揭秘腾讯TDSQL全时态数据库系统
2019-09-22 来源:raincent

作者:腾讯TDSQL团队
全时态数据为数据安全、数据重演、数据挖掘和 AI 技术的施展提供了物理基础。这篇文章重点介绍了基于腾讯云 TDSQL 扩展而来的全时态数据库系统(T-TDSQL),T-TDSQL 在保证 OLTP 性能的前提下提供了轻量级的全时态数据管理功能和全时态数据的事务处理能力,以及集当前态数据于生产系统集历史态数据于分析型系统的集群架构,构成了全时态数据的完备解决方案。相应论文已入选 VLDB 2019。
一 前言
腾讯与中国人民大学于 2017 年起,依托于腾讯 TEG 计费平台部丰富的实战经验和中国人民大学数据工程与知识工程教育部重点实验室的多年学术积累,在数据库前沿研究领域开展了深入合作,研究成果已经连续两年入选国际顶级会议 VLDB。
VLDB 会议是国际公认的数据管理与数据库领域顶尖的三大学术会议(SIGMOD、VLDB、ICDE)之一,旨在展示和推广领域内最新的研究成果和核心科技。自 1975 年开办至今,VLDB 会议已经成功举办了 44 届,每年的 VLDB 能在全球范围内吸引到大量优秀的研究人员、企业代表以及行业精英到场参会,是一场不容错过的学术盛会。
继去年在 VLDB2018 上通过 DEMO 论文展示了合作成果 MSQL+ 后(基于 TDSQL 的插件式近似查询工具),今年腾讯与中国人民大学最新联合研究成果“A Lightweight and Efficient Temporal Database Management System in TDSQL”成功被 VLDB2019 Industry Track 接收并将通过长文形式发表。该研究成果由腾讯 TEG 计费平台部 TDSQL 数据库团队与中国人民大学数据工程与知识工程教育部重点实验室深度合作完成。论文介绍了一款基于 TDSQL 扩展而来的全时态数据库系统,该系统在保证 OLTP 性能的前提下,提供了轻量级的时态数据管理功能。本文将对论文研究成果进行详细的分析解读。

图 1 VLDB 官网截图
二 研究背景
时态数据主要指随时间推移不断发生变化的数据,例如温度、账户余额等数据。时态数据在现实生活中非常普遍,而在金融场景下,在数据库层面时态数据管理尤为重要。例如,金融审计时需要获取 2018 年 11 月 08 日至 2018 年 11 月 10 日的账户余额变动情况。如果通过传统数据库(RDBMS)中的普通关系表进行账户余额管理(如图 1 所示),账户余额变动不会被维护,因而上层应用需要通过日志等形式来额外记录余额的每次变动,这会大大提高应用复杂度;而采用如表 2 所示的时态数据表,余额的变迁被原生维护在数据库中,即可准确获取到余额变动数据(表中加粗数据)。
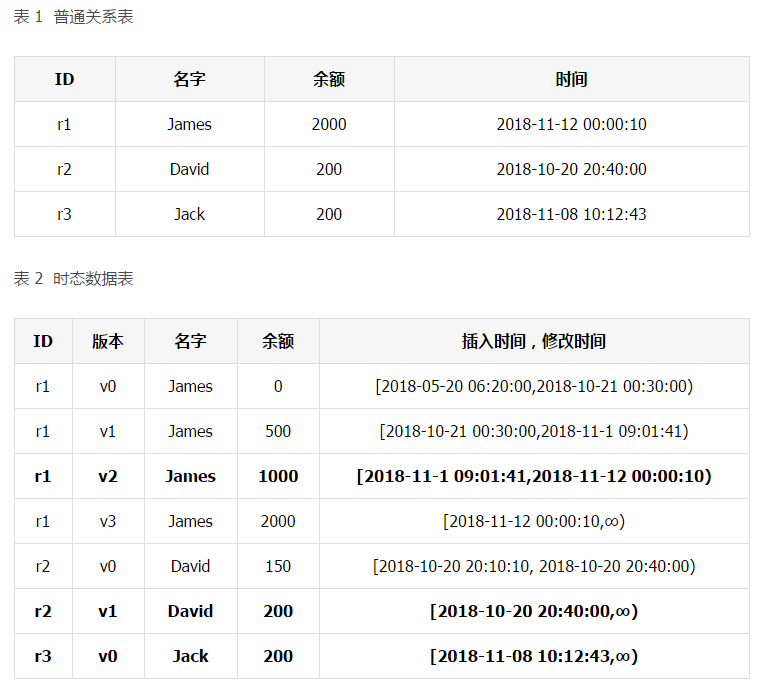
三 系统简介
结合 TDSQL 系统的特点,研究团队提出并实现了一个轻量且高效的全时态数据库系统,该系统可以在保留原有 TDSQL 强劲的 OLTP 处理性能的同时,通过巧妙的系统设计,提供了内建的时态数据管理能力(如图 2 所示)。
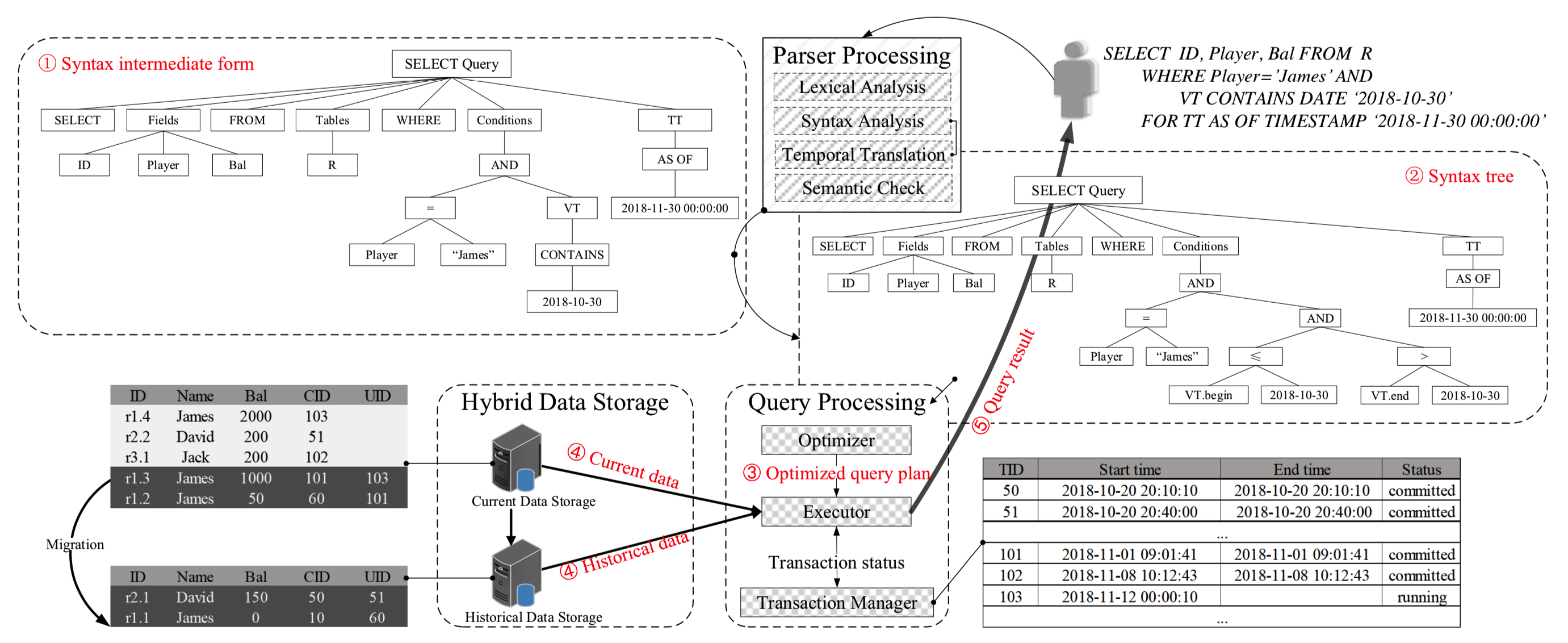
图 2 系统概览
3.1 存储
TDSQL 全时态数据库系统创新性地采用了一种混合存储模式,来对时态数据进行管理。系统将时态数据拆分为当前数据和历史数据,针对不同的数据类型,分别采用不同的存储策略。当前数据管理模块,采用了基于 MVCC(多版本并发访问控制协议)设计的数据库所普遍采用的段页式结构,并且专门开辟回滚段,来对更新或删除操作产生的旧版本进行暂存。在回滚段中暂存的数据会在数据库进行资源回收操作(如 MySQL 中的 Purge 和 PostgreSQL 中的 VACUUM 等)时,迁移到历史数据管理模块,这个过程被称为数据转储。这是一种异步的转储策略,因而几乎不会造成性能损耗。历史数据存储模块,通过 k-v 格式来进行组织,可以大幅度缩小存储开销。由于一个数据项会存在多个历史版本,而这些历史版本会在某些属性上存在一样的值,例如表一中的 James 被重复四次。因此,在历史数据存储模块中,系统将每一个版本转化为一条 k-v,并且只存储相较于上一个版本发生变化的属性值。
3.2 查询与事务处理
系统对时态查询处理逻辑进行了针对性设计与优化。通过专门的时态查询编译器,部分时态查询条件(如有效时间查询)会被重写并拼接到 WHERE 条件中。而对于事务时间查询,系统将其查询条件转化为了内嵌的可见性判断过程,从而使得时态查询所获取的数据满足事务一致性的要求,保证数据的准确性,这点在金融场景下显得尤为重要。
另外,通过持久维护事务状态,系统可以快速获取到事务的执行状态,结合时态数据,即可原生支持事务级数据闪回等实用操作。对于历史数据,系统利用 k-v 存储的特性,可以根据时间条件快速定位到所需数据版本,具备了较好的时态查询性能,且在 SQL 语句的写法上方便用户直接使用 SQL 语句进行查询。
3.3 架构设计
系统体现了 HTAC(Hybrid Transaction / Analytical Cluster,混合事务 / 分析集群)这一新型的系统架构设计理念,如图 3。
TDSQL 全时态数据库系统分为 OLTP 集群和 OLAP 集群,OLTP 集群负责事务型业务,OLAP 系统处理分析型业务,提供历史数据的查询分析等功能。通过统一路由模块根据查询语句、查询操作的语义将 SQL 发送到对应集群进行处理。由于时态数据查询等负载需要占用大量系统资源,这种拆分的系统设计可以尽量影响减小生产系统受到的性能影响。其次,历史数据量级较大,OLAP 集群通过扩展存储的方式,即可实现历史数据的无限存储。
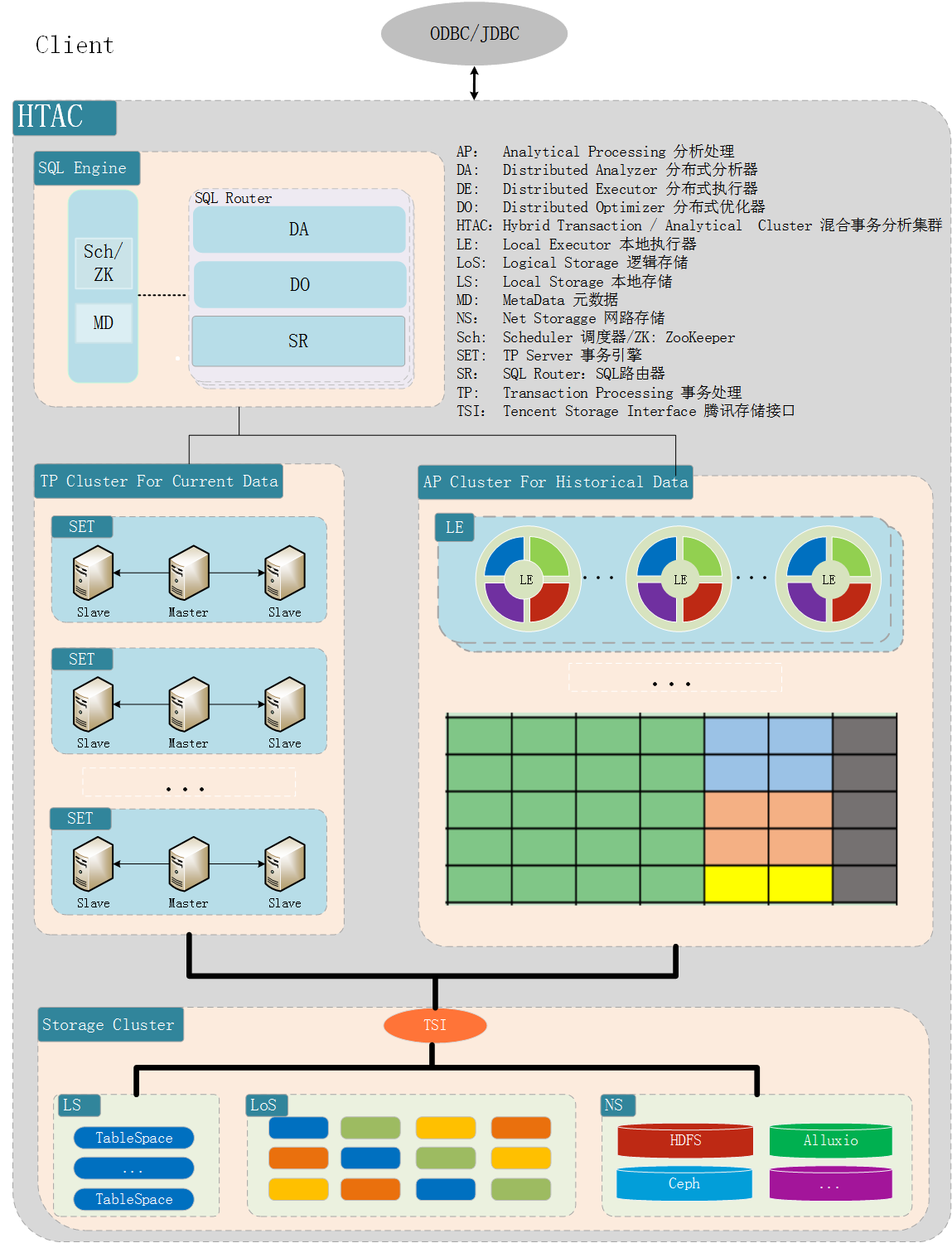
图 3 T-TDSQL 全时态数据库系统架构图
四 论文贡献
论文提出了一种拓展的时态数据模型。 除了在 SQL:2011 中定义的有效 / 事务时间属性外,本模型通过新引入的事务 ID 属性描述时间。 MIN_ID 与创建记录的事务相对应,MAX_ID 对应于删除 / 更新记录的事务。 事务 ID 能够识别在同一事务中插入 / 更新 / 删除的所有记录,从而实现由于业务逻辑破坏数据的修复。
论文提出了一种内建的时态数据库解决方案,并针对 TDSQL 进行了大量优化,最终实现了 TDSQL 全时态数据库系统。同时,该解决方案具有很强的通用性,可以方便的引入到其他数据库系统中。通过引入异步数据迁移、增量历史数据管理、原生时态查询执行器等策略,该解决方案具有轻量且高效的特点。
通过在真实场景和 TPC 基准负载下的大量实验,TDSQL 全时态数据库系统具有非常小的性能损失(相较于原始 TDSQL 系统),并且能够快速响应时态查询,与其他现有的时态数据库系统相比具有较好的性能。
五 系统测试
通过 TPCC 测试基准,论文展示了时态数据管理对原有系统性能的影响情况。如图 3 所示,在 256、512、1024 个数据仓库的场景下,基于 TDSQL 实现的全时态数据库系统的系统性能相较于原始 TDSQL 下降率不到 10%,领先于其他基于传统关系数据库实现的时态数据库系统。
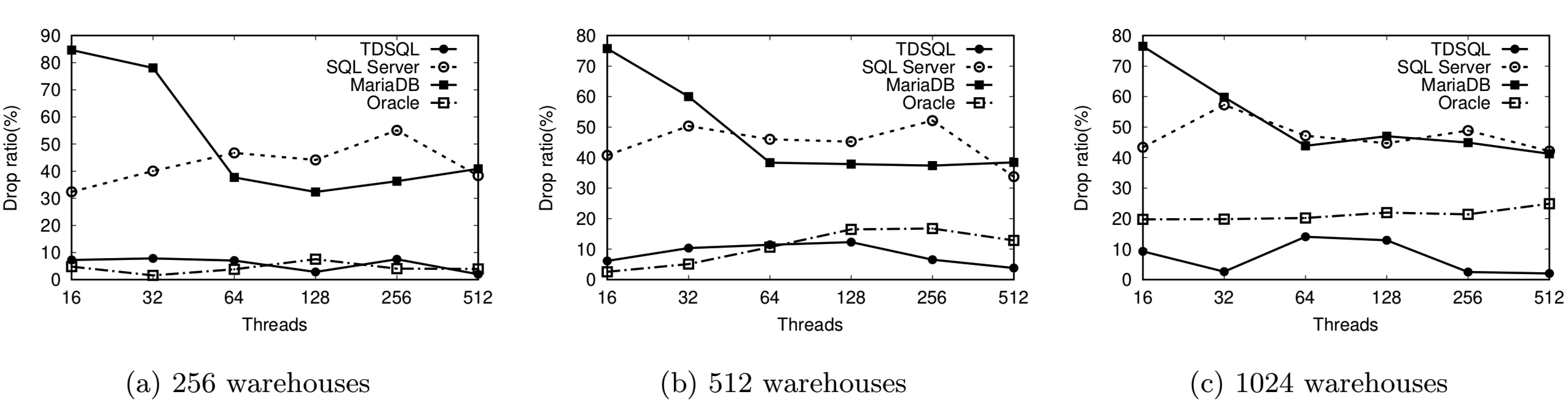
图 4 TPCC 测试结果
另外,基于真实的批处理业务场景,论文展示了系统在实际业务场景下的表现。如图 4 所示,通过连续 30 天对比原始系统和新型全时态数据库系统(T-TDSQL)在处理该业务时所需的执行时间,实验结果展示腾讯全时态数据库系统在简化业务应用开发的同时,可以缩短近一半的业务执行时间。
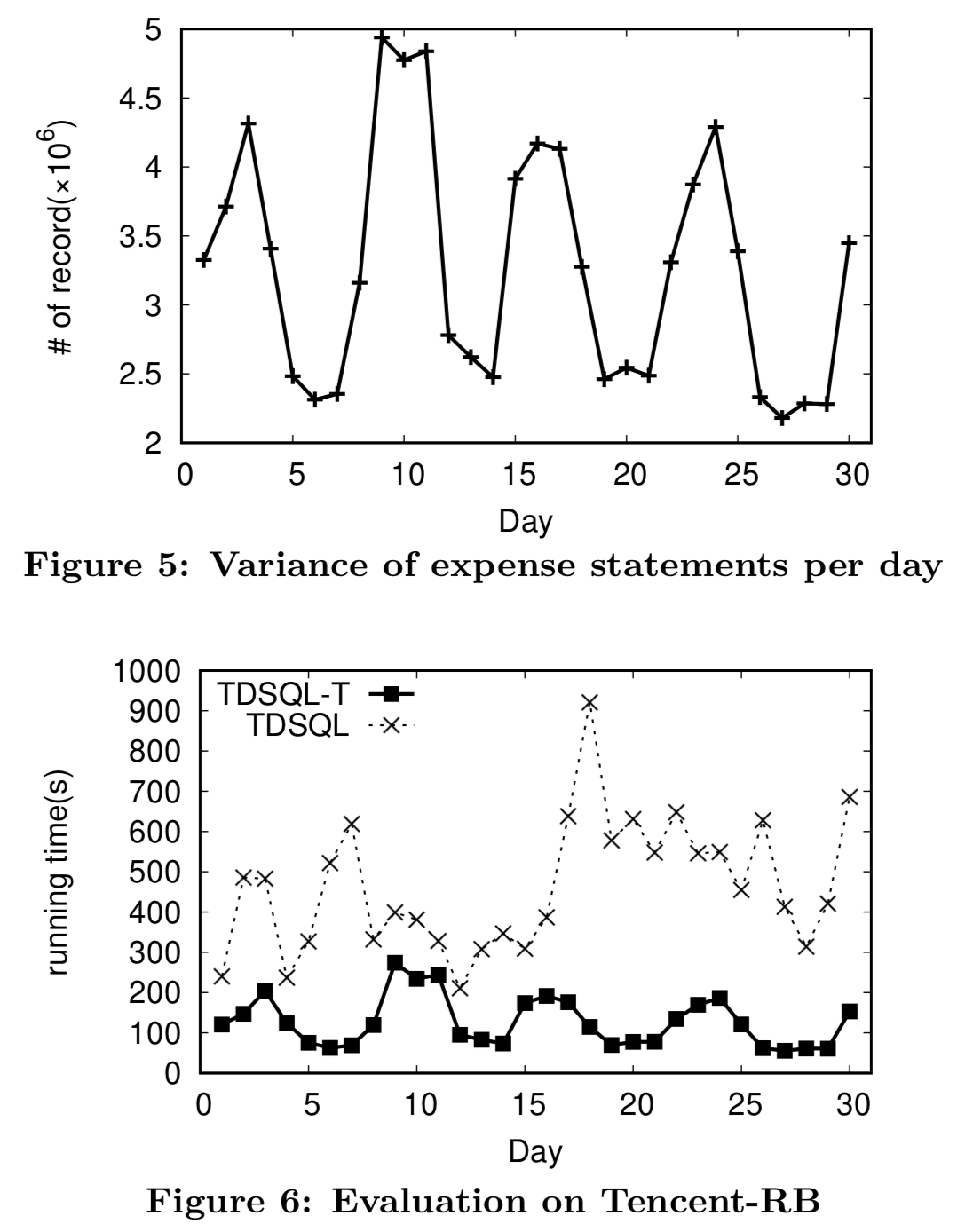
图 5 实际业务场景测试
对于该论文,VLDB 评审委员会做出如下点评:
This paper extends the TDSQL system from Tencent for temporal data management. A new temporal data model is proposed with optimized implementation. Extensive experimental study has been conducted to compare the performance with existing temporal database systems over benchmarks and real data.
六 TDSQL 全时态数据库的价值和意义
TDSQL 全时态数据库核心价值观是“历史数据富有价值”,核心理念是“为数据赋能”,因而系统提供了如下特性:
♦ 全时态数据模型。数据库系统通过统一的数据模型管理数据的生命周期,即数据的诞生、修改、消亡的全过程、过程中的状态变迁操作等。
♦ 全时态数据存储。全时态数据存储保证了所有状态数据的永久保存。解决了现有的数据库系统,大部分只能保存当前数据,而旧版本数据被丢弃的问题。
♦ 全时态数据查询。提供了对时态数据的快速查询能力,由于历史数据的数据量级巨大,在海量历史数据上的查询能力非常重要。
♦ 全时态数据计算。数据都是具有价值的,因此需要具备在海量时态数据上的分析计算能力。
TDSQL 全时态数据库的意义主要体现在功能和成本两个方面。从功能角度看,TDSQL 全时态数据库(用 T-TDSQL 表示)可以支持如下功能特性:
♦ 精确的历史数据读取。可以查询到对于历史上任意一个时间段内的数据变化情况,如新插入的数据、连续被更新的数据、以及被删除的数据。因此可以追踪数据的历史轨迹,并能方便的在增量数据的基础上进行多表连接的增量计算。
♦ 数据库中存储有数据的历史状态信息,数据的安全性得到保证。防止篡改数据、数据误删除的恢复、账户变化轨迹追踪、回溯历史时空里的“过去的”数据等功能,在 T-TDSQL 中成为现实。
♦ T-TDSQL 管理海量时态数据,因而流水日志不再重要。基于索引检索历史态数据时如同基于索引检索当前数据一样的方便快捷且消耗最少量的计算资源,这对于审计、安全、档案等部门有帮助。另外,HTAC 系统架构提供不受限于单机系统的存储能力,可以通过分布式网络文件系统来支持单机无限数据量的存储。
♦ T-TDSQL 还可以参与到数据关联分析的环节中,为数据赋予了事务时态、与用户的关联关系等,甚至还可以创造数据之间的关联关系以实现“数据血统”的产生等。
♦ 全时态数据为数据安全、数据重演、数据挖掘和 AI 技术的施展提供了物理基础。
致谢
本项目在腾讯 TEG 计费平台部立项,研究内容和实现过程得到中国人民大学数据工程和知识工程教育部重点实验室和腾讯公司的参与和支持,特别向项目参与人、支持者表示感谢。
标签: 全时态数据
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

