
多线程编程学习七( Fork/Join 框架).
2019-09-08 09:47:33来源:博客园 阅读 ()

多线程编程学习七( Fork/Join 框架).
一、介绍
使用 java8 lambda 表达式大半年了,一直都知道底层使用的是 Fork/Join 框架,今天终于有机会来学学 Fork/Join 框架了。
Fork/Join 框架是 Java 7 提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork/Join 的运行流程示意图:
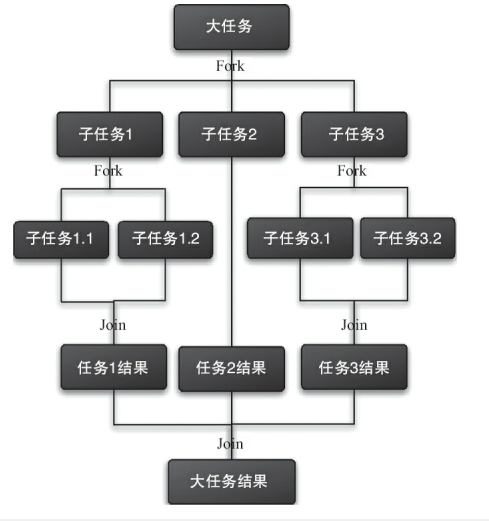
比如,一个 1+2+3+...+100 的工作任务,我们可以把它 Fork 成 10 个子任务,分别计算这 10 个子任务的运行结果。最后再把 10 个子任务的结果 Join 起来,汇总成最后的结果。
为了减少线程间的竞争,通常把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其它线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。线程的这种执行方式,我们称之为“工作窃取”算法。
二、设计
实现 Fork/Join 框架的设计,大抵需要两步:
1. 分割任务
首先我们需要创建一个 ForkJoin 任务,把大任务分割成子任务,如果子任务不够小,则继续往下分,直到分割出的子任务足够小。
在 Java 中我们可以使用 ForkJoinTask 类,它提供在任务中执行 fork() 和 join() 操作的机制,通常情况下,我们只需要继承它的子类:
- RecursiveAction ― 用于没有返回结果的任务
- RecursiveTask ― 用于有返回结果的任务
2. 任务执行并返回结果
分割的子任务分别放在双端队列里,然后启动几个线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
在 Java 中任务的执行需要通过 ForkJoinPool 来执行。
三、示例
来一个阿里面试题:百万级 Integer 数据量的一个 array 求和。
public class ArrayCountTask extends RecursiveTask<Long> {
/**
* 阈值
*/
private static final Integer THRESHOLD = 10000;
private Integer[] array;
private Integer start;
private Integer end;
public ArrayCountTask(Integer[] array, Integer start, Integer end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0;
// 最小子任务计算
if (end - start <= THRESHOLD) {
for (int i = start; i < end; i++) {
sum += array[i];
}
} else {
// 把大于阈值的任务继续往下拆分,有点类似递归的思维。 recursive 就是递归的意思。
int middle = (start + end) >>> 1;
ArrayCountTask leftArrayCountTask = new ArrayCountTask(array, start, middle);
ArrayCountTask rightArrayCountTask = new ArrayCountTask(array, middle, end);
// 执行子任务
//leftArrayCountTask.fork();
//rightArrayCountTask.fork();
// invokeAll 方法使用
invokeAll(leftArrayCountTask, rightArrayCountTask);
//等待子任务执行完,并得到其结果
Long leftJoin = leftArrayCountTask.join();
Long rightJoin = rightArrayCountTask.join();
// 合并子任务的结果
sum = leftJoin + rightJoin;
}
return sum;
}
} public static void main(String[] args) {
// 1. 造一个 int 类型的百万级别数组
Integer[] array = new Integer[150000000];
for (int i = 0; i < array.length; i++) {
array[i] = new Random().nextInt(100);
}
// 2.普通方式计算结果
long start = System.currentTimeMillis();
long sum = 0;
for (int i = 0; i < array.length; i++) {
sum += array[i];
}
long end = System.currentTimeMillis();
System.out.println("普通方式计算结果:" + sum + ",耗时:" + (end - start));
long start2 = System.currentTimeMillis();
// 3.fork/join 框架方式计算结果
ArrayCountTask arrayCountTask = new ArrayCountTask(array, 0, array.length);
ForkJoinPool forkJoinPool = new ForkJoinPool();
sum = forkJoinPool.invoke(arrayCountTask);
long end2 = System.currentTimeMillis();
System.out.println("fork/join 框架方式计算结果:" + sum + ",耗时:" + (end2 - start2));
// 结论:
// 1. 电脑 i5-4300m,双核四线程
// 2. 数组量少的时候,fork/join 框架要进行线程创建/切换的操作,性能不明显。
// 3. 数组量超过 100000000,fork/join 框架的性能才开始体现。
}ForkJoinTask 与一般任务的主要区别在于它需要实现 compute 方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用 fork 方法时,又会进入 compute 方法,看看当前子任务是否需要继续分割成子任务,如果不需要继续分割,则执行当前子任务并返回结果。使用 join 方法会等待子任务执行完并得到其结果。
在执行子任务时调用 fork 方法并不是最佳的选择,最佳的选择是 invokeAll 方法。因为执行 compute() 方法的线程本身也是一个 worker 线程,当对两个子任务调用 fork() 时,这个worker 线程就会把任务分配给另外两个 worker,但是它自己却停下来等待不干活了!这样就白白浪费了 Fork/Join 线程池中的一个 worker 线程,导致了4个子任务至少需要7个线程才能并发执行。
比如甲把 400 分成两个 200 后,fork() 写法相当于甲把一个 200 分给乙,把另一个 200 分给丙,然后,甲成了监工,不干活,等乙和丙干完了他直接汇报工作。乙和丙在把 200 分拆成两个 100 的过程中,他俩又成了监工,这样,本来只需要 4 个工人的活,现在需要 7 个工人才能完成,其中有3个是不干活的。
?
ForkJoinPool 由 ForkJoinTask 数组和 ForkJoinWorkerThread 数组组成。ForkJoinTask 数组负责将存放程序提交给 ForkJoinPool 的任务;而 ForkJoinWorkerThread 数组负责执行这些任务,ForkJoinWorkerThread 体现的就是“工作窃取”算法。
- 当我们调用 ForkJoinTask 的 fork 方法时,程序会调用 ForkJoinWorkerThread 的 pushTask 方法异步地执行这个任务,然后立即返回结果。
- 当我们调用 ForkJoinTask 的 join 方法时,程序会阻塞当前线程并等待获取结果。
ForkJoinPool 使用 submit 或 invoke 提交的区别:invoke 同步执行,调用之后需要等待任务完成,才能执行后面的代码;submit 是异步执行,只有在 Future 调用 get 的时候会阻塞。
ForkJoinPool 继承自 AbstractExecutorService, 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。
原文链接:https://www.cnblogs.com/jmcui/p/11462860.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

下一篇:Spring源码解析系列汇总
- 学习Java 8 Stream Api (4) - Stream 终端操作之 collect 2020-06-11
- java学习之第一天 2020-06-11
- Java学习之第二天 2020-06-11
- Spring WebFlux 学习笔记 - (一) 前传:学习Java 8 Stream Ap 2020-06-11
- Linux简单命令的学习 2020-06-10
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
