
Java爬取51job_2.0
2020-01-13 16:05:24来源:博客园 阅读 ()

Java爬取51job_2.0
大三上快结束了,看看之前的Java爬虫代码,感觉还是需要改进改进,就写了这个爬虫2.0版本,虽然还是爬的51job,但是更加的低耦合了,还加入了代理池和多线程的内容,爬取速度有了质的提升。
2.0和1.0的差距非常大,基本上可以把2.0当成一个新的项目来做了,中间也踩了许多坑,遇到许多问题,也一步一步改进了许多地方。
虽然51job随便爬也不封ip,感觉代理没有那么重要,但是多写个代理说不定以后爬取其他网站能用到呢,之前有一天我dos攻击一个钓鱼网站的时候就用到了这个代理池,所以我觉得蛮好的。
代码:https://github.com/255-1/Spider51job,下面开始介绍
总体介绍: 基本都用静态函数写的,除非涉及到多线程,爬虫嘛,面向过程就不错。
1)用本机ip爬取西刺代理第一页,然后检测这些ip是否可以用(高匿,延时低,可以使用),然后用ip多线程爬取后面的几百页,存入本地数据库,后面的爬取都是基于先用本机ip爬取,如果爬取失败(被封)就用代理尝试爬取。
2)爬取51job的职位url,根据提前配置好的关键字配置文件,爬取对应的职位网址,因为会有大量无用信息(51job关键字会匹配到公司名),所以要保证爬取的joburl的职位名带有关键字信息,存入本地文件中。
3)用这些joburl,再去爬取里面的职位信息,也存入到本地中。joburl和jobinfo的爬起都用多线程,为了节省内存,许多爬取的信息都需要及时保存并释放,所以在多线程中公共List到达一定数量就要保存,
但是频繁的连接和上锁数据库比较感觉低效,而且真正有用的就是jobinfo中的数据,其余的都是临时数据,所以就保存到本地中。
4)清洗,清洗需要清洗掉本地读取的jobinfo中有空值,发布时间是1周以前的,字段信息不正确等等信息,将清洗过的数据才存入到数据库中。
5)添加统一名,这是完成后添加的功能,因为如果读取出来职位名各有千秋,比如Java架构师,不知道是来自架构关键字得到的,还是Java关键字得到的,
所以需要和之前的joburl相联系得到一张本地的参照表来添加统一名,因为是项目都要完成加的,导致这个功能实现的极其仓促,功能时间复杂度是O(n^2),这个和项目中的其他部分关联不大,就是为后面nlp分析做一个准备。
基本规模:一次,38个关键字,本地joburl:7MB,本地jobinfo:150+MB,本地参照表:7MB,数据库信息约为5w+条,之后的增量信息约为1.5w+条,耗时50min左右,
首先可以看到这个项目关键字:定时,代理,多线程,数据库,阈值保存,清洗。先介绍几个基本的内容
代理选用西刺代理,或者快代理也行(改一下页面解析就行),主要是免费,如果爬取太猛的话,直接被封ip,等24小时左右,但我有之前的代理ip。
数据库依旧是MySQL而不是Redis,因为里面的文件保存大部分都是先本地存一份备份,最后一起放进数据库的,对于高速读取没那么大要求,就选用简单的了,如果要用Redis暂存的话,也就是多个序列化,没什么太大区别
阈值保存:爬取职位url和职位信息到一定数量就保存到本地,默认是500条,可以在参数中修改
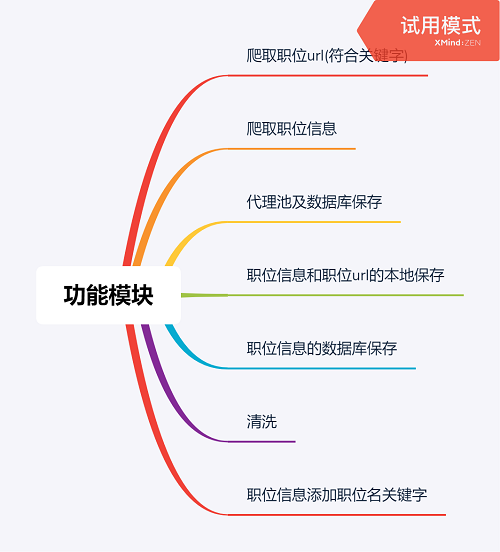
功能概述:
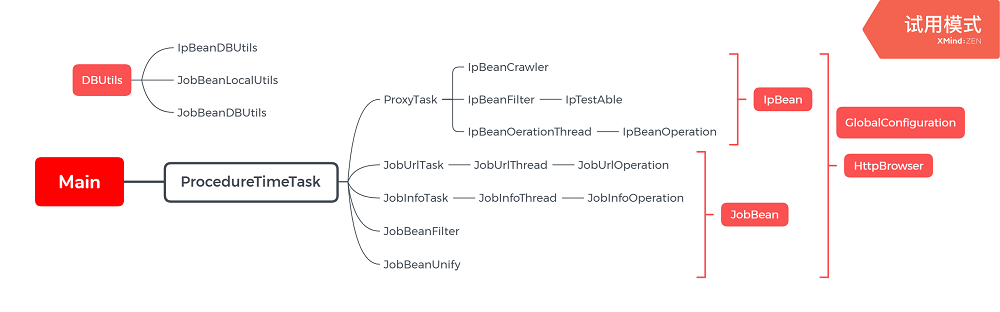
项目中类的关系:下面Main就是类间的联系,代理ip和51job基于不同的bean(可以看成最小单位),
DBUtils提供数据库的相关功能
HttpBrowser是共用的,用来对网页进行浏览的,
GlobalConfiguration中就是各种参数设置,比如用代理尝试的次数,相关的线程数,爬取的页数,测试ip可用性的网站,保存阈值等等
爬取的内容:


详细介绍: 就介绍主要的重点,像数据库操作,本地保存,网址元素的解析,这种就不写在这里了,具体的实现可以通过我的源代码进行查看,注释也写的挺多了
首先是:Main调用Procedure定时任务,直接介绍Procedure:整个爬虫流程,从代理ip爬取到职位爬取,到清洗,保存,添加统一名
/** * @author: PowerZZJ * @date: 2020/1/9 */ public class ProcedureTimeTask extends TimerTask { @Override public void run() { //jobUrl容器和jobinfo容器 List<String> jobUrlList = new ArrayList<>(); List<JobBean> jobBeanList = new ArrayList<>(); long start = System.currentTimeMillis(); //爬取代理ip并保存到数据库 ProxyTask.goCrawler(); //获取职位url列表,本地存入备份 JobUrlTask.goCrawler(); //获取职位信息列表,本地存入备份 jobUrlList = JobBeanLocalUtils.loadJobUrlList(GlobalConfiguration.getJoburlSaveName()); JobInfoTask.goCrawler(jobUrlList); //以上为爬虫 //------------------------------------------------------------------------------------------------ //------------------------------------------------------------------------------------------------ //下为入库清洗等操作 //本地读取,的操作 jobBeanList = JobBeanLocalUtils.loadJobBeanList(GlobalConfiguration.getJobinfoSaveName()); //进行清洗 JobBeanFilter.filter(jobBeanList); //存入数据库 JobBeanDBUtils.insertJobBeanList(GlobalConfiguration.getJobinfoTablename(), jobBeanList); //职位名关键字的添加 JobBeanUnify.addUnifyName(); long end = System.currentTimeMillis(); System.out.println("总计运行时间为" + (end - start) / 1000 + "s"); } }
ProxyTask:爬取代理ip的流程
public static void goCrawler() { List<IpBean> ipBeanList = new ArrayList<>(); //先从数据库中拿到上一次爬取的可以使用的代理ip ipBeanList = IpBeanDBUtils.selectIpBeanList(tableName); //本机ip爬取第一页 crawlerFirstPage(ipBeanList); //代理爬取后续pages页 crawlerOtherPages(ipBeanList); //清空原有数据库,插入现在可用的ip Connection conn = ConnectMySQL.getConnectionProxy(); DBUtils.truncateTable(conn, tableName); IpBeanDBUtils.insertIpBeanList(tableName, ipBeanList); }
JobUrlTask:爬取职位url的流程,需要从resource文件下的配置文件中获得需要爬取的关键字以及对应的基本url
/** * @Author: PowerZZJ * @Description:职位url爬取全过程 */ public static void goCrawler() { List<String> jobUrlList = new ArrayList<String>(); //从配置文件获取关键字和基页 HashMap<String, String> baseUrlMap = getkeyWordMap();
//每个关键字爬取 for (Map.Entry<String, String> entry : baseUrlMap.entrySet()) { System.out.println("开始爬取" + entry.getKey() + "的JobUrl"); crawlerPages(entry, jobUrlList); System.out.println("结束爬取" + entry.getKey() + "的JobUrl");
//保存未到阈值大小的joburl saveRemainList(entry, jobUrlList); } baseUrlMap.clear(); }
JobInfoTask:更具joburl爬取对应的职位职位信息。
/** * @Author: PowerZZJ * @Description:职位信息爬取全过程 */ public static void goCrawler(List<String> jobUrlList) { List<JobBean> jobBeanList = new ArrayList<>(); System.out.println("开始爬取jobInfo"); crawlerPages(jobUrlList, jobBeanList); //将小于保存阈值的残余JobBean进行保存 saveRemainList(jobBeanList); }
任务相关类就介绍完了,开始介绍一些基本的类
HttpBrowser类,作为连接网页获取网页内容的类,是后续所有爬取的都会使用的类,分为本机爬取和代理爬取。下面是主流程
如果了解一点Java爬虫的知识,连接的客户端大部分用HttpClients.createDefault(),但是这里不行,在大量爬取的时候会遇到Read0阻塞,必须设置SocketConfig相关参数
还有一个字符集问题,在51job是用的gbk字符集(f12搜索charset),但是西刺是utf8,我需要按照对应的字符集获得网址内容,然后转换成统一的utf8字符集,但是获得连接的EntityUtils只能连接一次,解决方案可以看我的另一篇博客,
/** * @Author: PowerZZJ * @param: url 网址 * @return: 字符串网页 * @Description:通过本机ip地址获得网站html */ public static String getHtml(String url) { if (url == null || url.length() == 0) return ""; //新建get请求 HttpGet httpGet = new HttpGet(url); //添加请求头配置 addHeaders(httpGet); addConfigs(httpGet); //接受响应 return getValidHttpResponse(httpGet); } /** * @Author: PowerZZJ * @param: url 网址,代理 * @return: 字符串网页 * @Description:通过代理ip地址获得网站html */ public static String getHtml(String url, HttpHost proxy) { if (url == null || url.length() == 0) return ""; //新建get请求,新建代理 HttpGet httpGet = new HttpGet(url); //添加请求头配置 addHeaders(httpGet); addConfigs(httpGet, proxy); //接受响应 return getValidHttpResponse(httpGet); }
然后是代理IP相关的类
IPTestAble:获得ip地址需要进行连通测试,但是上千个代理ip不可能让它一个个测试,所以用多线程一起测试,西刺代理一页大约100个代理ip,就开100个线程来测就行
/** * @Author: PowerZZJ * @Description:每个IPFilter线程各自检测自己ipMessage是否可用, * 不可用的加入到ipMessageList_remove中 */ @Override public void run() { String ipAddress = ipBean.getIpAddress(); String ipPort = ipBean.getIpPort(); HttpHost proxy = HttpBrowser.getHttpHost(ipAddress, ipPort); testPings(proxy, testWebs); }
IpBeanFilter: 过滤不是HTTPS协议,代理延迟大于2.0s的,以及上面IpTestAble不可用的
/** * @Author: PowerZZJ * @param: 代理ip列表 * @Description:过滤ip类型不是https以及延迟超过2秒的代理ip */ public static void filter(List<IpBean> ipBeanList) { if (ipBeanList == null) return; Iterator<IpBean> it = ipBeanList.iterator(); while (it.hasNext()) { IpBean ipBean = (IpBean) it.next(); //保留代理属性不为null或者不为不为空字符串 //保留延迟小于2s,保留HTTPS类型 if (ipBeanIsValid(ipBean) && typeIsValid(ipBean) && speedIsValid(ipBean)) { continue; } it.remove(); } } /** * @Author: PowerZZJ * @param: 代理ip列表 * @Description:过滤ip不可用的 使用多线程检验IP地址是否可用 */ public static void getAble(List<IpBean> ipBeanList) { if (null == ipBeanList) return; ipBeanList.removeAll(getRemoveListByThread(ipBeanList)); }
重头戏,IpBeanOperation:每个线程爬取西刺代理的一页信息,Operation中就是一个线程需要完成的事情,先尝试本机爬取网页获得信息,失败的话尝试使用代理爬取网页,这些信息保存在每个线程自己的一个tmp临时列表中,等待上锁总列表,然后把自己的内容加进总列表中
/** * @Author: PowerZZJ * @param: urls 爬取的网页列表 * @Description:作为每个线程的任务,需要上锁, * 每个线程爬取代理ip到tmp中,然后等待cpu调度整合进总代理ip列表 * 先尝试本机ip爬取,不行就用代理ip最多,尝试MAX_TRY_COUNT次。 */ public void getIpPool(List<String> urls) { if (urls == null) return; List<IpBean> ipBeanList_tmp = new ArrayList<>(); for (int i = 0; i < urls.size(); i++) { String url = urls.get(i); boolean success = tryFecterWithLocalIP(url, ipBeanList_tmp); //本机ip尝试爬取失败 if (false == success) { success = tryFecterProxyWithProxy(url, ipBeanList_tmp); //使用代理尝试依旧失败 if (false == success) { // System.out.println(Thread.currentThread().getName() + "使用代理超出" + MAX_TRY_COUNT + "次,放弃:" + url); continue; } } IpBeanFilter.filter(ipBeanList_tmp); IpBeanFilter.getAble(ipBeanList); addIntoIpBeanList(ipBeanList_tmp); } }
接着介绍爬取51job的相关类
JobUrlOperation:作用类似IpBeanOperation,每个线程爬取一页joburl
/** * @Author: PowerZZJ * @param: urls 爬取的网页列表 * keyWord 职位名关键字 * @Description:作为每个线程的任务,需要上锁ipBeanList, * 每个线程爬取代理ip然后等待机会整合进总代理ip列表 * 先尝试本机ip爬取,不行就用代理ip最多,尝试MAX_TRY_COUNT次。 */ public void getJobUrl(List<String> urls, String keyWord) { if (urls == null) return; if (keyWord == null || keyWord.length() == 0) return; List<String> jobUrlList_tmp = new ArrayList<>(); for (int i = 0; i < urls.size(); i++) { String url = urls.get(i); //尝试本机ip爬取 boolean success = tryFecterWithLocalIP(url, keyWord, jobUrlList_tmp); //尝试代理ip爬取 if (false == success && ipBeanList.size()>=MAX_TRY_COUNT) { success = tryFecterWithProxy(url, keyWord, jobUrlList_tmp); //依旧失败 if (false == success) { continue; } } addIntoJobUrlList(jobUrlList_tmp); //到达保存阈值JOBURLLIST_SAVE_SIZE就保存到本地 if (jobUrlListNeedSave()) { saveJobUrlList(keyWord); } } }
JobInfoOperation:和之前两个Operation一样,区别就是JobBean里面不是tmp临时列表,而是就一个JobBean,因为一个jobUrl就对应一个JobBean。但在主要函数里面写出来的感觉也差不多
/** * @Author: PowerZZJ * @param: urls 爬取的网页列表 * @Description:作为每个线程的任务,需要上锁jobBeanList, * 每个线程爬取职位信息然后等待机会整合进总职位信息列表 * 先尝试本机ip爬取,不行就用代理ip最多,尝试MAX_TRY_COUNT次。 */ public void getJobInfo(List<String> urls) { if (urls == null || urls.size() == 0) return; for (int i = 0; i < urls.size(); i++) { String url = urls.get(i).split(",")[1]; JobBean jobBean = new JobBean(); //尝试本机ip爬取 boolean success = tryFecterWithLocalIP(url, jobBean); if (success == false && ipBeanList.size()>=MAX_TRY_COUNT) { //尝试代理ip爬起 success = tryFecterWithProxy(url, jobBean); if (success == false) { continue; } } addIntoJobBeanList(jobBean); //到达保存阈值JOBBEANLIST_SAVE_SIZE就保存到本地 if (jobBeanListNeedSave()) { saveJobBeanList(); } } }
JobBeanFilter:清洗相关类,保证没有空值,而且值是合法的,然后对工资进行单位转换,全部转换成“万/月”,对发布时间要求一周内,全部转会成yyyy-MM-dd格式,对于公司发展目标保留数量最多的金融互联网医疗方向,并进行简化 。
JobBeanUnify:职位统一名添加,这是原本并没有想到的功能,是在爬虫基本都完成后才发现的,具体原因可以看最上面的总体介绍,来说说实现,就是把本地joburl带有关键字的职位url和数据库中清洗后的JobBean的职位url匹配,如果一样就存成一个reference文件,保存对应关系(职位名,公司名,日期也要放在对应关系,因为这三个唯一确定一行,是唯一键),然后读取这个对应关系添加关键字到数据库中,时间复杂度O(n^2)。
增量信息因为今天爬取并添加了统一名,那么unifyName肯定不为空了,所以从数据库select unifyName is null 的就是当天的增量信息
/** * @Author: PowerZZJ * @Description:数据库中加入统一命名列 * 此为后续增加功能,不与其余类有联系,添加功能的相关函数都在这个类中 */ public static void addUnifyName() { List<JobBean> jobBeanList = new ArrayList<>(); //对存入数据库的增量职位 jobBeanList = JobBeanDBUtils.selectJobBeanList(GlobalConfiguration.getJobinfoTablename()); //获取数据库提取出的名字的对应关键字文件 JobBeanUnify.getReference(jobBeanList); //数据库添加没有的关键字职位名 JobBeanUnify.addUnifyNameIntoDB(JobBeanUnify.loadReference(GlobalConfiguration.getReferenceSaveName())); }
原文链接:https://www.cnblogs.com/powerzzjcode/p/12186256.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- 国外程序员整理的Java资源大全(全部是干货) 2020-06-12
- 2020年深圳中国平安各部门Java中级面试真题合集(附答案) 2020-06-11
- 2020年java就业前景 2020-06-11
- 04.Java基础语法 2020-06-11
- Java--反射(框架设计的灵魂)案例 2020-06-11
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
