
IE上的The valid characters are defined in RFC…
2018-06-18 00:08:30来源:未知 阅读 ()

前言
参照:https://blog.csdn.net/qq_28165595/article/details/79686681
日常开发中经常遇到一些莫名其妙的小问题,例如即将上线的项目在线上异常报错,但是在本地确可以正常运行。往往这猝不及防的小惊喜,真是让我们猿猿欲哭无泪啊。这里简单总结一下在IE浏览器上遇到的一个小坑,之前就因为这个小坑,着实慌了一把。
坑的由来
首先瞅瞅这坑长啥样子。如下图所示 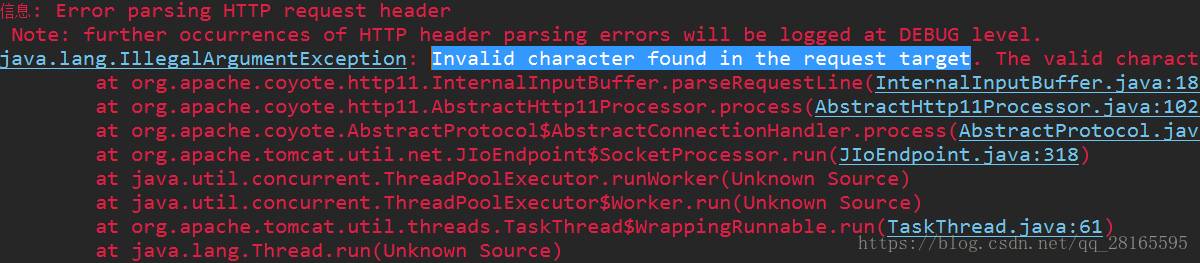
上面的图片中,我们明确看到这样一行Invalid character found in the request target. The valid characters are defined in RFC 7230 and RFC 3986,这句话的大致意思就是说请求头中包含了 RFC 7230 and RFC 3986规范中定义的非法字符。在这种情况下就会导致页面报400异常。
触发上面报这种异常的代码片如下,只是一个简单的get请求

接下来我们来看看RFC 3986中到底是怎么规范的
RFC3986文档规定,Url中只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~4个特殊字符以及所有保留字符。RFC3986文档对Url的编解码问题做出了详细的建议,指出了哪些字符需要被编码才不会引起Url语义的转变,以及对为什么这些字符需要编码做出了相应的解释。
US-ASCII字符集中没有对应的可打印字符:Url中只允许使用可打印字符。US-ASCII码中的10-7F字节全都表示控制字符,这些字符都不能直接出现在Url中。同时,对于80-FF字节(ISO-8859-1),由于已经超出了US-ACII定义的字节范围,因此也不可以放在Url中。
保留字符:Url可以划分成若干个组件,协议、主机、路径等。有一些字符(:/?#[]@)是用作分隔不同组件的。例如:冒号用于分隔协议和主机,/用于分隔主机和路径,?用于分隔路径和查询参数,等等。还有一些字符(!$&’()*+,;=)用于在每个组件中起到分隔作用的,如=用于表示查询参数中的键值对,&符号用于分隔查询多个键值对。当组件中的普通数据包含这些特殊字符时,需要对其进行编码。
RFC3986中指定了以下字符为保留字符:! * ’ ( ) ; : @ & = + $ , / ? # [ ]
不安全字符:还有一些字符,当他们直接放在Url中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符,原因有很多。
空格:Url在传输的过程,或者用户在排版的过程,或者文本处理程序在处理Url的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉。
引号以及<>:引号和尖括号通常用于在普通文本中起到分隔Url的作用
井号(#) 通常用于表示书签或者锚点
%:百分号本身用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码
{}|\^[]`~:某一些网关或者传输代理会篡改这些字符
同时RFC 3986规范在tomcat7.0.73版本中就已经提出了,RFC 7230也是对前者的一些补充或者说是完善,所以在tomcat7.0.73及以上版本都会有这种问题。
如何填坑
解决上面问题,有如下几种思路。
- 换用低版本的tomcat,既然你是tomcat7.0.73版本,及以上版本有这种问题,我们可以暂时的逃避这个问题,选择低版本的tomcat。
- 用post代替get请求,上面也说过了是get请求才会有这种情况,如果方便的话,我们完全可以采用post请求来实现这个功能
-
在前端对前端URL进行编码
下面介绍一下前端对URL进行编码的实现方法。
javascript可以使用的内置函数有 - encodeURI()
- encodeURIComponent()
他们都是用utf-8的编码方式,对于get请求,他的编码格式默认是按照浏览器的编码格式进行编码的,我们可以设置浏览器的编码格式,但是每个用户的浏览器的编码格式不可能都是一致的,这样我们的get请求的参数有时候就会出现乱码问题,但是如果我们自己在前端对get请求利用encodeURI()或者encodeURIComponent ()来统一设置成utf-8编码,这样我们在后台在用utf-8来解码,就不会出现乱码问题。
这里需要注意的一点,对于get请求的中文乱码问题,如果你没有在tomcat配置文件中设置编码格式,天真的想用request.setCharacterEncoding(“UTF-8”)来在后端设置后端的解码格式,这种方式对于get请求是无效的。同时有的小伙伴可能会想我们可以在项目的web.xml中设置编码过滤器。抱歉这种方式对于get请求也是无效的。
对于这种情况我们可以采用new String(request.getParameter(“name”).getBytes(“iso-8859-1”),”UTF-8”) 来进行二次编码解码过程,这种方式就能解决get请求中文乱码问题,当然我们也可以在tomcat的配置文件中设置统一编码格式。 - <Connector port="8080" protocol="HTTP/1.1" maxThreads="150" connectionTimeout="20000" redirectPort="8443" URIEncoding="utf-8"/>
-
。。。。。。好像有点扯远了,回归主题,接下来我们来看看encodeURI和encodeURIComponent
encodeURI(),用来encode整个URL,不会对下列字符进行编码:+ : / ; ?&。它只会对汉语等特殊字符进行编码
encodeURIComponent (),用来enode URL中想要传输的字符串,它会对所有url敏感字符进行encode
在对url做encode操作时,一定要根据情况选择不同的方法。
例如url = “testGetRequest/testSimpleGet?name=+’爱琴孩’”
此时可以用encodeURI(url)
当你的参数中包含+ : / ; ?&请使用 encodeURIComponent 方法对这些参数单独进行编码。
例如url = “testGetRequest/testSimpleGet?parm=www.baidu.com/ccc/ddd?name=abcd”
所以我上面一开始遇到的问题只需要在前端编码一下就可以解决了 -

当然你也可以换低版本的tomcat,这里是不提倡的!
总结:我的个人解决办法
- 前端jsp页面:这里kfname和kfname传的参数是汉字

前端编码两次:
-
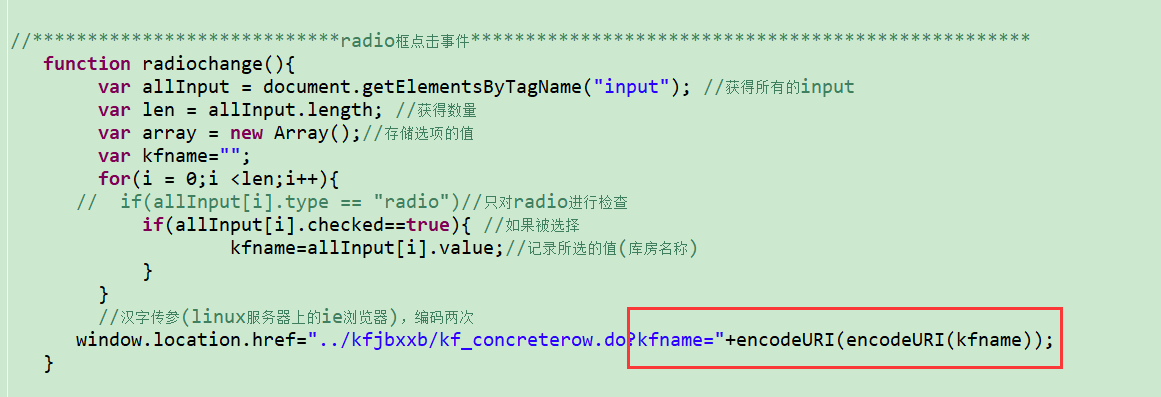
- 后端解码一次(或者两次,我这里解码一次两次都可以);

-
需要注意的一点,上面这种异常只是在IE上会出现,火狐,360,谷歌上是没有的。
多注意点小细节。。。远离猝不及防的惊喜。
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- Invalid [xxx] in servlet mapping 、 <url-pattern& 2020-06-07
- 引入mybatis-plus报 Invalid bound statement错误怎么办,动 2020-05-28
- Codewars Solution:Get the Middle Character 2020-05-21
- 这一份MySQL书单,可以帮你搞定90%以上的面试题! 2020-05-13
- 第六章第二十题(计算一个字符串中字母的个数)(Count the l 2020-05-09
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
