
����HTTP�������,�Ӵ˲�����
2019-12-08 16:02:58��Դ������ �Ķ� ()

����HTTP�������,�Ӵ˲�����
������̸֮HTTP��������
���Ľ���?
����get���� ��Servlet�е���request.setCharacterEncoding()���ñ�����û������IJ�����ʹ���κα��뷽ʽ����������ݽ���û���κ�Ӱ��
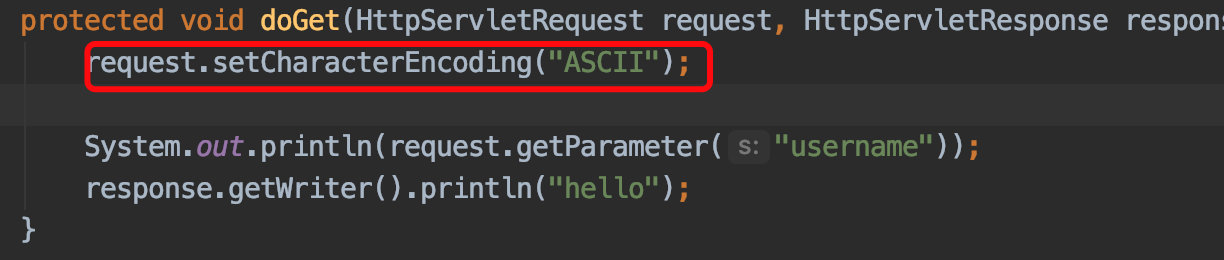
���������,��tomcat9֮��,��������setCharacterEncoding()����ʲô���붼��������,�������������ACSII,�����˾�˵��,�Dz�ͦ�õ�,�������������;
û�취,��ϲ�����Լ�Ϊʲô,ƾʲô������,���������������ʲô����?
��������һ��,ֻ����Ϊʲô����,û����Ϊɶ������,�����˻�˵���ñ���Ҫ���ڻ�ȡ����ǰ,�������,˵��һ��һ��,��������!
�������������д��һ����socket���� Ŀ�ľ��������������һ��HTTP�����ֶ����Ʊ��뻷��,
��һ�β���,ֱ�Ӱ�����д��url��,�����utf-8������������
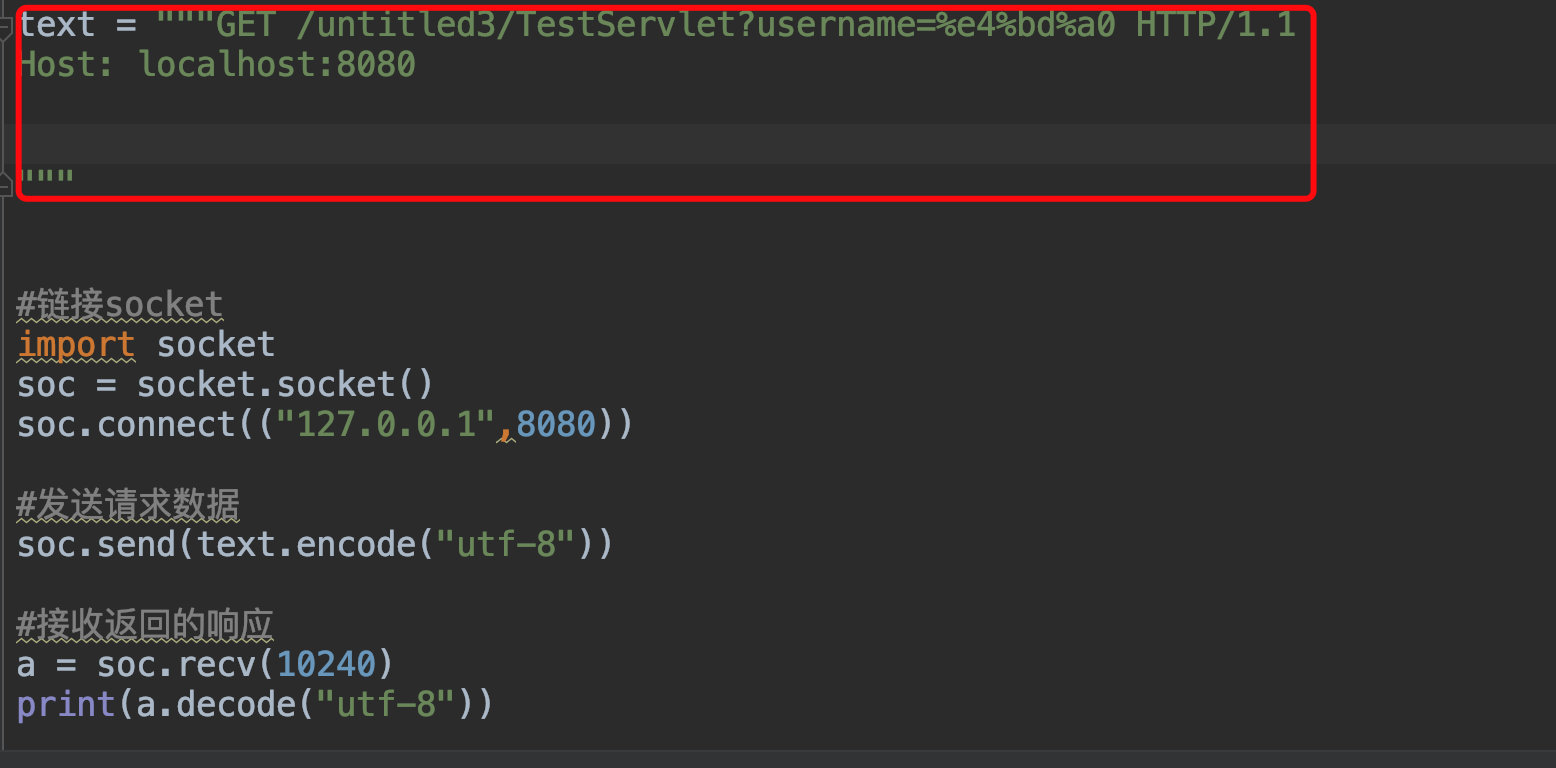
����������400�������ʧ��
Invalid character found in the request target. The valid characters are defined in RFC 7230 and RFC 3986��ɶ����?,ԭ��RFC 3986�й涨URL��ֻ��������24��Ӣ����ĸ�Լ��������ַ�,���ı�������Ӧ�Ķ����Ƴ����˹涨���ص��±���,��һ�����Ҫ
�����������URL�в��ܴ������IJ���,�Dz���,�ý���������,���Ǿͳ�����URLEncoding
URLEncoding
������Ҫ��url�а�������,�ͱ����Ȱ�����ת��Ϊ�������ַ�,��ԭ�����ַ�תΪ16���Ƶ��ַ�Ȼ����ÿ���ֽ�ǰ��һ��%,������������
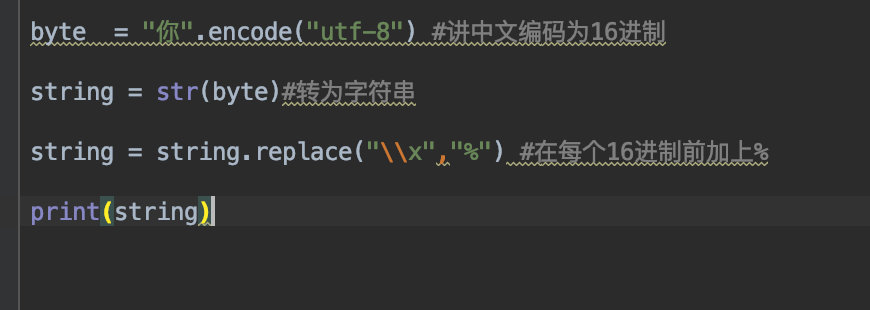
���:%e4%bd%a0
������ַ��õ���ҳ��URL����

û����
ģ���������������
ע������������Ȼ���ַ�����ʽ��,Ҫ��ͨ��socket����������ڽ��б���,��������Ҫ����ĵ�ַΪ/untitled3/TestServlet?username=��
������Ҫʹ��URLEncoding����תΪ����RFC 3986Ҫ����ַ���,�滻��ԭ����λ��ȥ
�������ĵ�ַΪ/untitled3/TestServlet?username=%e4%bd%a0
Ȼ���ڰ�URL�ŵ����ǵ�HTTP��������

��������doGet����

�����ɹ�

ok�������Ѿ��ɹ����������ĵ���ע�����ڷ�������ָ���ı���ΪASCII,��Ҳ����Ҫ�������Ҫ����,
�ܽ�ʱ��:
�ͻ��˷�������ʱ����һ�����������α���,
- ��һ���ǰ�����תΪ����Ҫ����ַ�(URLEncoding),ע����ַ�
- �ڶ��ξ������ǰ�����HTTP���ݽ���ͳһ����Ϊ������
��ô���Ƿ�������ִ�е����setCharacterEncoding��������һ����?
û�����ǵ�һ��,�����Ϊʲô���������������ֱ��붼���ᵼ�������ԭ����,
�����Ƿ�����ĺ����ڵڶ���,������������з�����������ASCII������http�������ݰ�,���еĵ�URLΪ/untitled3/TestServlet?username=%e4%bd%a0
�������URL�����κα�������ܽ���,��������,���������Ҫ������IJ�������(�ʺź����)�ó������з���URLEncoding,��ʱ�ķ��������������Ҫ��Ҫ���ַ�������ȡ16��������,��ͨ����������н��� ,
��tomcat9��Ĭ�ϵĽ��뷽ʽΪUTF-8,��������Ӧ��������,Ϊʲô������?
˵�˻�:
��˵:����get�������,����setCharacterEncoding��û���κ������,�������Ҫ����URLEncoding�Ľ��뷽ʽ,����ͨ��server.xml����

�چ���һ��,����post����,���ǵ������ǰ������������е�����,��������ö���post����û��Ч��,������������а�����������ô��,�ܼ�ֻҪ��ͻ��˱�����ͬ�Ľ��뷽ʽ����,ʹ��request.setCharacterEncoding����������,
��������,Ϊʲôpost�Ϳ�����? ��ΪRFC 3986ֻ��˵URL�е��ַ��ֽڱ�����ij����Χ��,û�������������е����ݷ�Χ,���Զ���������,�㰮���оͷ�����,
��Ҳ������ô����request.setCharacterEncodingֻ����������������Ľ��뷽ʽ,����url�еIJ������뷽ʽ�ͱ���ͬ server.xml������
�������post��������ʵ���Բ����ñ���ֻҪ�ͻ���post����ͷ��ContentType�������˱��뼴��,��Ҳ����ӡ֤��post�����������������������ݵĸ��ŷ���,
��Ϊʲô���ϲ����get��?��֪��,��������Ϊ��?,���˾͵������
������1¥�Ľ�����뷽��Ҳ�ǿ��Ե�
��ԭ���ǽ�ʹ�ô����������Ľ����ԭΪ�����ƣ�������ȷ������½���
��Ȼ�㲻�������ַ�ʽ��������Է�������ͬ�ı��뷽ʽ
ֻҪ����������ԭ��������������Ҳ��ӭ�ж�����
ԭ������:https://www.cnblogs.com/yangyuanhu/p/12005117.html
������������ԭ������ϵ
��ǩ��
��Ȩ��������վ���²��������磬������Ȩ������ϵ��west999com@outlook.com
�ر�ע�⣺��վ����ת���������۲�������վ�۵㣬��վ���ṩ����Ӱ��Ƭ���廭�������Ʒ������ʹ�ã�����ԭ������ϵ����Ȩ��ԭ��������

- ���Թ٣�����HTTPS��ȫ������HTTPS�ᱻץ�����һش��� 2020-06-06
- httpclient 5.0 ���ó�ʱʱ�� 2020-05-28
- ���˽� HTTP Э�� 2020-05-20
- Tomcat�ӽǿ�һ��http���� 2020-05-18
- java�澭�ռ� 2020-05-12
IDC��Ѷ�� ������Ѷ ע����Ѷ �й���Ѷ vps��Ѷ ��վ����
��վ��Ӫ�� ��վ���� ��ӯ�� �����Ż� ��վ�ƹ� �����Դ
��վ���ˣ� �������� ���˽��� ���˵��� ������
��ҵ��Ѷ�� �������� ������Ϸ �������� ��洫ý
�����̣� Asp.Net��� Asp��� Php��� Xml��� Access Mssql Mysql ����
������������ Web������ Ftp������ Mail������ Dns������ ��ȫ����
�������ɣ� �������� Word Excel Powerpoint Ghost Vista QQ�ռ� QQ FlashGet Ѹ��
��ҳ������ FrontPages Dreamweaver Javascript css photoshop fireworks Flash
������ƣ� Java���� C/C++ VB delphi

- ʲô�������Ե�ȡ�ź�����,��ô����
- ����������վ����2020�����
- springcloudѧϰ֮·: (һ) ��Ĵ�
- ����Gradle���̳���Could not install
- ����Ū����PKIX path building failed
- Tomcat��������:org.apache.catalina.L
- spring boot ����Check your ViewRes
- ����HttpClient���°���������ϵͳģ��
- ֻ�г���Ա���ܿ����ij��ƣ�������Ȼ��
- mybatis ע��@Results��@Result��@Resu