
初步了解JVM第二篇
2019-12-18 16:09:00来源:博客园 阅读 ()

初步了解JVM第二篇
在一篇《初步了解JVM第一篇》中,我们已经了解了:
- 类加载器:负责加载*.class文件,将字节码内容加载到内存中。其中类加载器的类型有如下:
- 启动类加载器(Bootstrap)
- 扩展类加载器(Extension)
- 应用程序类加载器(AppClassLoader)
- 用户自定义加载器(User-Defined)
- 执行引擎:负责解释命令,提交给操作系统执行。
- 本地接口:目的是为了融合不同的编程语言提供给Java所用,但是企业中已经很少会用到了。
- 本地方法栈:将本地接口的方法在本地方法栈中登记,在执行引擎执行的时候加载本地方法库
- PC寄存器:是线程私有的,记录方法的执行顺序,用以完成分支、循环、跳转、异常处理、线程恢复等基础功能。
那在这一篇中我们来聊一聊方法区、栈和堆。
继上一篇顺序的PC寄存器
5.方法区
在JVM的架构图中,Java栈、本地方法栈、程序计数器都是线程私有的。而方法区跟堆一样,是一个内存共享的区域,他的主要作用就是存储每一个类的结构信息,例如运行时常量池(Runtime Constant Pool)、字段和方法数据、构造函数和普通方法的字节码内容。
再简单来说方法区就是一个类的模板,在上一篇我们已经说了ClassLoader将class文件加载完成之后会把类的字节码内容放到方法区中,就像把Car.class文件通过类加载器加载后,会把car这个类的结构信息存放在方法区中。当你要实例化的时候再通过这个模板去new出你想要的car1,car2,car2,而你创建出来这些类对象是存放在堆(heap)中的。
图一是方法区中存放的内容
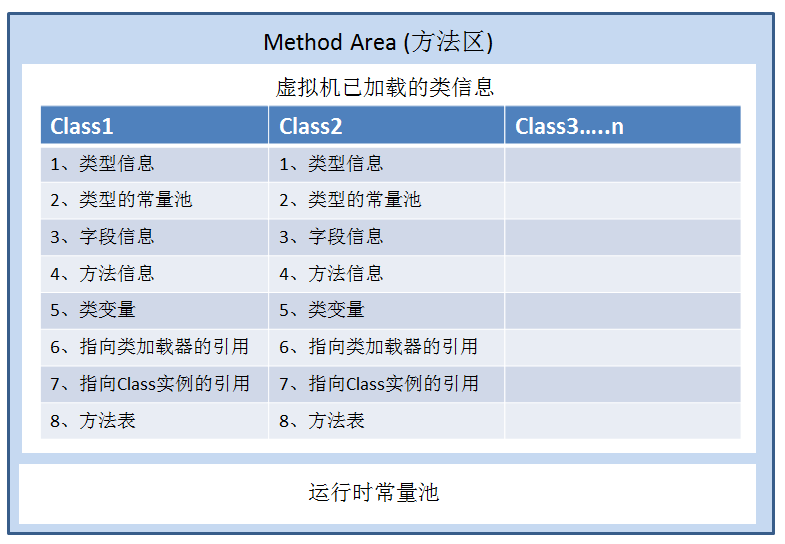 图一
图一
方法区的实现:
方法区只是一个定义、一个规范。在不同的虚拟机里头实现是不一样的。这里我们主要介绍的是JDK7和JDK8的实现方式
- JDK7:永久代(PermGen space)
- JDK8:元空间(Metaspace)
永久代
在JDK7中方法区的实现方式叫永久代,但是它存储的部分数据是存放在JVM的一块地方的,这会造成一个问题:
当类加载太多了,可能会导致内存栈溢出:java.lang.OutOfMemoryError: PermGen,这样一来就不够灵活,为了提高灵活性(这只是其中一个原因)就有了元空间
元空间:
在JDK8中,JVM的开发者就把永久代移除了,移至元空间中。其实作用是差不多的,只是元空间不再使用JVM的内存了,而是直接使用本地堆内存(native heap),说白了就是直接使用系统的内存,这样就几乎不会发生内存溢出的情况,提高了灵活性。
所以为什么在网上会看到关于方法区很多不同的说法就是因为方法区的实现方式在不同的JVM中是不同,最典型的就是永久代和元空间。
以上我们总结出:
- 方法区:类似一个模板,存储一个类的结构信息。
- 实现方法:
- 永久代:使用JVM的内存。
- 元空间:使用系统内存。
以上就是方法区的介绍,在介绍堆的时候还会提及。
6.Stack栈
栈是一个线程私有的,主要用来管理Java程序的运行。是在线程创建的时候创建的,它的生命周期跟随这线程的结束而结束,当线程结束了栈的内存也就释放了,对于栈来说,不会存在垃圾回收问题,因为只要线程一结束该栈就结束了。
栈中主要存储的内容:
- 8种基本数据类型
- 对象的引用变量
- 实例方法
栈就类似一个子弹夹,它的特点就是“后进先出,先进后出”,在Java中需要实现很多方法,而这些方法就是一个一个被压进栈中的,然后再依次调用。在平常中,我们所说的Java中的方法在栈其实有一个专有名词叫栈帧,栈帧主要存放三类数据:
- 本地变量(Local Variables):输入参数和输出参数以及方法内的变量。
- 栈操作(Operand Stack):记录出栈、入栈的操作。
- 栈帧数据(Frame Data):包括类文件、方法等等。
栈运行原理:
Java中的方法存放在栈中,但是这些方法到底是怎么执行的呢?
接下来我们就用一个例子来说明一下:
package testJVM;
public class TestStack {
public static void method_one(){
System.out.println("This is the method_one");
}
public static void method_two(){
System.out.println("This is the method_two");
}
public static void main(String[] args) {
System.out.println("This is the main method");
//调用方法一
method_one();
//调用方法二
method_two();
//输出程序结束
System.out.println("The program is finish");
}
}
以上的运行结果为:
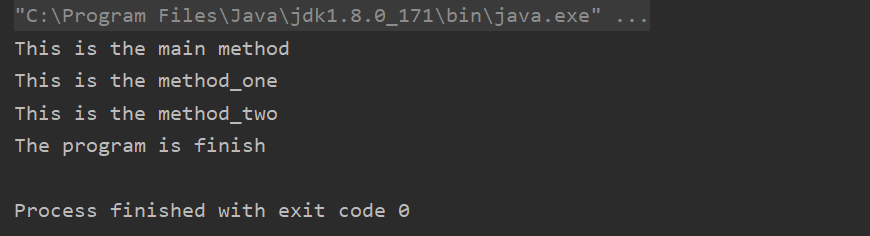
这样的输出结果,相信已经在大家的预料之中,但是这些方法在栈中是怎么运行的呢?废话不说,上图二
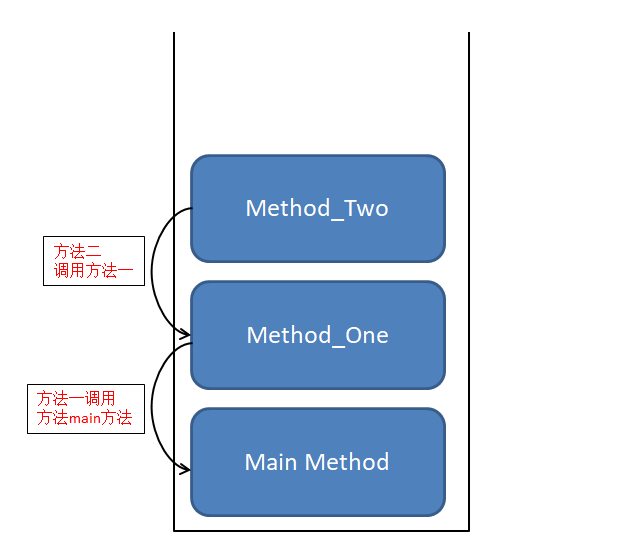 图二
图二
我们都知道main方法是一切程序的入口,所以程序一执行碰到的是main方法,main方法就第一个入栈了,所以他们的执行过程是这样的:
- 程序执行碰到第一个方法是main方法,main方法入栈。
- main方法遇到的方法是method_one,将其入栈。
- 再遇到的下一个方法是method_two,将其放入栈。
所以就形成了图二,当他运行的时候:
- 弹出method_two方法,在我们图三中的箭头就是PC寄存器的作用,所以在执行method_two,我们需要调用method_one方法。
- 弹出method_one,下一步,我们看到图二有指针指向main方法。
- 弹出main方法,全部出栈。
这样就形成了类似一条执行链,依次执行了main方法。
总结栈运行原理:
栈中的数据都是以栈帧(Stack Frame)的格式存在,栈帧是一个内存区块,是一个数据集,是一个有关方法(Method)和运行期数据的数据集,当一个方法A被调用时就产生了一个栈帧 F1,并被压入到栈中, A方法又调用了 B方法,于是产生栈帧 F2 也被压入栈, B方法又调用了 C方法,于是产生栈帧 F3 也被压入栈, 执行完毕后,先弹出F3栈帧,再弹出F2栈帧,再弹出F1栈帧…… 遵循“先进后出”和“后进先出”原则。每个方法执行的同时都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等信息,每一个方法从调用直至执行完毕的过程,就对应着一个栈帧在虚拟机中入栈到出栈的过程。栈的大小和具体JVM的实现有关,通常在256K~756K之间,与等于1Mb左右。
栈溢出
讲完了栈的内容,现在我们来看一个大家在实际开发中会碰到的一个错误,请看下列代码:
package testJVM;
public class TestStack {
public static void method_one(){
//递归调用
method_one();
}
public static void main(String[] args) {
method_one();
}
}
上述是一个递归调用的例子,现在来执行一下,看看会出现一个什么结果:

相信大家多多少少都会遇到过上述的错误,栈溢出。原因如下:
由于我们的方法method_one一直在递归调用自己,而且并没有停止的条件。所以method_one这个方法就会被一直压入栈中,JVM中的内存又是有限的,上述我们也提到了Java中的栈是随着线程的生命周期结束而结束的,不会存在垃圾回收机制,内存得不到释放而方法又不断的进栈,最终内存不够造成栈溢出的现象。图三
 图三
图三
以上就是本人对栈的理解,最后来到了重头戏堆(heap),那就下篇再进行介绍吧,哈哈哈。
在下篇将会介绍:
- 堆(heap)
- GC垃圾回收机制
原文链接:https://www.cnblogs.com/linzepeng/p/12063986.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- JVM常见面试题解析 2020-06-11
- 今天来介绍java 各版本的新特性,一篇文章让你了解 2020-06-10
- 是时候了解下软件开发的生命周期了! 2020-06-06
- 【JVM故事】了解JVM的结构,好在面试时吹牛 2020-06-06
- 你与面试官所了解的单例模式并不一样! 2020-06-06
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
