Hadoop云服务之战:微软vs.亚马逊
2018-06-11 来源:

毫无疑问,Apache Hadoop软件库拥有当今最多的大数据分析思想。Gartner在2012年三月的报告中指出Hadoop作为一个流行的搜索词,在网站上的搜索量已经比2011年增加了601.8%。Hadoop逐渐普及的背后主要的驱动力在于大数据和社交计算的炒作,广泛的企业级开源软件应用,拥有Hadoop熟练技能的开发人员资源池以及Hadoop可以用预期达成的性能以低廉的商业服务器集群成本交付高可用性。后面的这个性能让企业能够将Hadoop工作负载部署到IaaS和PaaS提供商的云上,代替数据中心资本投资中的几次付费费用。
Apache软件基金会将Hadoop描述为:
Apache Hadoop项目是用以开发可靠、可扩展且分布式的计算的开源软件。
Apache Hadoop软件库是一种通过使用简单的编程模型,跨计算机集群的大型数据集分布式处理框架。旨在从单一服务器扩展到成千上万的机器,每一个产品本地计算并存储。而不是依赖于硬件来交付高可用性,该软件库本身旨在检测和处理应用层的失败,从而交付计算机集群顶层的高可用性服务,每一个都可能发生故障。
商业开源分布式软件,像红帽Enterprise Linux,属于企业级不可或缺的。Cloudera领先的商业Hadoop分布式用免费增值模式,提供了免费的Cloudera Distribution for Hadoop (CDH),但是需要对支持和Cloudera Manager应用许可证。因为其商业模式和市场支配,Cloudera成为很多“红帽Hadoop”的使用者的考虑对象。Yahoo!经典的Hadoop开发者,已经改变了野蛮,但是Cloudera却在出售其“Hadoop圣经。”因此Yahoo!于2011年六月甩掉了其Hadoop工程师团队,进入Hortonworks,Benchmark资本投资的一个新的实体,来获取Hadoop的收益,从而与Cloudera竞争。Cloudera2012年三月宣布同IBM合作,将其CDH、Cloudera Manager同本地的IBM BigInsights平台整合,并放入IBM的公有SmartCloud服务中。
亚马逊的弹性MapReduce
亚马逊Web服务(AWS)于2009年4月2日引入了弹性MapReduce服务(EMR),让AWS成为基于云的Hadoop服务的祖父。EMR使用按需的EC2实例集群处理存储于S3或者DynamoDB中的数据。专业的按需EMR实例陈本范围从小型的每小时0.105美元到每小时0.864美元的大型Hi-CPU实例,包括EMR额外的费用。S3和Dynamo DB存储为标准的按月付费,每GB数据传输到亚马逊数据中或者从亚马逊数据中心输出都适用。你可以按每小时付费或者你实际运行的实例付费。
AWS在EMR开始手册中提供了代码示例和教程,介绍在Linux、UNIX以及Windows语法中,通过EMR Command Line Interface (CLI)创建Streaming Job Flow。或者你可以适用Hive和亚马逊EMR工作流创建和执行一个简单的Contextual Advertising,如图一所示,EMR Management Console,链接中的博客描述了细节。

图一图解自动化弹性MapReduce和Hive工作流。你可以从CLI或者AWS管理控制台运行交互的Hive会话。
这篇文章对比了用AWS Management Console(图二)创建Hive工作流,而不是CLI,因为微软的Apache Hadoop on Windows Azure (AHoWA)服务包括了交互式Hive控制台,性能类似。Apache基金会将Hive描述为:
Hive是一个Hadoop的数据仓库系统,促进简化数据摘要、临时查询和存储在Hadoop兼容文件系统中的大型数据集的分析。Hive提供了数据之上项目结构以及使用类SQL语言HiveQL查询数据的一种机制。同时,HiveQL中不方便或者表达不清这个逻辑时,该语言可以让传统的map/reduce程序员插入其自定义的mappers和reducers。
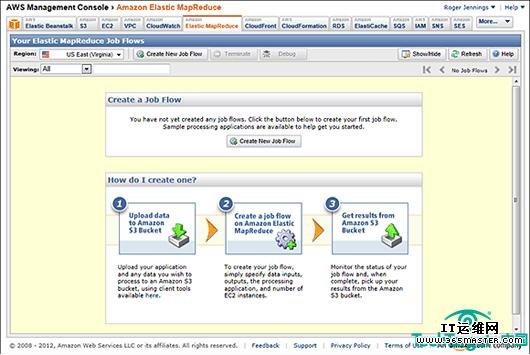
图二,AWS Management Console下Elastic MapReduce选项创建Job Flow页面。点击Create New Job Flow按钮,可以选择Contextual Advertising示例HiveQL声明,转换ad-server impression数据到Hive表中。此外,MapReduce操作生成汇总广告效率的顺序文件。
2012年5月31日,AWS升级EMR到最新的Hive版本(0.8.1)中。Hive能够翻译HiveQL声明到MapReduce操作中并在执行这个操作,相反本地文件中湖综合公有云数据存储(比如亚马逊 S3或者Windows Azure blobs)的Hive表中的数据也是。例如,下面示例的HiveQL声明创建了一个名为impressions的Hive表,在SerializeDeserialize (serde)格式中有七个字段,从S3中JavaScript Object Notation (JSON)格式存储的ad-server impression日志文件……/表/ impressions folder:
CREATE EXTERNAL TABLE impressions (
requestBeginTime string
adId string,
impressionId string,
referrer string,
userAgent string,
userCookie string,
ip string )
PARTITIONED BY (dt string)
ROW FORMAT
serde 'com.amazon.elasticmapreduce.JsonSerde'
with serdeproperties ( 'paths'='requestBeginTime, adId,
impressionId, referrer,
userAgent, userCookie, ip' )
LOCATION '${SAMPLE}/tables/impressions' ;
Contextual Advertising工作流运行之前的声明,存储在S3脚本文件中,从而为后来的分析创建Hive表。第二个CREATE EXTERNAL TABLE声明生成一个点击表,从ad click日志数据和另一个impressions和clicks联合的表。如果你使用推荐的大型实例,每个实例每小时0.42美元,需要一个关键或者两个核心实例,成本是1.26美元。使用默认的小型实例,成本降到0.315美元。小型实例整个执行时间大约是20分钟。整个执行完成后,管理控制台停止运行所有实例。
进一步的操作会生成一个功能主页表,可以用于计算一个广告的点击估价。以S3脚本的形式存储这些估价HiveQL声明,选择一个而你不是第二步中的工作流处理示例脚本,在管理控制台的S3选择项中查看作为结果生成的S3文件。
微软的Apache Hadoop on Windows Azure服务预览
2011年12月14日SQL Server大数据团队发布了Apache Hadoop on Windows Azure服务商业技术预览(CTP)版本的邀请码,该团队期望在2012年初公诸于众。微软同Hortonworks合作,创建服务,提供核心的Hadoop/MapReduce功能、JavaScript库,可以用JavaScript编写MapReduce程序,用标准的Web浏览器运行工作,以及一个交互的JavaScript/Hive 控制台来编写和执行HiveQL声明。分析师使用Excel和其他的微软商业智能(BI)工具可以下载一个Hive ODBC驱动和Excel插件,允许他们用BI工具,比如PowerPivot和PowerView,发布HiveQL查询到分析结构或者非结构的Hadoop数据。预期AHoWA 用户必须通过邀请码邮件填写一个简要的调查。通过邀请码登录到AHoWA 网站,打开Request a New Cluster 页面(图三所示)。在预览期间没有AHoWA 资源消耗费用。然而,集群48小时候回收;你可以在24小时内重新创建一个,其生命周期持续6小时。

图三,AhoWA网站的Metro-ized Create a New Cluster页面。制定一个唯一的DNS命名,选择一个集群大小并提供管理认证,启用Request Cluster按钮。分配一个大型集群的一个集群头和四个工作结点只需要几分钟。
创建了集群后你可以运行九个示例Apache MapReduce中的一个,Pig、Sqoop和Mahout项目。或者你可以设置Windows Azure Marketplace Datamarket产品,Windows Azure对象容器或者亚马逊S3文件所谓数据源,放入Hive表中,具体的介绍详见链接的博客(图四)。
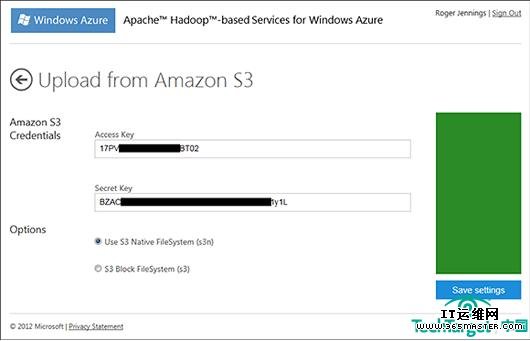
图四,从亚马逊S3表格上传。Manage Cluster页面的启动S3按钮打开这个表格,需要你的AWS Access Key和Secret Key进行验证。你为S3数据源文件选定具体的URL进入到HiveQL声明中。
下面的HiveQL声明键入在文本框中的数据显示区域,创建了一个本地功能主页Hive表,以Hadoop SEQUENCEFILE的格式有四列,用于后来的查询:
CREATE EXTERNAL TABLE feature_index (
feature STRING,
ad_id STRING,
clicked_percent DOUBLE )
COMMENT 'Amazon EMR Hive Output'
STORED AS SEQUENCEFILE
LOCATION 's3n://oakleaf-emr/hive-ads/output/2012-05-29/feature_index';
点击Evaluate按钮执行这个声明,大约四秒的时间内清空文本框并创建一个链接到数据源(见图五)。从S3数据源中选择查询下载数据。

图五,去人HiveQL查询的执行。查看工作日志需要一个远程桌面协议(RDP)连接到Azure High Performance Cluster中。
创建一个Hive表,增加其名称到表格列表中,命名列到列列表中,执行SELECT * FROM feature_index LIMIT ,20个查询结果显示出来,这是最先的20个结果(见图六)。
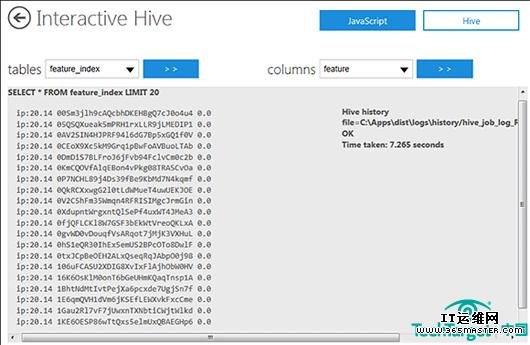
图六,第一个20行。花了7.265秒来执行一个简单的HiveQL SELECT查询,由于互联网延迟和相对较低的DSL连接。
AWS的Contextual Advertisin中的“Applying the Heuristic”部分建议执行下面的示例HiveQL查询对抗功能主页表“功能'us:safari' and 'ua:chrome'如何执行”:
SELECT ad_id, -sum(log(if(0.0001 > clicked_percent, 0.0001, clicked_percent))) AS value
FROM feature_index
WHERE feature = 'ua:safari' OR feature = 'ua:chrome'
GROUP BY ad_id
ORDER BY value DESC
LIMIT 100;
根据文章:
结果就是通过试探性的偶然点击排序广告。在这一点上,我们查阅广告,假设苹果产品的优势。
图七展示了执行之前查询的结果,展示了最高点击率的广告:
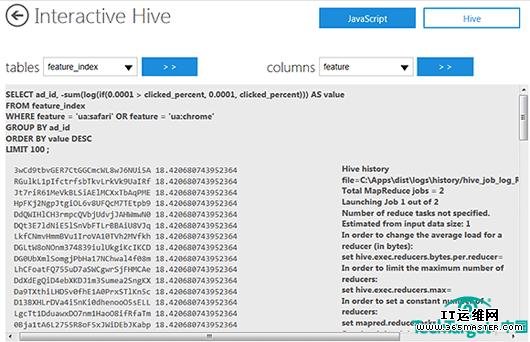
图七,返回的100个最高点击率的第一个15行。Hive History数据并没有显示出来,期间两个MapReduce工作已经执行。
如果你对于集成PowerPivot和Excel,通过交互Hive控制台生产数据感兴趣,看看我的《Using Excel 2010 and the Hive ODBC Driver to Visualize Hive Data Sources in Apache Hadoop on Windows Azure》一文。为了给控制台进行Windows Azure对象测试作为数据源,看《Using Data from Windows Azure Blobs with Apache Hadoop on Windows Azure CTP》一文。
总结
与微软的AhoWA相比,亚马逊的EMR是一个经验丰富的Hadoop/MapReduce老手,AhoWA让是预览阶段。二者都提供了Apache Hadoop完全详细的核心功能,但是AhoWA用其交互式Hive和JavaScript控制台赢得了可用性。如果你的分析团队使用Excel或者其他的微软BI工具,Hive ODBC驱动和Excel Hive Ad-In在增加性能方面就是赢家。
标签: dns linux 标准 大数据 大数据分析 代码 服务器 服务商 公有云 互联网 脚本 开发者 企业 数据分析 搜索 网站 选择 用户
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

