
知乎视频下载(爬虫)
2018-09-18 06:38:29来源:博客园 阅读 ()

目前主要功能是完成知乎视频的下载.
在抓包和网页分析发现有blob:https://...格式的视频链接, 但是无法访问, 不过知乎好像是m3u8格式的, 具体的我也不太清楚, 但这并不妨碍我们的下载工作.
关键在于 https://lens.zhihu.com/api/videos/1024143280014860288 这个api返回的json数据, 包含了不同分辨率的视频url,但其中url打开后是这样的文本文件
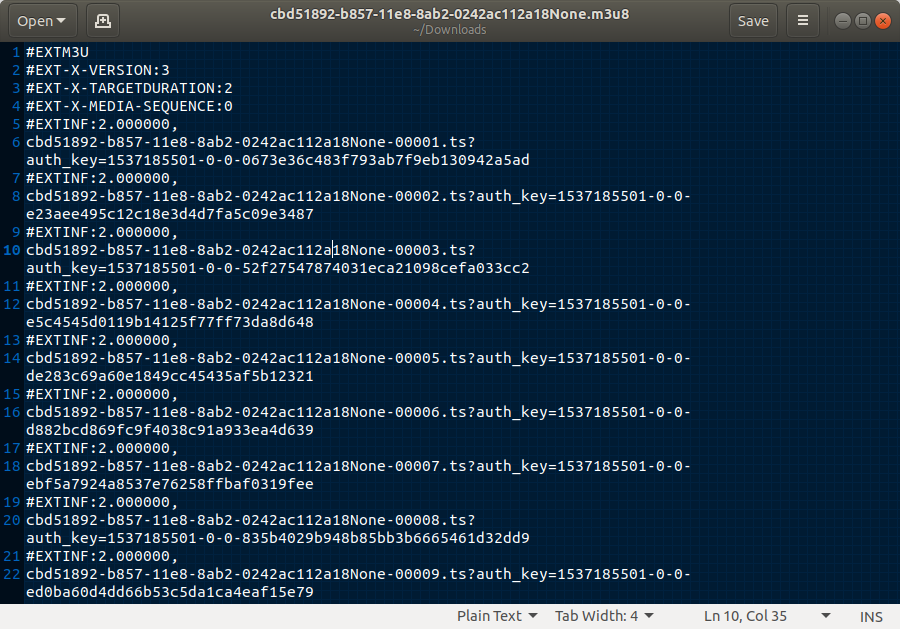
其中ts就是被分割后的相对url, 拼接后就可以下载播放了, 不过这里还要做的就是将所有被分割的视频合并成一个完整的视频文件,具体的可参考下面代码.
----------------------分割线----->
有相关基础的同学都会知道一个知乎视频是被分割成了许多片段.这样的话的确带来了诸多好处,但同时给它的下载带来了麻烦(手动滑稽). 这里的话项目给出了完整的下载流程,具体我也不多讲了.
项目内视频的初步链接可通过如图方式获取:
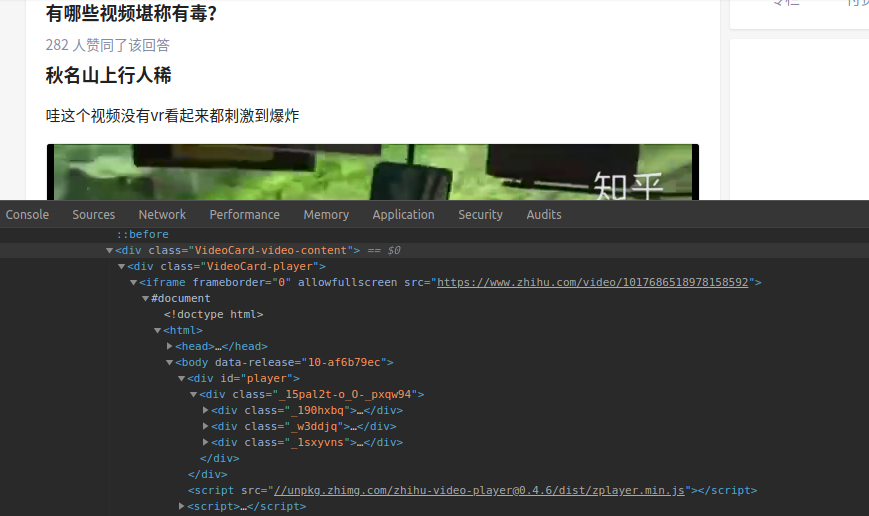
F12 元素选择器选中视频框后会找到<iframe>标签,其中的src就是对应的视频初步链接.
下面贴上代码:
HttpUtil.java
1 import org.json.JSONObject; 2 3 import java.io.*; 4 import java.net.URL; 5 import java.net.URLConnection; 6 import java.util.ArrayList; 7 import java.util.List; 8 import java.util.regex.Matcher; 9 import java.util.regex.Pattern; 10 11 /** 12 * 该类完成视频下载的一些基本操作 13 * @author As_ 14 * @date 2018-09-17 20:29:12 15 * @github https://github.com/apknet 16 */ 17 public class HttpUtil { 18 19 /** 20 * 由api提取出最高清晰度的url 21 * @param url 22 * @return play_url 23 */ 24 public static String getPlayUrl(String url) throws IOException { 25 26 String json = getContent(url); 27 28 JSONObject jsonObject = new JSONObject(json).getJSONObject("playlist"); 29 30 if(jsonObject.has("hd")){ 31 return jsonObject.getJSONObject("hd").getString("play_url"); 32 }else if(jsonObject.has("sd")){ 33 return jsonObject.getJSONObject("sd").getString("play_url"); 34 }else if(jsonObject.has("ld")){ 35 return jsonObject.getJSONObject("ld").getString("play_url"); 36 } 37 return null; 38 } 39 40 /** 41 * 解析出播放清单文件内分散的多个js格式视频url 42 * @param url 43 * @return 44 */ 45 public static List<String> getSrcList(String url) throws IOException { 46 List<String> list = new ArrayList<>(); 47 String content = getContent(url); 48 // 提取出相对路径 49 String relUrl = url.replaceAll("/\\w+-\\w+-\\w+-\\w+-\\w+\\.m3u8.*", ""); 50 51 // 正则提取出的为相对路径, 需与前面的relUrl完成拼接 52 Matcher matcher = Pattern.compile("EXTINF:\\d+\\.\\d+,(.+?)#").matcher(content); 53 54 while (matcher.find()){ 55 System.out.println(matcher.group(1)); 56 list.add(relUrl + "/" + matcher.group(1)); 57 } 58 59 return list; 60 } 61 62 /** 63 * 读取输入流并写到输出流中,该函数用于合并分散的视频文件 64 * @param in 65 * @param out 66 * @throws IOException 67 */ 68 public static void combineStream(InputStream in, OutputStream out) throws IOException { 69 byte[] bytes = new byte[1024]; 70 int n; 71 while ((n = in.read(bytes)) != -1){ 72 out.write(bytes, 0, n); 73 } 74 in.close(); 75 } 76 77 public static InputStream getInputStream(String url) throws IOException { 78 URLConnection connection = new URL(url).openConnection(); 79 connection.setRequestProperty("User-Agent", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"); 80 return connection.getInputStream(); 81 } 82 83 private static String getContent(String url) throws IOException { 84 URLConnection connection = new URL(url).openConnection(); 85 connection.setRequestProperty("User-Agent", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"); 86 87 InputStream inputStream = connection.getInputStream(); 88 BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream)); 89 90 StringBuilder stringBuilder = new StringBuilder(); 91 String line; 92 while((line = reader.readLine()) != null){ 93 stringBuilder.append(line); 94 } 95 reader.close(); 96 inputStream.close(); 97 return stringBuilder.toString(); 98 } 99 }
Main.java
import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.net.URL; import java.net.URLConnection; import java.util.List; public class Main { public static void main(String[] args) { // 将下面的替换成对应的知乎视频url即可 String url_1 = "https://lens.zhihu.com/api/videos/1024143280014860288"; try { FileOutputStream outputStream = new FileOutputStream(new File("/home/as_/IdeaProjects/VideoHelper/video_1.mp4")); List<String> urls = HttpUtil.getSrcList(HttpUtil.getPlayUrl(url_1)); for(String url: urls){ HttpUtil.combineStream(HttpUtil.getInputStream(url), outputStream); } } catch (IOException e) { e.printStackTrace(); } } }
最后附上
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

上一篇:Kafka分区与消费者的关系
- 知乎高赞3万的面试题,累计5000页,已被转2.6w次,肝的太累 2020-05-13
- 知乎Java实习面试(offer到手含面试经验及答案) 2020-05-06
- JAVA 爬虫框架webmagic 初步使用Demo 2020-01-19
- Java爬虫一键爬取结果并保存为Excel 2020-01-12
- 签名图片一键批量生成 使用Java的Webmagic爬虫实现 2020-01-11
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
