PinalyticsDB:基于HBase的时间序列数据库
2019-11-18 来源:raincent

作者:Pinterest Engineering 来源:InfoQ
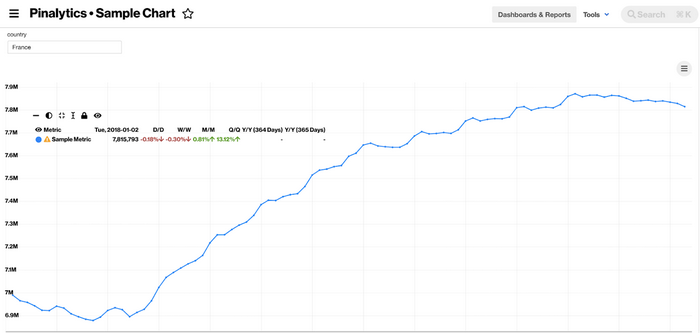
PinalyticsDB 是 Pinterest 打造的一套专有时间序列数据库。在 Pinterest,我们将 PinalyticsDB 作为后端以实现成千上万份时间序列报表的存储与可视化,例如下图所示案例(按国家与地区划分)。
我们在数年前以 HBase 为基础开发出 PinalyticsDB,其利用实时 map-reduce 架构通过 HBase 协处理器实现聚合。但随着 Pinterest 业务的持续增长以及报表数量的不断提升,PinalyticsDB 在处理庞大数据量及应用负载中开始遭遇一系列可扩展性挑战。
过去几个月以来,我们着手对 PinalyticsDB 进行重构,希望进一步提高其性能与可靠性水平。在本文中,我们将共同了解 Pinterest 面临的性能与可扩展性挑战,以及我们如何通过服务的重新设计构建出更为强大的 PinalyticsDB 新形态。
Hbase 区域服务器热点
随着 Pinterest 内平台使用量的快速提升,热点问题也开始成为 PinalyticsDB 区域服务器面临的一大挑战。在以往的设计中,PinalyticsDB 会为每份报表创建新的 HBase 表。
原有架构设计
原本的行键设计方案为:
原行键 = 前缀|日期|后缀
前缀 = 指标名称(字符串)
日期 =YYYY-MM-DD 格式,同样为字符串形式
后缀 = 由段号组成
行键由 ASCII 字符表示,其中“|”充当分隔符。
这套方案存在以下几个问题:
需要为每份报表创建一个新表,但由于某些报表的访问频率远超其他报表,因此承载这些报表的区域服务器将面对更多往来流量。
我们拥有成千上万份报表,因此 HBase 管理员基本不可能以手动方式监控报表并根据观察到的热点进行表拆分。
在单一报表之内,某些指标的使用频率可能较高。由于指标名称为行键的第一部分,因此导致热点数量进一步增加。
最近的数据使用趋势倾向于更频繁的访问操作,而日期则为指标后行键内容的组成部分,同样导致热点数量进一步增加。
以上提到的热点主要针对读取而言,但类似的热点在写入层面也同样存在,主要表现为某些报表表具有相对更高的写入次数,且指标数据始终会写入最新日期——这就导致各项指标的最新日期部分成为区域内的写入热点。
新的架构设计
我们通过改进行键架构与 HBase 表设计的方式解决了这个问题。我们利用以下行键设计创建出一份面向所有报表的表。
新的行键 = SALT | < 报表 -id> | < 指标 -id> | < 日期 - 时间 > | < 段 >
该行键以字节数组(byte[])形式表示,而不再使用字符串形式。

键内的各个部分都有固定的长度,作为定义行键的固定结构,同时也支持模糊行过滤器。
由于采用固定结构,因此我们不再需要“|”分隔符——这又进一步节约了空间资源。
对读取与写入操作的影响
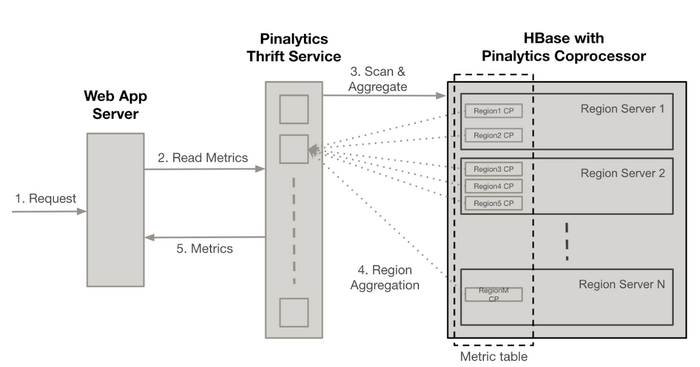
Pinalytics DB V2 读取架构

如大家所见,由于采用 salting 逻辑,读取在整个集群当中得到良好分发。更重要的是,写入操作在这套架构中的分发效果同样令人满意。
改进协处理器性能
我们还计划通过修改请求结构与协处理器扫描行为的方式,进一步优化 PinalyticsDB 协处理器的性能。我们的优化举措使得区域服务器 CPU 利用率、RPC 延迟以及 JVM 线程阻塞情况都得到显著改善。
我们的原始设计会针对发送至 PinalyticsDB 内每一项指标的对应请求创建 Hbase 扫描。Pinalytics 会持续收到大量同类请求,从而引发大量扫描操作。通过将与同一报表及指标相关的聚合请求合并起来,并对与所请求段相关的 FuzzyRowFilter 进行单一扫描,我们显著减少了实际产生的 Hbase 扫描次数。
在使用 Pinalytics 时,用户通过会发出大批量请求,这些请求当中包含的不同细份指标往往数量有限。下图所示为跨美国多个州段请求某一样本指标。
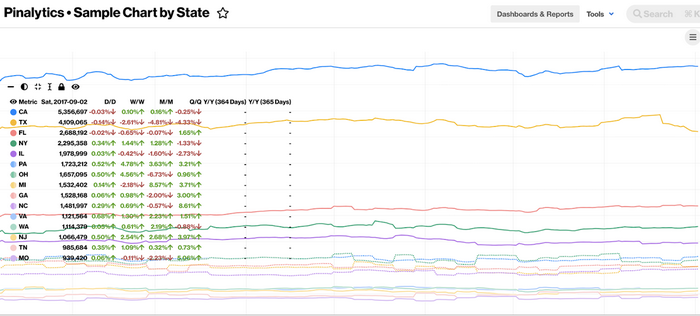
这是一类非常常见的用例。相当一部分用户使用的仪表板中都包含这类图表。
在这个用例的启发下,我们尝试进行“多细分优化”,即利用协处理器对与同一指标相关联的 PinalyticsRequest 中的所有细分执行一次扫描(每区域 salt)。
PinalyticsDB V2 韩国人协处理器设计
Pinalytics Thrift Server 将来自 Pinalytics 的全部请求按指标进行分组。接下来,协处理器会针对各个指标接收一条请求,其中包含与该指标相关的所有段 FuzzyRowFilters。
对于该协处理器区域内的各 salt,协处理器会创建一条 MUST_PASS_ONE 扫描,并在单一 FilterList 的聚合请求中包含所有 FuzzyRowFilters。
该协处理器随后按照日期与 FuzzyRowFilter 对所有扫描结合进行聚合,并将响应结果发送回 Thrift Server。
这意味着无论存在多少指向特定指标的不同段组合请求,我们都只需要处理一条指向该指标的聚合请求。
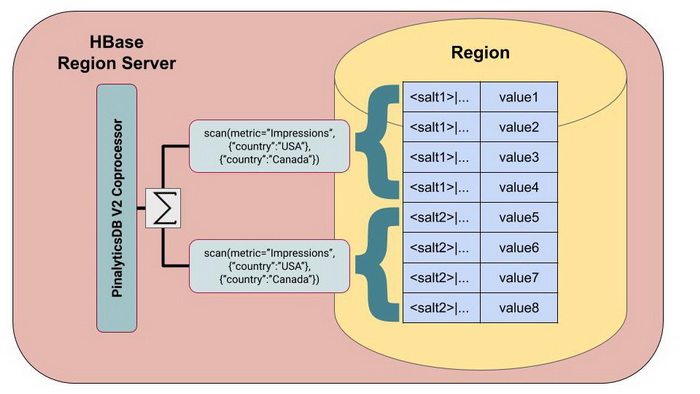
PinalyticsDB V2 协处理器设计:对于每种 salt,都只需要对指向同一指标的所有段创建一次扫描。
这一全新协处理器设计显著改善了区域服务器的 CPU 利用率、RPC 延迟以及 JVM 线程阻塞情况。
注意:下图所示为部署多段优化数小时后得到的捕捉结果,因此无法准确反映系统的当前性能。但总体来看,这些设计举措仍然有助于提高协处理器的性能表现。
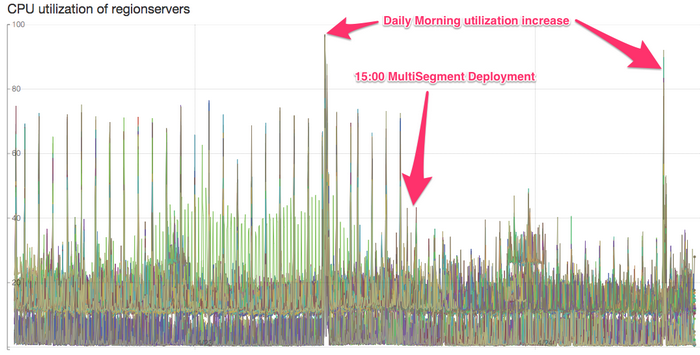
在部署新的协处理器后,区域服务器 CPU 利用率得到改善。
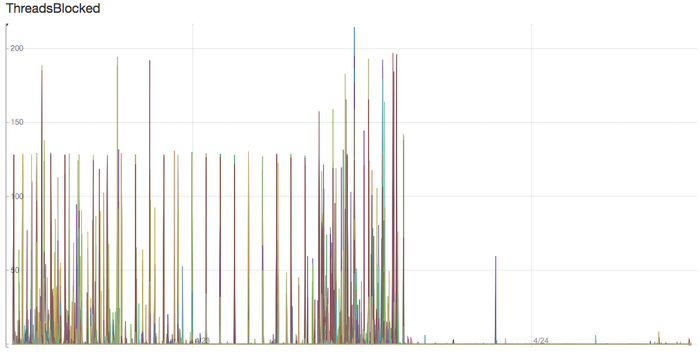
部署新的协处理器之后,区域服务器 JVM 线程阻塞情况得到改善。
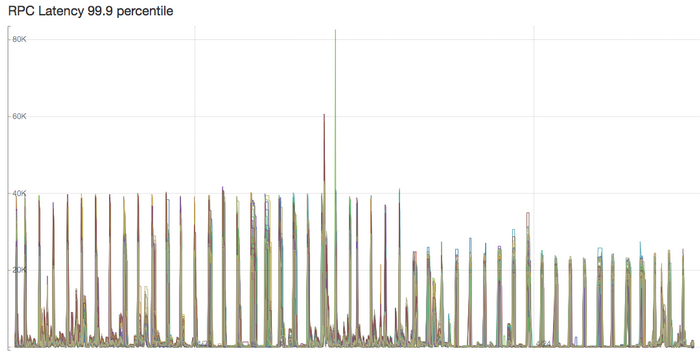
部署新的协处理器之后,区域服务器 RPG 延迟得到改善。
大型报表元数据与 Thrift Server OOM
我们的 Thrift Server 还存在 OOM 频繁崩溃的问题,如果这时用户尝试加载相关图表,那么就会发生 Web 应用程序超时的状况。这是因为 Thrift Server 的 jvm 没有设置 XX:+ExitOnOutOfMemoryError,因此 Thrift Server 无法退出 OOM,而继续调用只能产生超时。快速的解决办法是添加 XX:+ExitOnOutOfMemoryError 标记,以便在 OOM 生产 Thrift Server 上自动进行重启。
为了调试这个问题,我们将 jconsole 指向其中一台生产 Thrift Server,使其够捕捉到其他 Thrift Server 的崩溃情况。以下图表所示为总 heap、上一代与新一代架构的运行情况。
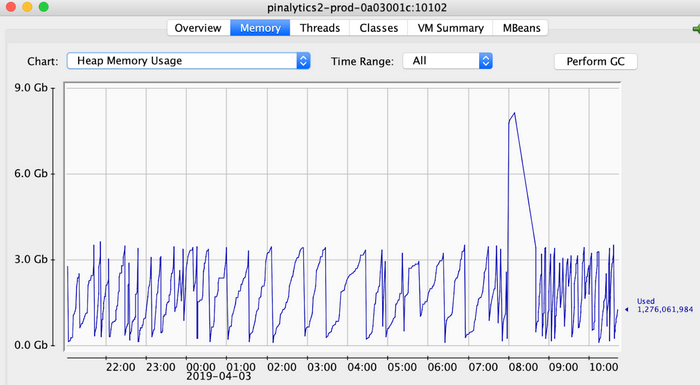
Thrift Server 的总 heap 内存为 8G。
请注意,内存使用量从低于 4G 突然提升至 8G 以上,引发问题的根源正是 OOM。
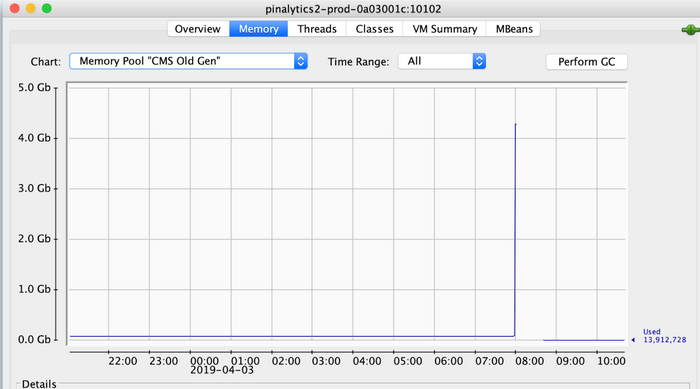
用于 PinalyticsDB Thrift Server 的上一代 CMS。
同样的,旧一代架构的内存使用量会突然猛增至 4G 以上,直接超出了系统极限。峰值出现得太快,CMS 收集器根本无暇介入,甚至连 full GC 都来不及出现。
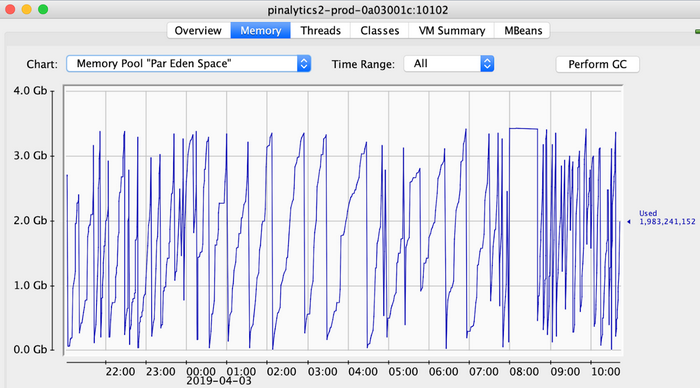
用于 PinalyticsDB Thrift Server 的 Eden 空间。
我们通过负载测试在开发环境当中重现这类问题,并最终确定问题根源与我们的报表元数据存储与读取机制有关。对于大部分报表而言,元数据一般仅为数 KB。但对于某些大型报表,元数据可能超过 60 MB,甚至高达 120 MB。这是因为此类报表中可能包含大量指标。
报表元数据结构
以下为单一报表中的元数据。报表元数据存储在一个专门的二级索引表当中。
#!/usr/bin/python
# -*- coding: utf-8 -*-
ReportInfo(
tableName=u’growth_ResurrectionSegmentedReport’,
reportName=u’growth_ResurrectionSegmentedReport’,
segInfo={
u’segKey2': u’gender’,
u’segKey1': u’country’,
u’segKeyNum’: u’2',
},
metrics={u’resurrection’: MetricMetadata(name=u’resurrection’,
valueNames=None),
u’5min_resurrection’:MetricMetadata(name=u’5min_resurrection’
, valueNames=None)},
segKeys={
1: {
u’1': u’US’,
u’2': u’UK’,
u’3': u’CA’,
…
}
)

优化表元数据的存储与检索使用
报表元数据以序列化 blob 的形式存储在 HBase 的二次索引表中。因此,可以判断问题的根源在于报表元数据的体量太大,而我们每次都在加载完整元数据——而非仅加载我们需要使用的部分。在高负载情况下,jvm leap 可能会很快被填满,导致 jvm 无法处理汹涌而来的 full GC。
为了从根本上解决问题,我们决定将报表元数据内容分发至报表行键下的多个列族与限定符当中。

经过增强的 PinalyticsDB V2 报表行键结构,分布在多个列族与限定符之间。
行键采用原子更新,因此所有列族都将在单一 PUT 操作时以原子化方式更新。
我们还创建了一种新的 report-info 获取方法。
getReportInfo(final String siTableName, final String reportName, List<String> metrics)
此方法会返回所有 seg-info 与 seg-keys 数据,且仅返回“metrics”列族中的相关指标数据。由于报表的大部分内容基于指标数据,因此我们只需要返回几 kb 数据,而非完整的 100 mb 以上数据。
Thrift Server 轮循池
我们还对 Thrift Server 做出另一项变更,旨在实现可扩展性。每个 Thrift Server 都具有 hbase org.apache.hadoop.hbase.client.Connection 的单一实例。
hbase.client.ipc.pool.size=5
hbase.client.ipc.pool.type=RoundRobinPool
每个区域服务器默认只拥有 1 个连接。这样的设置增加了并发连接数,且有助于我们进一步扩展每个服务器的请求数量。
缺点与局限
通过以上设计,我们的业务体系运行得更为顺畅。但我们也意识到,其中仍存在一定局限性。
虽然横向扩展架构带来了均匀的读取写入分布,但却会对可用性造成影响。例如:任何区域服务器或者 Zookeeper 问题,都会影响到全部读取与写入请求。我们正在设置一套具有双向复制能力的备份集群,从而在主集群发生任何问题时实现读写机制的自动故障转移。
由于各个段属于行键的一部分,因此包含多个段的报表必然占用更多磁盘存储空间。在创建报表后,我们也无法对报表内的细分内容进行添加或删除。此外,尽管能够快速转发 FuzzyRowwFilter,但对于基数很高的报表及大量数据而言,整个过程仍然非常缓慢。相信通过在协处理器中添加并发机制,从而并发执行对每种 salt 的扫描(甚至按日期进行分区扫描),能够有效解决这个问题。
这套架构利用协处理器执行读取,但不支持利用协处理器复制读取内容。接下来,我们可以通过将结果存储在高可用性表中实现对缓存层的聚合,从而在一定程度上弥补这种协处理器复制能力缺失问题。另外,我们还会在无法从主区域处读取数据时,执行副本读取操作(利用常规 Hbase 扫描,不涉及协处理器)。
我们计划在下一次迭代当中解决一部分局限性问题。此外,我们还计划添加对前 N 项、百分位、按…分组以及 min/max 等函数的支持。
鸣谢:
感谢 Rob Claire、Chunyan Wang、Justin Mejorada-Pier 以及 Bryant Xiao 为 PinalyticsDB 支持工作做出的贡献。同样感谢分析平台与存储 / 缓存团队为 Pinalytics Web 应用以及 HBase 集群提供的宝贵支持。
原文链接:
https://medium.com/pinterest-engineering/pinalyticsdb-a-time-series-database-on-top-of-hbase-946f236bb29a
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

