
Hadoop提交作业流程
2018-09-29 04:02:25来源:博客园 阅读 ()

一 、需要知道的内容
1.ResourceManager ------>yarn的老大
2.NodeManager ------>yarn的小弟
3.ResourceManager调度器 a.默认调度器------>先进先出FIFO
b.公平调度器------>每个任务都有执行的机会
......
4.心跳机制 ------>NodeManager可通过心跳机制将节点健康状况实时汇报给ResourceManager,而ResourceManager则会 根据每个NodeManager的健康状况适当调整分配的任务数目。当NodeManager认为自己的健康状况“欠 佳”时,可让ResourceManager不再分配任务,待健康状况好转时,再分配新任务。
5.NodeManager子进程------>独立于NodeManager,不在NodeManager内部
二 、Hadoop工作流程:
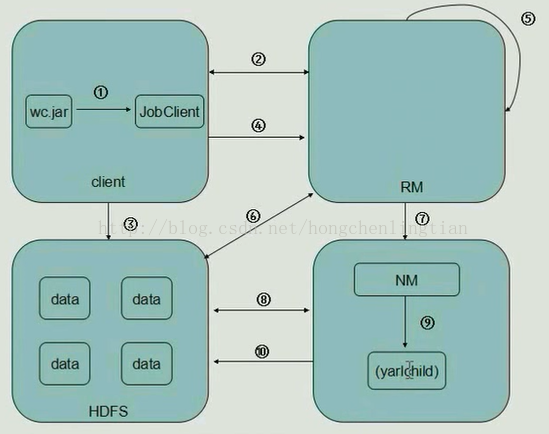
1.Client中,客户端提交一个mr的jar包给JobClient(提交方式:hadoop jar ...)
2.JobClient持有ResourceManager的一个代理对象,它向ResourceManager发送一个RPC请求,告诉ResourceManager作业开始,
然后ResourceManager返回一个JobID和一个存放jar包的路径给Client
3.Client将得到的jar包的路径作为前缀,JobID作为后缀(path = hdfs上的地址 + jobId) 拼接成一个新的hdfs的路径,然后Client通过FileSystem向hdfs中存放jar包,默认存放10份
(NameNode和DateNode等操作)
4.开始提交任务,Client将作业的描述信息(JobID和拼接后的存放jar包的路径等)RPC返回给ResourceManager
5.ResourceManager进行初始化任务,然后放到一个调度器中
6.ResourceManager读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask,根据数据量确定起多少个mapper,多少个reducer
7.NodeManager 通过心跳机制向ResourceManager领取任务(任务的描述信息)
8.领取到任务的NodeManager去Hdfs上下载jar包,配置文件等
9.NodeManager启动相应的子进程yarnchild,运行mapreduce,运行maptask或者reducetask
10.map从hdfs中读取数据,然后传给reduce,reduce将输出的数据给回hdfs
--------------------- 本文来自 小虹尘 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/hongchenlingtian/article/details/53524705?utm_source=copy
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- Java生鲜电商平台-生鲜电商接口幂等性原理与防重复提交方案( 2020-06-05
- SpringBoot 2.x 版本以put方式提交表单不生效的问题详解 2020-06-01
- 一口气说出8种幂等性解决重复提交的方案,面试官懵了! 2020-05-30
- 架构调优之如何压缩整合hadoop,本文详解 2020-05-23
- 架构设计 | 接口幂等性原则,防重复提交Token管理 2020-05-22
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
