
ssm(Spring、Springmvc、Mybatis)实战之淘淘商…
2019-05-16 23:58:46来源:博客园 阅读 ()

文章大纲
一、课程介绍
二、SolrCloud介绍与搭建
三、工程部署
四、参考资料下载
五、参考文章
一、课程介绍
一共14天课程
(1)第一天:电商行业的背景。淘淘商城的介绍。搭建项目工程。Svn的使用。
(2)第二天:框架的整合。后台管理商品列表的实现。分页插件。
(3)第三天:后台管理。商品添加。商品类目的选择、图片上传、富文本编辑器的使用。
(4)第四天:商品规格的实现。
(5)第五天:商城前台系统的搭建。首页商品分类的展示。Jsonp。
(6)第六天:cms系统的实现。前台大广告位的展示。
(7)第七天:cms系统添加缓存。Redis。缓存同步。
(8)第八天:搜索功能的实现。使用solr实现搜索。
(9)第九天:商品详情页面的展示。
(10)第十天:单点登录系统。Session共享。
(11)第十一天:购物车订单系统的实现。
(12)第十二天:nginx。反向代理工具。
(13)第十三天:redis集群的搭建、solr集群的搭建。系统的部署。
(14)项目总结。
二、SolrCloud介绍与搭建
1. 什么是SolrCloud
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
(1)集中式的配置信息
(2)自动容错
(3)近实时搜索
(4)查询时自动负载均衡
2. 什么是Zookeeper
顾名思义zookeeper就是动物园管理员,他是用来管hadoop(大象)、Hive(蜜蜂)、pig(小猪)的管理员, Apache Hbase和 Apache Solr 的分布式集群都用到了zookeeper;Zookeeper:是一个分布式的、开源的程序协调服务,是hadoop项目下的一个子项目。
3. Zookeeper可以干哪些事情
(1)配置管理
在我们的应用中除了代码外,还有一些就是各种配置。比如数据库连接等。一般我们都是使用配置文件的方式,在代码中引入这些配置文件。但是当我们只有一种配置,只有一台服务器,并且不经常修改的时候,使用配置文件是一个很好的做法,但是如果我们配置非常多,有很多服务器都需要这个配置,而且还可能是动态的话使用配置文件就不是个好主意了。这个时候往往需要寻找一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣的都可以获得变更。比如我们可以把配置放在数据库里,然后所有需要配置的服务都去这个数据库读取配置。但是,因为很多服务的正常运行都非常依赖这个配置,所以需要这个集中提供配置服务的服务具备很高的可靠性。一般我们可以用一个集群来提供这个配置服务,但是用集群提升可靠性,那如何保证配置在集群中的一致性呢? 这个时候就需要使用一种实现了一致性协议的服务了。Zookeeper就是这种服务,它使用Zab这种一致性协议来提供一致性。现在有很多开源项目使用Zookeeper来维护配置,比如在HBase中,客户端就是连接一个Zookeeper,获得必要的HBase集群的配置信息,然后才可以进一步操作。还有在开源的消息队列Kafka中,也使用Zookeeper来维护broker的信息。在Alibaba开源的SOA框架Dubbo中也广泛的使用Zookeeper管理一些配置来实现服务治理。
(2)名字服务
名字服务这个就很好理解了。比如为了通过网络访问一个系统,我们得知道对方的IP地址,但是IP地址对人非常不友好,这个时候我们就需要使用域名来访问。但是计算机是不能是别域名的。怎么办呢?如果我们每台机器里都备有一份域名到IP地址的映射,这个倒是能解决一部分问题,但是如果域名对应的IP发生变化了又该怎么办呢?于是我们有了DNS这个东西。我们只需要访问一个大家熟知的(known)的点,它就会告诉你这个域名对应的IP是什么。在我们的应用中也会存在很多这类问题,特别是在我们的服务特别多的时候,如果我们在本地保存服务的地址的时候将非常不方便,但是如果我们只需要访问一个大家都熟知的访问点,这里提供统一的入口,那么维护起来将方便得多了。
(3)分布式锁
其实在第一篇文章中已经介绍了Zookeeper是一个分布式协调服务。这样我们就可以利用Zookeeper来协调多个分布式进程之间的活动。比如在一个分布式环境中,为了提高可靠性,我们的集群的每台服务器上都部署着同样的服务。但是,一件事情如果集群中的每个服务器都进行的话,那相互之间就要协调,编程起来将非常复杂。而如果我们只让一个服务进行操作,那又存在单点。通常还有一种做法就是使用分布式锁,在某个时刻只让一个服务去干活,当这台服务出问题的时候锁释放,立即fail over到另外的服务。这在很多分布式系统中都是这么做,这种设计有一个更好听的名字叫Leader Election(leader选举)。比如HBase的Master就是采用这种机制。但要注意的是分布式锁跟同一个进程的锁还是有区别的,所以使用的时候要比同一个进程里的锁更谨慎的使用。
(4)集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些节点会进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中其他机器需要感知到这种变化,然后根据这种变化做出对应的决策。比如我们是一个分布式存储系统,有一个中央控制节点负责存储的分配,当有新的存储进来的时候我们要根据现在集群目前的状态来分配存储节点。这个时候我们就需要动态感知到集群目前的状态。还有,比如一个分布式的SOA架构中,服务是一个集群提供的,当消费者访问某个服务时,就需要采用某种机制发现现在有哪些节点可以提供该服务(这也称之为服务发现,比如Alibaba开源的SOA框架Dubbo就采用了Zookeeper作为服务发现的底层机制)。还有开源的Kafka队列就采用了Zookeeper作为Cosnumer的上下线管理。
4. SolrCloud结构
SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud需要由多台服务器组成,由zookeeper来进行协调管理。
下图是一个SolrCloud应用的例子:
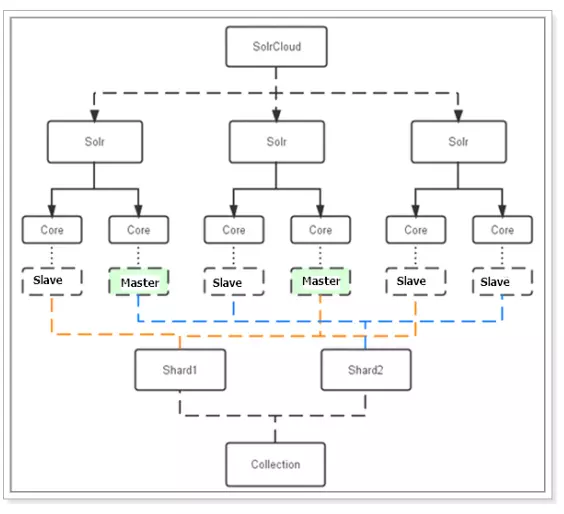
对上图进行图解,如下:

4.1 物理结构
三个Solr实例( 每个实例包括两个Core),组成一个SolrCloud。
4.2 逻辑结构
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
collection:
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。比如:针对商品信息搜索可以创建一个collection。collection=shard1+shard2+....+shardX
Core:
每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
Master或Slave:
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
Shard:
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。
5. SolrCloud搭建
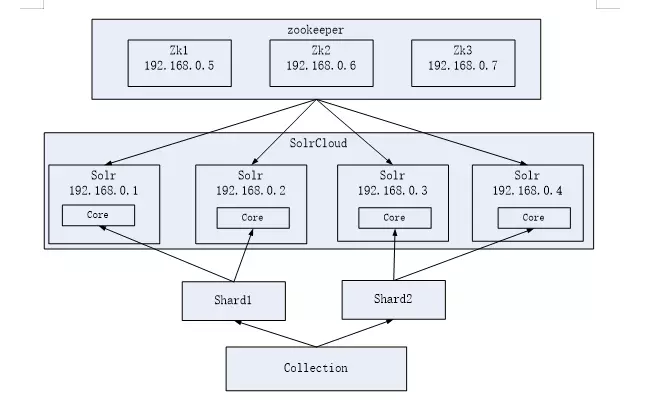
5.1 架构安排
本教程的这套安装是单机版的安装,所以采用伪集群的方式进行安装,如果是真正的生产环境,将伪集群的ip改下就可以了,步骤是一样的。
SolrCloud结构图如下:
5.2 环境准备
(1)CentOS-6.4-i386-bin-DVD1.iso
(2)jdk-7u72-linux-i586.tar.gz
(3)apache-tomcat-7.0.47.tar.gz
(4)zookeeper-3.4.6.tar.gz
(5)solr-4.10.3.tgz
5.3 具体环境安装
具体环节安装在请参考资料下载中进行学习
6. solrJ访问solrCloud
public class SolrCloudTest {
// zookeeper地址
private static String zkHostString = "192.168.25.154:2181,192.168.25.154:2182,192.168.25.154:2183";
// collection默认名称,比如我的solr服务器上的collection是collection2_shard1_replica1,就是去掉“_shard1_replica1”的名称
private static String defaultCollection = "collection1";
// cloudSolrServer实际
private CloudSolrServer cloudSolrServer;
// 测试方法之前构造 CloudSolrServer
@Before
public void init() {
cloudSolrServer = new CloudSolrServer(zkHostString);
cloudSolrServer.setDefaultCollection(defaultCollection);
cloudSolrServer.connect();
}
// 向solrCloud上创建索引
@Test
public void testCreateIndexToSolrCloud() throws SolrServerException,
IOException {
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "100001");
document.addField("title", "李四");
cloudSolrServer.add(document);
cloudSolrServer.commit();
}
// 搜索索引
@Test
public void testSearchIndexFromSolrCloud() throws Exception {
SolrQuery query = new SolrQuery();
query.setQuery("*:*");
try {
QueryResponse response = cloudSolrServer.query(query);
SolrDocumentList docs = response.getResults();
System.out.println("文档个数:" + docs.getNumFound());
System.out.println("查询时间:" + response.getQTime());
for (SolrDocument doc : docs) {
ArrayList title = (ArrayList) doc.getFieldValue("title");
String id = (String) doc.getFieldValue("id");
System.out.println("id: " + id);
System.out.println("title: " + title);
System.out.println();
}
} catch (SolrServerException e) {
e.printStackTrace();
} catch (Exception e) {
System.out.println("Unknowned Exception!!!!");
e.printStackTrace();
}
}
// 删除索引
@Test
public void testDeleteIndexFromSolrCloud() throws SolrServerException, IOException {
// 根据id删除
UpdateResponse response = cloudSolrServer.deleteById("zhangsan");
// 根据多个id删除
// cloudSolrServer.deleteById(ids);
// 自动查询条件删除
// cloudSolrServer.deleteByQuery("product_keywords:教程");
// 提交
cloudSolrServer.commit();
}
}
三、工程部署
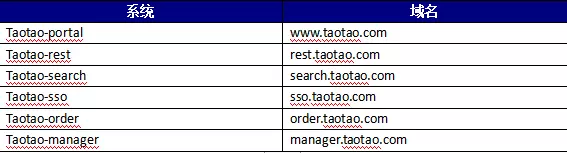
1. 域名规划
2. 环境准备
CentOS6.4
Jdk1.8以上
Tomcat8
3. 部署步骤
使用maven实现tomcat的热部署。
第一步:安装tomcat
先在CentOS中安装jdk,然后解压tomcat。
第二步: 在tomcat中配置用户权限
我们需要实现热部署,自然就需要通过maven操作tomcat,所以就需要maven取得操作tomcat的权限,现在这一步就是配置tomcat的可操作权限.
在tomcat的安装目录下,修改conf / tomcat-user.xml文件,在<tomcat-users> 节点下面增加如下配置:
<role rolename="manager-gui" />
<role rolename="manager-script" />
<user username="tomcat" password="tomcat" roles="manager-gui, manager-script"/>
第三步:修改pom文件
在project中添加插件,以及maven中配置的server,
现在maven已经拥有操作tomcat的权限了,但是这两者之间想要通信的话还需要一个桥梁,那就是在maven中配置tomcat插件.
修改项目的pom.xml文件,在<build> 节点下面增加如下配置:
<build>
<plugins>
<!-- 配置Tomcat插件 -->
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<configuration>
<port>8081</port>
<path>/</path>
<url>http://192.168.25.136:8080/manager/text</url>
<username>tomcat</username>
<password>tomcat</password>
</configuration>
</plugin>
</plugins>
</build>
第四步:设置部署命令
一般使用搜是在eclipse中,可以右键点击需要部署的项目,Run as -> Run configurations -> maven build -> 右键 new,这样配置一个新的maven命令具体配置命令方法:
初次部署可以使用 "tomcat7:deploy" 命令
如果已经部署过使用 "tomcat7:redeploy" 命令
四、参考资料下载
链接:https://pan.baidu.com/s/1udhG8gBTZ6wjW9eDR8ZSOQ
提取码:fml7
五、参考文章
http://yun.itheima.com/course?hm
原文链接:https://www.cnblogs.com/WUXIAOCHANG/p/10869764.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

上一篇:Java多线程――异常记录
下一篇:解决Maven依赖下载不全的问题
- Spring系列.ApplicationContext接口 2020-06-11
- springboot2配置JavaMelody与springMVC配置JavaMelody 2020-06-11
- 给你一份超详细 Spring Boot 知识清单 2020-06-11
- SpringBoot 2.3 整合最新版 ShardingJdbc + Druid + MyBatis 2020-06-11
- 掌握SpringBoot-2.3的容器探针:实战篇 2020-06-11
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
