | 2200 | GREATEST(0, 2200)
| 2012-08-01 | -2600 | 0 | GREATEST(0, -400)
| 2012-09-01 | 2100 | 2100 | GREATEST(0, 2100)
| 2012-10-01 | -2400 | 0 | GREATEST(0, -300)
| 2012-11-01 | 1100 | 1100 | GREATEST(0, 1100)
| 2012-12-01 | 1300 | 2400 | GREATEST(0, 2400)
����Ҫ��ô����?

ȷ�е�˵��ʹ��ģ���ġ��ض��ڹ�Ӧ�̵� SQL���ڱ����У�����ʹ�õ��� Oracle SQL

������ι�����?����ļ�!
ֻҪ���κα������� MODEL ���Ϳ��Դ�һ���ܰ��� SQL “����ͷ”!
SELECT ... FROM some_table
-- ���˷������� table �ĺ���
MODEL ...
һ�����ǰ� MODEL ��������Ϳ����� Microsoft Excel һ������ SQL �����ֱ��ʵ�ֵ��ӱ������ˡ�
��������������������Ҳ��ʹ����㷺��(��ÿ������ϵ��κ���ʹ�� 1-2 ��)��
MODEL
-- The spreadsheet dimensions
DIMENSION BY ...
-- The spreadsheet cell type
MEASURES ...
-- The spreadsheet formulas
RULES ...
��������������ĺ�������ٿ��»õ�Ƭ�Ľ��͡�
DIMENSION BY �Ӿ�ָ�����ӱ����ά�ȡ��� MS Excel ��ͬ��Oracle �п���������������ά�ȣ�
MEASURES �Ӿ�ָ�����ӱ�����ÿ����Ԫ��Ŀ���ֵ���� MS Excel ��ͬ���� Oracle ��ÿ����Ԫ�������һ��������Ԫ�飬���������ǵ���ֵ��

RULES �Ӿ�ָ��Ӧ���ڵ��ӱ�����ÿ����Ԫ��Ĺ�ʽ���� MS Excel ��ͬ����Щ���� / ��ʽ������һ���ط��������Ƿ���ÿ����Ԫ���У�

�������ʹ�� MODEL �� MS Excel ����ʹ�ã����������õĻ������Ĺ��ܻ��ǿ��������ѯ���Ƚ�“����”��������ʾ��
SELECT *
FROM (
SELECT date, amount, 0 AS total
FROM amounts
)
MODEL
DIMENSION BY (row_number() OVER (ORDER BY date) AS rn)
MEASURES (date, amount, total)
RULES (
total[any] = greatest(0,
coalesce(total[cv(rn) - 1], 0) + amount[cv(rn)])
)
���������������Ĺ��ܷdz�ǿ�������� Oracle �Լ��İ�Ƥ�飬�����벻Ҫ�ڱ�����Ѱ���һ�����ͣ����Ķ�����İ�Ƥ�飺
http://www.oracle.com/technetwork/middleware/bi-foundation/10gr1-twp-bi-dw-sqlmodel-131067.pdf
8. ʱ������ģʽʶ��
������Ǵ�����թ�����ڴ������ݼ�������ʵʱ�������κ���������ʱ������ģʽʶ�������˵�϶�����һ�������
������ǻؿ���“���г���”�����ݼ������ǿ���ϣ����ʱ��������Ϊ�����¼�����һ����������������ʾ��
| ID | VALUE_DATE | AMOUNT | LEN | TRIGGER
|------|------------|---------|-----|--------
| 9997 | 2014-03-18 | + 99.17 | 1 |
| 9981 | 2014-03-16 | - 71.44 | 4 |
| 9979 | 2014-03-16 | - 94.60 | 4 | x
| 9977 | 2014-03-16 | - 6.96 | 4 |
| 9971 | 2014-03-15 | - 65.95 | 4 |
| 9964 | 2014-03-15 | + 15.13 | 3 |
| 9962 | 2014-03-15 | + 17.47 | 3 |
| 9960 | 2014-03-15 | + 3.55 | 3 |
| 9959 | 2014-03-14 | - 32.00 | 1 |
�����������Ĺ����ǣ�
����¼��������� 3 �Σ����ڵ� 3 ���ظ�ʱ������
��ǰ��� MODEL �Ӿ����ƣ����ǿ���ʹ�����ӵ� Oracle 12c �е� Oracle �ض����Ӿ���ִ�иò�����
SELECT ... FROM some_table
-- ���˷����κ� table ֮����ģʽƥ��
-- table ������
MATCH_RECOGNIZE (...)
MATCH_RECOGNIZE ���Ӧ�ó���������������
SELECT *
FROM series
MATCH_RECOGNIZE (
-- ģʽƥ�䰴��˳��ִ��
ORDER BY ...
-- ��Щʱģʽƥ���������
MEASURES ...
-- ���еļ��˵��
-- ����ƥ����
ALL ROWS PER MATCH
-- Ҫƥ����¼���“�������ʽ”
PATTERN (...)
-- “ʲô���¼�”�Ķ���
DEFINE ...
)
����Щ����˼�顣�����ǿ�һЩ�Ӿ��ʵ��ʾ����
SELECT *
FROM series
MATCH_RECOGNIZE (
ORDER BY id
MEASURES classifier() AS trg
ALL ROWS PER MATCH
PATTERN (S (R X R+)?)
DEFINE
R AS sign(R.amount) = prev(sign(R.amount)),
X AS sign(X.amount) = prev(sign(X.amount))
)
�ڴ���������ʲô?
����������Ҫƥ���¼���˳����� ID �Ա��������Ƚ����ס�
Ȼ��ָ�����������ֵ��Ϊ�����������Ҫ“MEASURE” trg����������Ϊ��������Ҳ������������� PATTERN ��ʹ�õ��ı������⣬����ϣ��ƥ�������С�
Ȼ������ָ��һ���������������ʽ��ģʽ���ڸ�ģʽ����“S”������ʼ�¼�������ǿ�ѡ�¼�“R”���������ظ��¼���“X”���������¼� X������һ������“R”�����ٴ��ظ����������ģʽƥ�䣬���ǵõ� SRXR �� SRXRR �� SRXRRR���� X ��λ�����г��� >=4 �ĵ���λ�ϡ�
������ǽ� R �� X ����Ϊ��ͬ�Ķ�������ǰ�е� SIGN(AMOUNT) �¼���ǰһ�е� SIGN(AMOUNT) �¼���ͬʱ�����Dz��ض���“S”��“S”�������κ������С�
�ò�ѯ�Ľ��������£�
| ID | VALUE_DATE | AMOUNT | TRG |
|------|------------|---------|-----|
| 9997 | 2014-03-18 | + 99.17 | S |
| 9981 | 2014-03-16 | - 71.44 | R |
| 9979 | 2014-03-16 | - 94.60 | X |
| 9977 | 2014-03-16 | - 6.96 | R |
| 9971 | 2014-03-15 | - 65.95 | S |
| 9964 | 2014-03-15 | + 15.13 | S |
| 9962 | 2014-03-15 | + 17.47 | S |
| 9960 | 2014-03-15 | + 3.55 | S |
| 9959 | 2014-03-14 | - 32.00 | S |
���ǿ������¼����п���һ��“X”�������������������ġ������г��� > 3 ���¼�(ͬһ����)�еĵ������ظ���
̫����!
��Ϊ���Dz�����������“S”��“R”�¼����������ǿ���ɾ�����ǣ�
SELECT
id, value_date, amount,
CASE trg WHEN 'X' THEN 'X' END trg
FROM series
MATCH_RECOGNIZE (
ORDER BY id
MEASURES classifier() AS trg
ALL ROWS PER MATCH
PATTERN (S (R X R+)?)
DEFINE
R AS sign(R.amount) = prev(sign(R.amount)),
X AS sign(X.amount) = prev(sign(X.amount))
)
������£�
| ID | VALUE_DATE | AMOUNT | TRG |
|------|------------|---------|-----|
| 9997 | 2014-03-18 | + 99.17 | |
| 9981 | 2014-03-16 | - 71.44 | |
| 9979 | 2014-03-16 | - 94.60 | X |
| 9977 | 2014-03-16 | - 6.96 | |
| 9971 | 2014-03-15 | - 65.95 | |
| 9964 | 2014-03-15 | + 15.13 | |
| 9962 | 2014-03-15 | + 17.47 | |
| 9960 | 2014-03-15 | + 3.55 | |
| 9959 | 2014-03-14 | - 32.00 | |
����� Oracle!

��˵һ�Σ���Ҫָ�����ܱ������ Oracle ��Ƥ����õؽ�����һ�㣬�����ʹ�õ��� Oracle 12c����ǿ�ҽ������Ķ��ð�Ƥ�飺
http://www.oracle.com/ocom/groups/public/@otn/documents/webcontent/1965433.pdf
9. ��ת�ͷ���ת
������Ѿ�������ƪ�����ˣ���ô��������ݽ��dz���
���������ǵ����ݣ�����Ա����ӰƬ���͵�Ӱ������
| NAME | TITLE | RATING |
|-----------|-----------------|--------|
| A. GRANT | ANNIE IDENTITY | G |
| A. GRANT | DISCIPLE MOTHER | PG |
| A. GRANT | GLORY TRACY | PG-13 |
| A. HUDSON | LEGEND JEDI | PG |
| A. CRONYN | IRON MOON | PG |
| A. CRONYN | LADY STAGE | PG |
| B. WALKEN | SIEGE MADRE | R |
�����������˵����ת��
| NAME | NC-17 | PG | G | PG-13 | R |
|-----------|-------|-----|-----|-------|-----|
| A. GRANT | 3 | 6 | 5 | 3 | 1 |
| A. HUDSON | 12 | 4 | 7 | 9 | 2 |
| A. CRONYN | 6 | 9 | 2 | 6 | 4 |
| B. WALKEN | 8 | 8 | 4 | 7 | 3 |
| B. WILLIS | 5 | 5 | 14 | 3 | 6 |
| C. DENCH | 6 | 4 | 5 | 4 | 5 |
| C. NEESON | 3 | 8 | 4 | 7 | 3 |
�۲���������ΰ���Ա����ģ�Ȼ�����ÿ����Ա���ݵ�Ӱ��������“��ת”��Ӱ�����������Dz�����“��ϵ”�ķ�ʽ����ʾ��(��ÿ������һ��)�����ǽ�������תΪÿ��������һ�С����ǿ���������������Ϊ��������֪�����п��ܵ���ϡ�
����ת����෴���ӿ�ʼʱ�����������Ҫ�ص���“ÿ����һ��”����ʽ��ʾ������
| NAME | RATING | COUNT |
|-----------|--------|-------|
| A. GRANT | NC-17 | 3 |
| A. GRANT | PG | 6 |
| A. GRANT | G | 5 |
| A. GRANT | PG-13 | 3 |
| A. GRANT | R | 6 |
| A. HUDSON | NC-17 | 12 |
| A. HUDSON | PG | 4 |
��ʵ�ܼ��� PostgreSQL �У�������������
SELECT
first_name, last_name,
count(*) FILTER (WHERE rating = 'NC-17') AS "NC-17",
count(*) FILTER (WHERE rating = 'PG' ) AS "PG",
count(*) FILTER (WHERE rating = 'G' ) AS "G",
count(*) FILTER (WHERE rating = 'PG-13') AS "PG-13",
count(*) FILTER (WHERE rating = 'R' ) AS "R"
FROM actor AS a
JOIN film_actor AS fa USING (actor_id)
JOIN film AS f USING (film_id)
GROUP BY actor_id
���ǿ��Խ�һ���� FILTER �Ӿ丽�ӵ��ۺϺ����У��Ա�ֻ����һЩ���ݡ�
�������������ݿ��У����Ƕ�������������
SELECT
first_name, last_name,
count(CASE rating WHEN 'NC-17' THEN 1 END) AS "NC-17",
count(CASE rating WHEN 'PG' THEN 1 END) AS "PG",
count(CASE rating WHEN 'G' THEN 1 END) AS "G",
count(CASE rating WHEN 'PG-13' THEN 1 END) AS "PG-13",
count(CASE rating WHEN 'R' THEN 1 END) AS "R"
FROM actor AS a
JOIN film_actor AS fa USING (actor_id)
JOIN film AS f USING (film_id)
GROUP BY actor_id
�������ĺô��ǣ��ۺϺ���ͨ��ֻ���Ƿ� NULL ֵ������������ǽ�ÿ���ۺ϶�������Ȥ����������ֵ����Ϊ NULL����ô����Ҳ���õ���ͬ�Ľ����
���ڣ������ʹ�õ��� SQL Server �� Oracle�������ʹ�����õ� PIVOTt �� UNPIVOT �Ӿ䡣ͬ�������� MODEL �� MATCH_RECOGNIZE Ҳ��һ����ֻ��Ҫ�ڱ�����������¹ؼ��֣��Ϳ��Եõ���ͬ�Ľ����
-- PIVOTING
SELECT something, something
FROM some_table
PIVOT (
count(*) FOR rating IN (
'NC-17' AS "NC-17",
'PG' AS "PG",
'G' AS "G",
'PG-13' AS "PG-13",
'R' AS "R"
)
)
-- UNPIVOTING
SELECT something, something
FROM some_table
UNPIVOT (
count FOR rating IN (
"NC-17" AS 'NC-17',
"PG" AS 'PG',
"G" AS 'G',
"PG-13" AS 'PG-13',
"R" AS 'R'
)
)
�����װɣ���һ����
10. ���� XML �� JSON
����

JSON ֻ��һ�־��н������Ժ���� XML
���ڣ�ÿ���˶�֪�� XML �dz��á���˿������۳���
JSON ������ô��
��Ҫʹ�� JSON��
���������Ѿ������������⣬���ǿ��Է��ĵغ������ڽ��е� JSON-in-the-database-hype (������Σ������������˶����ڵ�)��Ȼ������������һ�����ӡ���������ݿ���ִ�� XML��
�����������Ҫ���ģ�
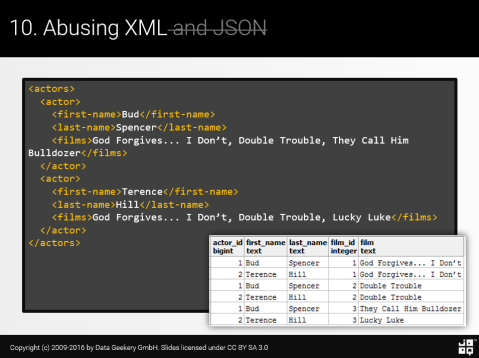
����ϣ����������ԭʼ�� XML �ĵ�������ÿ����Ա�Զ��ŷָ��ĵ�Ӱ�б���������һ��һ�Ĺ�ϵ�ǹ淶�Եı�����Ա / ��Ӱ��
�����ˡ�ʹ�ü��ϡ����Ǹ����������⡣����ʹ������ CTE��
-- PIVOTING
SELECT something, something
FROM some_table
PIVOT (
count(*) FOR rating IN (
'NC-17' AS "NC-17",
'PG' AS "PG",
'G' AS "G",
'PG-13' AS "PG-13",
'R' AS "R"
)
)
-- UNPIVOTING
SELECT something, something
FROM some_table
UNPIVOT (
count FOR rating IN (
"NC-17" AS 'NC-17',
"PG" AS 'PG',
"G" AS 'G',
"PG-13" AS 'PG-13',
"R" AS 'R'
)
)
�ڵ�һ�������У�����ֻ�ǽ����� XML���� PostgreSQL ����£�
WITH RECURSIVE
x(v) AS (SELECT '
Bud
Spencer
God Forgives... I Don’t, Double Trouble, They Call Him Bulldozer
Terence
Hill
God Forgives... I Don’t, Double Trouble, Lucky Luke
'::xml),
actors(actor_id, first_name, last_name, films) AS (...),
films(actor_id, first_name, last_name, film_id, film) AS (...)
SELECT *
FROM films
�����װɡ�
Ȼ������ʹ��һЩ XPath ħ������ XML �ṹ����ȡ����ֵ���������Ƿ������У�
WITH RECURSIVE
x(v) AS (SELECT '...'::xml),
actors(actor_id, first_name, last_name, films) AS (
SELECT
row_number() OVER (),
(xpath('//first-name/text()', t.v))[1]::TEXT,
(xpath('//last-name/text()' , t.v))[1]::TEXT,
(xpath('//films/text()' , t.v))[1]::TEXT
FROM unnest(xpath('//actor', (SELECT v FROM x))) t(v)
),
films(actor_id, first_name, last_name, film_id, film) AS (...)
SELECT *
FROM films
��Ҳ���Ǻ����ġ�
���ֻҪʹ��һ��ݹ��������ʽģʽƥ���ħ�������Ǿ������!
WITH RECURSIVE
x(v) AS (SELECT '...'::xml),
actors(actor_id, first_name, last_name, films) AS (...),
films(actor_id, first_name, last_name, film_id, film) AS (
SELECT actor_id, first_name, last_name, 1,
regexp_replace(films, ',.+', '')
FROM actors
UNION ALL
SELECT actor_id, a.first_name, a.last_name, f.film_id + 1,
regexp_replace(a.films, '.*' || f.film || ', ?(.*?)(,.+)?', '\1')
FROM films AS f
JOIN actors AS a USING (actor_id)
WHERE a.films NOT LIKE '%' || f.film
)
SELECT *
FROM films
�����ܽ��£�

����
����չʾ���������ݶ�������ʽ�ġ����ұȽ����ס���Ȼ��Ϊ�˴ﵽ�����ݽ���չ�ֵ���ȤЧ������ʹ����һЩ���ŵ� SQL ��䣬������ȷ�س�֮Ϊ“��”������һ�㶼��������벻����ϰʹ�� SQL����������������һ���������е��ѣ���Ϊ��
�������ʱ�е㱿
����ʽ˼ά�������ס����٣����Ƿdz����ڲ�ͬ��
����һ��������������ʹ�� SQL ��������ʽ����Ƿdz�ֵ�õģ���Ϊ��ֻ��Ҫ������Ҫ�����ݿ��õĽ�����Ϳ����÷dz��ٵĴ�������������֮��ĸ��ӹ�ϵ��
���Dz��Ǻܰ�?
ԭ�����ӣ�https://jaxenter.com/10-sql-tricks-that-you-didnt-think-were-possible-125934.html
��ǩ�� SQL
��Ȩ��������վ���²��������磬������Ȩ������ϵ��west999com@outlook.com
�ر�ע�⣺��վ����ת���������۲�������վ�۵㣡
��վ���ṩ��ͼƬ���زģ���Ȩ��ԭ�������У�����ʹ�ã�����ԭ������ϵ��

