5个机器学习开源项目来挑战你的数据科学技能!(附链接)
2020-12-04 来源:raincent

5个富有挑战性的机器学习开源项目帮你找到2020的正确打开方式,以下机器学习项目涉及多个领域,包括Python编程及自然语言处理。
简介
越来越多的人开始踏入数据科学领域。不管你是应届毕业生、初入职场者,还是有一定相关经验的专业人士,亦或是机器学习的爱好者 – 任何人都想搭上数据科学的快车。
机器学习
https://courses.analyticsvidhya.com/courses/applied-machine-learning-beginner-to-professional?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
如果你来自印度,相信你一定读过有关政府在数据领域投资的消息(2020年联邦预算)。当下是个投资自己的绝佳时机。
在许多开启自己数据科学生涯的绝佳方式中,投资自己是其中之一。以下是一个简化的流程:
找到你所感兴趣的机器学习开源项目。
对于该项目,了解当前领先的解决方案。
如果有相关的解决方案,从中汲取知识。但如果这种方案并不存在,就利用你所掌握的机器学习知识来创造一个。

我挑选出了5个机器学习开源项目(创建于2020年1月)来帮助你了解行业领先的框架和库。同往常一样,我尽可能保证这些项目的多样性。你会注意到其中包括一些取自自然语言处理和Python编程的想法。
如果你对以往月刊系列展示的项目感兴趣,下方已放置链接。这个系列已经创办三年了 – 要对我们社区铺天盖地的响应表示感谢!
https://www.analyticsvidhya.com/blog/category/github/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
目录
1. Reformer – PyTorch里的高效Transformer
2. PandaPy – 你最爱的Python库
3. 谷歌地球引擎 – 用300多个Jupyter笔记本来分析地理空间数据
4. AVA – 自动化视图分析
5. Fast Neptune – 你的机器学习项目加速器
谷歌地球引擎 – 用300多个Jupyter笔记本来分析地理空间数据
https://github.com/giswqs/earthengine-py-notebooks
Fast Neptune – 你的机器学习项目加速器
https://danywind.github.io/2020/01/28/fast-neptune.html
回归正题,以下是5个机器学习开源项目。

Reformer – PyTorch里的高效Transformer
https://github.com/lucidrains/reformer-pytorch
Transformer架构的出现改变了自然语言处理。越来越多的自然语言处理框架开始进入大众视野,例如BERT, XLNet, GPT-2.
自然语言处理
https://courses.analyticsvidhya.com/courses/natural-language-processing-nlp?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
自然语言处理框架
https://www.analyticsvidhya.com/blog/2019/08/complete-list-important-frameworks-nlp/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
BERT
https://www.analyticsvidhya.com/blog/2019/09/demystifying-bert-groundbreaking-nlp-framework/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
GPT-2
https://www.analyticsvidhya.com/blog/2019/07/openai-gpt2-text-generator-python/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
但也存在一个问题 – 这些基于Transformer的模型实在是太大了。它们的确实现了行业领先的结果,但成本高的同时,对于大部分仅仅想学习并使用它们的人来说,这些框架超出了他们的能力范围。
“Reformer模型,它和Transformer模型一样优秀,而且它占用的资源和成本更少”
上面的Github链接包含了利用PyTorch搭建Reformer的方法。除了完整的代码,该项目的作者还提供了一个简单且高效的例子来帮助你建模。
我强烈建议你先读一篇关于Reformer的内部原理的官方研究。
https://openreview.net/pdf?id=rkgNKkHtvB
你可以通过这个指令在你的机器上安装Reformer。
pip install reformer_pytorch
如果你还不了解Transformer架构和PyTorch框架,建议先阅读一下文章。
How do Transformers Work in NLP? A Guide to the Latest State-of-the-Art Models
https://www.analyticsvidhya.com/blog/2019/06/understanding-transformers-nlp-state-of-the-art-models/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
A Beginner-Friendly Guide to PyTorch and How it Works from Scratch
https://www.analyticsvidhya.com/blog/2019/09/introduction-to-pytorch-from-scratch/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
PandaPy – 你最爱的Python库
https://github.com/firmai/pandapy
上周我刚刚熟悉了一下PandaPy并在我当前项目里加以运用。它是个很神奇的Python库,将来很有可能成为主流。
如果你的机器学习项目涵盖了很多混合数据类型(int,float,datetime,str等等),你真的应该尝试一下PandaPy而不是Pandas。相比于Pandas,用PandaPy处理混合数据类型能为你节省三分之一的内存。
“如果你在生产环境里使用较小的Pandas数据帧(5万以内),那你应该尝试替换成PandaPy。”

以下三点你会觉得很有趣(这些都是PandaPy的Github上的原话):
在小数据集上进行简单计算时(例如加法、乘法、取对数),PandaPy比Pandas快25至80倍。
在小数据集上进行表操作时(例如聚合、透视、删除、合并、填充缺失数据),PandaPy比Pandas快5-100倍。
在大多数小数据使用情况下,PandaPy比Dask,Modin Ray和Pandas都要快。
通过pip安装PandaPy:
!pip3 install pandapy
如果你对Pandas依旧念念不忘,在这里你能找到最新正式版本(v1.0.0)。
https://www.analyticsvidhya.com/blog/2020/01/pandas-version-1-top-4-features/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
谷歌地球引擎 – 用300多个Jupyter Notebook来分析地理空间数据
https://github.com/giswqs/earthengine-py-notebooks
这个Github库极其优秀!有很多有抱负的数据科学家在领英上向我询问如何着手进行地理空间分析。这是一个拥有千兆数据的有趣领域。我们仅仅需要一个结构化的方法来清理分析这些数据。
“这个库囊括超过300个Jupyter Notebook,其中包含了如何使用谷歌地球引擎数据的例子”
谷歌地球引擎
https://earthengine.google.com/
这是一个炫酷的GIF图片,它展示了一个通过这些Notebook能得到的可视化视图:
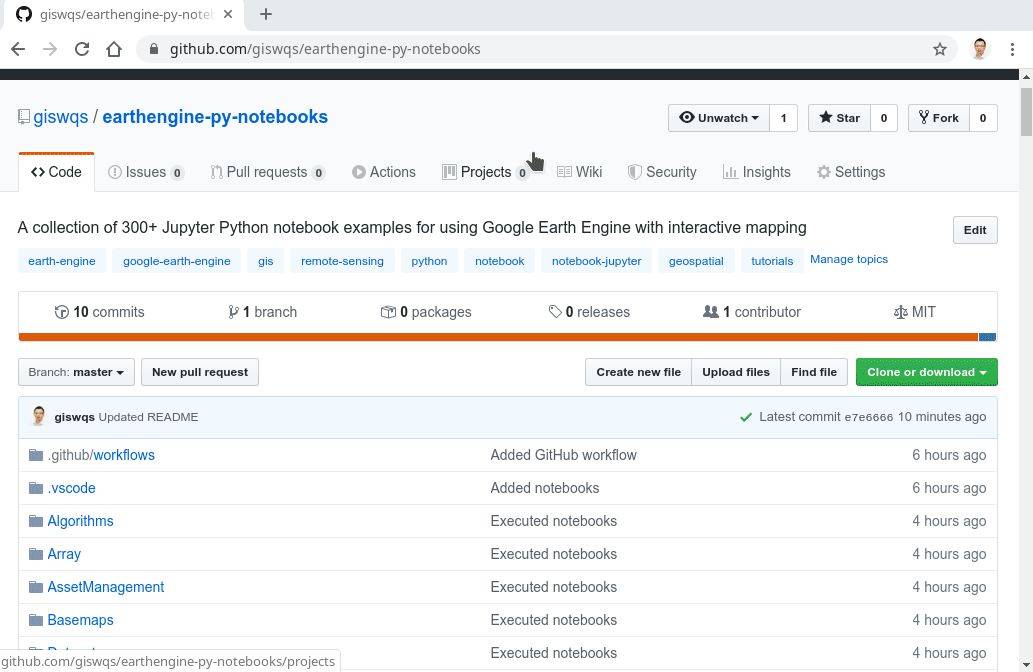
这些Notebook主要基于三个Python库来运行代码:
Earth Engine Python API
Folium
Geehydro
这个Github库有大量的Python例子能够帮你上手。好好研究一下,玩得开心!
这还有一篇很优秀的文章能帮你上手地理空间数据:
Geospatial Data and its Role in Data Science
https://medium.com/analytics-vidhya/geospatial-data-and-its-role-in-data-science-c60b2e0d3f7f
AVA – 自动化视图分析
https://github.com/antvis/AVA
还有一个很优秀的数据可视化概念。数据发掘自动化的想法已经流传一段时间了,但一直没有实质性的框架出现。直到现在:
“AVA,自动化视图分析的简写,是阿里巴巴为了让视图分析更智能化和自动化所创造的框架。”
下面这个GIF图片是AVA的演示:
我强烈推荐你了解下面的资源,它们能帮你创建和加强数据可视化简介:
Mastering Tableau from Scratch: Become a Data Visualization Rockstar
https://courses.analyticsvidhya.com/courses/tableau-2-0?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
Collection of Data Visualization Articles and Tutorials
https://www.analyticsvidhya.com/blog/tag/data-visualization/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
Fast Neptune – 你机器学习项目的加速器
https://danywind.github.io/2020/01/28/fast-neptune.html
现如今,不论是学术界还是工业界,生产力是任何一个机器学习项目的重要指标。我们需要追踪每一个测试、每一次迭代,以及每对参数和结果。
“Fast Neptune库能够快速记录开展机器学习测试所需的所有信息。也就是说,Fast Neptune是上文所提及的生产力问题的答案。”
Fast Neptune有几个特性能够帮我们进行快速测试(从上文链接里引用):
有关运行代码的机器的元数据,包括系统及系统版本。
对测试所在的Notebook的相关要求。
在测试过程中用到的参数,也就是你想追踪的变量的值的命名。
测试过程中你想记录使用的代码。
是不是很直观?你只用一行代码就可以安装Fast Neptune:
pip install fast-neptune
几个值得关注的框架:
我还想介绍其他几个2020年1月发行的框架,你应该关注一下:
1. Thinc:这是一个spaCy作者制作的轻量化深度学习库。Thinc“为composing model提供一个优雅、能够类型检查、功能化编程的接口,同时为其他框架定义的层提供支持,例如PyTorch,TensorFlow或者MXNet”
Thinc
https://thinc.ai/
spaCy
https://www.analyticsvidhya.com/blog/2019/09/introduction-information-extraction-python-spacy/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
PyTorch
https://www.analyticsvidhya.com/blog/2019/09/introduction-to-pytorch-from-scratch/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
TensorFlow
https://www.analyticsvidhya.com/blog/2016/10/an-introduction-to-implementing-neural-networks-using-tensorflow/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
2. 谷歌仿人类生成聊天机器人:谷歌创造的Meena是一个拥有26亿参数点对点训练的神经交谈式模型。相比于行业领先的聊天机器人,Meena能够引导更合理更具体的对话。谷歌会开源Meena的代码吗?我们还不得而知,但这是个值得关注的事。
谷歌仿人类生成聊天机器人
https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
结束语
2020是机器学习快速发展的一年。先进技术会继续快速进化,以至于让新手难以快速上手。
这也是我发表这些月刊的初衷,把最有相关性和实用性的开源机器学习项目带给我们的社区。
你有没有其他想了解的机器学习项目或框架?我非常想在下面的评论区听听你的想法和主意。让我们一起头脑风暴。
你也可以通过Analytics Vidhya的安卓软件阅读这篇文章。
原文标题:
5 Open Source Machine Learning Projects to Challenge your Inner Data Scientist
原文链接:
https://www.analyticsvidhya.com/blog/2020/02/5-open-source-machine-learning-projects-data-scientist/
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

