
Spring Boot整合Spring Batch
2019-05-10 06:06:50来源:博客园 阅读 ()

引言
Spring Batch是处理大量数据操作的一个框架,主要用来读取大量数据,然后进行一定的处理后输出指定的形式。比如我们可以将csv文件中的数据(数据量几百万甚至几千万都是没问题的)批处理插入保存到数据库中,就可以使用该框架,但是不管是数据资料还是网上资料,我看到很少有这样的详细讲解。所以本片博文的主要目的边讲解的同时边实战(其中的代码都是经过实践的)。同样地先从Spring Boot对Batch框架的支持说起,最后一步一步进行代码实践!
一、Spring Boot对Batch框架的支持
1、Spring Batch框架的组成部分
1)JobRepository:用来注册Job容器,设置数据库相关属性。
2)JobLauncher:用来启动Job的接口
3)Job:我们要实际执行的任务,包含一个或多个
4)Step:即步骤,包括:ItemReader->ItemProcessor->ItemWriter
5)ItemReader:用来读取数据,做实体类与数据字段之间的映射。比如读取csv文件中的人员数据,之后对应实体person的字段做mapper
6)ItemProcessor:用来处理数据的接口,同时可以做数据校验(设置校验器,使用JSR-303(hibernate-validator)注解),比如将中文性别男/女,转为M/F。同时校验年龄字段是否符合要求等
7)ItemWriter:用来输出数据的接口,设置数据库源。编写预处理SQL插入语句
以上七个组成部分,只需要在配置类中逐一注册即可,同时配置类需要开启@EnableBatchProcessing注解
@Configuration @EnableBatchProcessing // 开启批处理的支持 @Import(DruidDBConfig.class) // 注入datasource public class CsvBatchConfig { }
2、批处理流程图
如下流程图即可以解释在配置类中为什么需要这么定义,具体请看实战部分的代码。

二、实战
1、添加依赖
1)spring batch依赖
<!-- spring batch --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency>
2)校验器依赖
<!-- hibernate validator --> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-validator</artifactId> <version>6.0.7.Final</version> </dependency>
3)mysql+druid依赖
<!-- mysql connector--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.35</version> </dependency> <!-- alibaba dataSource --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.12</version> </dependency>
4)test测试依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency>
2、application.yml配置
当job发布开始执行任务时,spring batch会自动生成相关的batch开头的表。这些表一开始是不存在的!需要在application配置文件中做相关的设置。
# batch
batch:
job:
# 默认自动执行定义的Job(true),改为false,需要jobLaucher.run执行
enabled: false
# spring batch在数据库里面创建默认的数据表,如果不是always则会提示相关表不存在
initialize-schema: always
# 设置batch表的前缀
# table-prefix: csv-batch
3、数据源配置
datasource: username: root password: 1234 url: jdbc:mysql://127.0.0.1:3306/db_base?useSSL=false&serverTimezone=UTC&characterEncoding=utf8 driver-class-name: com.mysql.jdbc.Driver
注册DBConfig配置类:之后通过import导入batch配置类中


/** * @author jian * @dete 2019/4/20 * @description 自定义DataSource * */ @Configuration public class DruidDBConfig { private Logger logger = LoggerFactory.getLogger(DruidDBConfig.class); @Value("${spring.datasource.url}") private String dbUrl; @Value("${spring.datasource.username}") private String username; @Value("${spring.datasource.password}") private String password; @Value("${spring.datasource.driver-class-name}") private String driverClassName; /* @Value("${spring.datasource.initialSize}") private int initialSize; @Value("${spring.datasource.minIdle}") private int minIdle; @Value("${spring.datasource.maxActive}") private int maxActive; @Value("${spring.datasource.maxWait}") private int maxWait; @Value("${spring.datasource.timeBetweenEvictionRunsMillis}") private int timeBetweenEvictionRunsMillis; @Value("${spring.datasource.minEvictableIdleTimeMillis}") private int minEvictableIdleTimeMillis; @Value("${spring.datasource.validationQuery}") private String validationQuery; @Value("${spring.datasource.testWhileIdle}") private boolean testWhileIdle; @Value("${spring.datasource.testOnBorrow}") private boolean testOnBorrow; @Value("${spring.datasource.testOnReturn}") private boolean testOnReturn; @Value("${spring.datasource.poolPreparedStatements}") private boolean poolPreparedStatements; @Value("${spring.datasource.maxPoolPreparedStatementPerConnectionSize}") private int maxPoolPreparedStatementPerConnectionSize; @Value("${spring.datasource.filters}") private String filters; @Value("{spring.datasource.connectionProperties}") private String connectionProperties;*/ @Bean @Primary // 被注入的优先级最高 public DataSource dataSource() { DruidDataSource dataSource = new DruidDataSource(); logger.info("-------->dataSource[url="+dbUrl+" ,username="+username+"]"); dataSource.setUrl(dbUrl); dataSource.setUsername(username); dataSource.setPassword(password); dataSource.setDriverClassName(driverClassName); /* //configuration datasource.setInitialSize(initialSize); datasource.setMinIdle(minIdle); datasource.setMaxActive(maxActive); datasource.setMaxWait(maxWait); datasource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis); datasource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis); datasource.setValidationQuery(validationQuery); datasource.setTestWhileIdle(testWhileIdle); datasource.setTestOnBorrow(testOnBorrow); datasource.setTestOnReturn(testOnReturn); datasource.setPoolPreparedStatements(poolPreparedStatements); datasource.setMaxPoolPreparedStatementPerConnectionSize(maxPoolPreparedStatementPerConnectionSize); try { datasource.setFilters(filters); } catch (SQLException e) { logger.error("druid configuration initialization filter", e); } datasource.setConnectionProperties(connectionProperties);*/ return dataSource; } @Bean public ServletRegistrationBean druidServletRegistrationBean() { ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(); servletRegistrationBean.setServlet(new StatViewServlet()); servletRegistrationBean.addUrlMappings("/druid/*"); return servletRegistrationBean; } /** * 注册DruidFilter拦截 * * @return */ @Bean public FilterRegistrationBean duridFilterRegistrationBean() { FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(); filterRegistrationBean.setFilter(new WebStatFilter()); Map<String, String> initParams = new HashMap<String, String>(); //设置忽略请求 initParams.put("exclusions", "*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*"); filterRegistrationBean.setInitParameters(initParams); filterRegistrationBean.addUrlPatterns("/*"); return filterRegistrationBean; } }
4、编写batch配置类
在配置类中,注册Spring Batch的各个组成部分即可,其中部分说明已在代码中注释.
/** * * @author jian * @date 2019/4/28 * @description spring batch cvs文件批处理配置需要注入Spring Batch以下组成部分 * spring batch组成: * 1)JobRepository 注册job的容器 * 2)JonLauncher 用来启动job的接口 * 3)Job 实际执行的任务,包含一个或多个Step * 4)Step Step步骤包括ItemReader、ItemProcessor和ItemWrite * 5)ItemReader 读取数据的接口 * 6)ItemProcessor 处理数据的接口 * 7)ItemWrite 输出数据的接口 * * */ @Configuration @EnableBatchProcessing // 开启批处理的支持 @Import(DruidDBConfig.class) // 注入datasource public class CsvBatchConfig { private Logger logger = LoggerFactory.getLogger(CsvBatchConfig.class); /** * ItemReader定义:读取文件数据+entirty映射 * @return */ @Bean public ItemReader<Person> reader(){ // 使用FlatFileItemReader去读cvs文件,一行即一条数据 FlatFileItemReader<Person> reader = new FlatFileItemReader<>(); // 设置文件处在路径 reader.setResource(new ClassPathResource("person.csv")); // entity与csv数据做映射 reader.setLineMapper(new DefaultLineMapper<Person>() { { setLineTokenizer(new DelimitedLineTokenizer() { { setNames(new String[]{"id", "name", "age", "gender"}); } }); setFieldSetMapper(new BeanWrapperFieldSetMapper<Person>() { { setTargetType(Person.class); } }); } }); return reader; } /** * 注册ItemProcessor: 处理数据+校验数据 * @return */ @Bean public ItemProcessor<Person, Person> processor(){ CvsItemProcessor cvsItemProcessor = new CvsItemProcessor(); // 设置校验器 cvsItemProcessor.setValidator(csvBeanValidator()); return cvsItemProcessor; } /** * 注册校验器 * @return */ @Bean public CsvBeanValidator csvBeanValidator(){ return new CsvBeanValidator<Person>(); } /** * ItemWriter定义:指定datasource,设置批量插入sql语句,写入数据库 * @param dataSource * @return */ @Bean public ItemWriter<Person> writer(DataSource dataSource){ // 使用jdbcBcatchItemWrite写数据到数据库中 JdbcBatchItemWriter<Person> writer = new JdbcBatchItemWriter<>(); // 设置有参数的sql语句 writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<Person>()); String sql = "insert into person values(:id,:name,:age,:gender)"; writer.setSql(sql); writer.setDataSource(dataSource); return writer; } /** * JobRepository定义:设置数据库,注册Job容器 * @param dataSource * @param transactionManager * @return * @throws Exception */ @Bean public JobRepository cvsJobRepository(DataSource dataSource, PlatformTransactionManager transactionManager) throws Exception{ JobRepositoryFactoryBean jobRepositoryFactoryBean = new JobRepositoryFactoryBean(); jobRepositoryFactoryBean.setDatabaseType("mysql"); jobRepositoryFactoryBean.setTransactionManager(transactionManager); jobRepositoryFactoryBean.setDataSource(dataSource); return jobRepositoryFactoryBean.getObject(); } /** * jobLauncher定义: * @param dataSource * @param transactionManager * @return * @throws Exception */ @Bean public SimpleJobLauncher csvJobLauncher(DataSource dataSource, PlatformTransactionManager transactionManager) throws Exception{ SimpleJobLauncher jobLauncher = new SimpleJobLauncher(); // 设置jobRepository jobLauncher.setJobRepository(cvsJobRepository(dataSource, transactionManager)); return jobLauncher; } /** * 定义job * @param jobs * @param step * @return */ @Bean public Job importJob(JobBuilderFactory jobs, Step step){ return jobs.get("importCsvJob") .incrementer(new RunIdIncrementer()) .flow(step) .end() .listener(csvJobListener()) .build(); } /** * 注册job监听器 * @return */ @Bean public CsvJobListener csvJobListener(){ return new CsvJobListener(); } /** * step定义:步骤包括ItemReader->ItemProcessor->ItemWriter 即读取数据->处理校验数据->写入数据 * @param stepBuilderFactory * @param reader * @param writer * @param processor * @return */ @Bean public Step step(StepBuilderFactory stepBuilderFactory, ItemReader<Person> reader, ItemWriter<Person> writer, ItemProcessor<Person, Person> processor){ return stepBuilderFactory .get("step") .<Person, Person>chunk(65000) // Chunk的机制(即每次读取一条数据,再处理一条数据,累积到一定数量后再一次性交给writer进行写入操作) .reader(reader) .processor(processor) .writer(writer) .build(); } }
5、定义处理器
只需要实现ItemProcessor接口,重写process方法,输入的参数是从ItemReader读取到的数据,返回的数据给ItemWriter
/** * @author jian * @date 2019/4/28 * @description * CSV文件数据处理及校验 * 只需要实现ItemProcessor接口,重写process方法,输入的参数是从ItemReader读取到的数据,返回的数据给ItemWriter */ public class CvsItemProcessor extends ValidatingItemProcessor<Person> { private Logger logger = LoggerFactory.getLogger(CvsItemProcessor.class); @Override public Person process(Person item) throws ValidationException { // 执行super.process()才能调用自定义的校验器 logger.info("processor start validating..."); super.process(item); // 数据处理,比如将中文性别设置为M/F if ("男".equals(item.getGender())) { item.setGender("M"); } else { item.setGender("F"); } logger.info("processor end validating..."); return item; } }
6、定义校验器
定义校验器:使用JSR-303(hibernate-validator)注解,来校验ItemReader读取到的数据是否满足要求。如不满足则不会进行接下来的批处理任务。
/** * * @author jian * @date 2019/4/28 * @param <T> * @description 定义校验器:使用JSR-303(hibernate-validator)注解,来校验ItemReader读取到的数据是否满足要求。 */ public class CsvBeanValidator<T> implements Validator<T>, InitializingBean { private javax.validation.Validator validator; /** * 进行JSR-303的Validator的初始化 * @throws Exception */ @Override public void afterPropertiesSet() throws Exception { ValidatorFactory validatorFactory = Validation.buildDefaultValidatorFactory(); validator = validatorFactory.usingContext().getValidator(); } /** * 使用validator方法检验数据 * @param value * @throws ValidationException */ @Override public void validate(T value) throws ValidationException { Set<ConstraintViolation<T>> constraintViolations = validator.validate(value); if (constraintViolations.size() > 0) { StringBuilder message = new StringBuilder(); for (ConstraintViolation<T> constraintViolation: constraintViolations) { message.append(constraintViolation.getMessage() + "\n"); } throw new ValidationException(message.toString()); } } }
7、定义监听器:
监听Job执行情况,则定义一个类实现JobExecutorListener,并定义Job的Bean上绑定该监听器
/** * @author jian * @date 2019/4/28 * @description * 监听Job执行情况,则定义一个类实现JobExecutorListener,并定义Job的Bean上绑定该监听器 */ public class CsvJobListener implements JobExecutionListener { private Logger logger = LoggerFactory.getLogger(CsvJobListener.class); private long startTime; private long endTime; @Override public void beforeJob(JobExecution jobExecution) { startTime = System.currentTimeMillis(); logger.info("job process start..."); } @Override public void afterJob(JobExecution jobExecution) { endTime = System.currentTimeMillis(); logger.info("job process end..."); logger.info("elapsed time: " + (endTime - startTime) + "ms"); } }
三、测试
1、person.csv文件
csv文件时以逗号为分隔的数据表示字段,回车表示一行(条)数据记录
1,Zhangsan,21,男 2,Lisi,22,女 3,Wangwu,23,男 4,Zhaoliu,24,男 5,Zhouqi,25,女
放在resources下,在ItemReader中读取的该路径即可

2、person实体
person.csv中的字段与之对应,并在该实体中可以添加校验注解,如@Size表示该字段的长度范围,如果超过规定。则会被校验检测到,批处理将不会进行!
public class Person implements Serializable { private final long serialVersionUID = 1L; private String id; @Size(min = 2, max = 8) private String name; private int age; private String gender; public String getId() { return id; } public void setId(String id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getGender() { return gender; } public void setGender(String gender) { this.gender = gender; } @Override public String toString() { return "Person{" + "id='" + id + '\'' + ", name='" + name + '\'' + ", age=" + age + ", gender='" + gender + '\'' + '}'; } }
3、数据表
CREATE TABLE `person` ( `id` int(11) NOT NULL, `name` varchar(10) DEFAULT NULL, `age` int(11) DEFAULT NULL, `gender` varchar(2) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1
一开始表是没有数据的

4、测试类
需要注入发布器,与job任务。同时可以使用后置参数灵活处理,最后调用JobLauncher.run方法执行批处理任务
@RunWith(SpringRunner.class) @SpringBootTest public class BatchTest { @Autowired SimpleJobLauncher jobLauncher; @Autowired Job importJob; @Test public void test() throws Exception{ // 后置参数:使用JobParameters中绑定参数 JobParameters jobParameters = new JobParametersBuilder().addLong("time", System.currentTimeMillis()) .toJobParameters(); jobLauncher.run(importJob, jobParameters); } }
5、测试结果
....
2019-05-09 15:23:39.576 INFO 18296 --- [ main] com.lijian.test.BatchTest : Started BatchTest in 6.214 seconds (JVM running for 7.185) 2019-05-09 15:23:39.939 INFO 18296 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=importCsvJob]] launched with the following parameters: [{time=1557386619763}] 2019-05-09 15:23:39.982 INFO 18296 --- [ main] com.lijian.config.batch.CsvJobListener : job process start... 2019-05-09 15:23:40.048 INFO 18296 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [step] 2019-05-09 15:23:40.214 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:23:40.282 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor end validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor end validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor end validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor end validating... 2019-05-09 15:23:40.283 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:23:40.284 INFO 18296 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor end validating... 2019-05-09 15:23:40.525 INFO 18296 --- [ main] com.lijian.config.batch.CsvJobListener : job process end... 2019-05-09 15:23:40.526 INFO 18296 --- [ main] com.lijian.config.batch.CsvJobListener : elapsed time: 543ms 2019-05-09 15:23:40.548 INFO 18296 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=importCsvJob]] completed with the following parameters: [{time=1557386619763}] and the following status: [COMPLETED] 2019-05-09 15:23:40.564 INFO 18296 --- [ Thread-5] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} closed
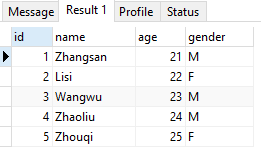
查看表中数据: select * from person;
若继续插入数据,并且测试校验器是否生效,则将person.csv更改为如下内容:
6,springbatch,24,男
7,springboot,23,女
由于实体类中JSR校验注解对name长度范围进行了检验,即添加了 @Size(min=2, max=8) 的注解。故会报错显示校验不通过,批处理将不会进行。
... Started BatchTest in 5.494 seconds (JVM running for 6.41) 2019-05-09 15:30:02.147 INFO 20368 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=importCsvJob]] launched with the following parameters: [{time=1557387001499}] 2019-05-09 15:30:02.247 INFO 20368 --- [ main] com.lijian.config.batch.CsvJobListener : job process start... 2019-05-09 15:30:02.503 INFO 20368 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [step] 2019-05-09 15:30:02.683 INFO 20368 --- [ main] c.lijian.config.batch.CvsItemProcessor : processor start validating... 2019-05-09 15:30:02.761 ERROR 20368 --- [ main] o.s.batch.core.step.AbstractStep : Encountered an error executing step step in job importCsvJob org.springframework.batch.item.validator.ValidationException: size must be between 2 and 8 ...
原文链接:https://www.cnblogs.com/jian0110/p/10838744.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

下一篇:Java基础学习-一切皆为对象
- Spring系列.ApplicationContext接口 2020-06-11
- springboot2配置JavaMelody与springMVC配置JavaMelody 2020-06-11
- 给你一份超详细 Spring Boot 知识清单 2020-06-11
- SpringBoot 2.3 整合最新版 ShardingJdbc + Druid + MyBatis 2020-06-11
- 掌握SpringBoot-2.3的容器探针:实战篇 2020-06-11
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
