
kafka����ɨä
2020-02-07 16:03:29��Դ������ �Ķ� ()

һ��kafka����
1.1������
Kakfa��һ���ֲ�ʽ�Ļ��ڷ���/����ģʽ����Ϣ���У�message queue������ҪӦ���ڴ����ݵ�ʵʱ��������
1.2����Ϣ����
1.2.1����ͳ����Ϣ����&��ʽ����Ϣ���е�ģʽ
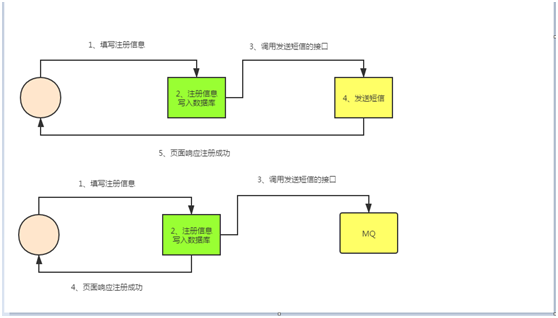
�����Ǵ�ͳ����Ϣ���У�����һ���û�Ҫע����Ϣ�����û���Ϣд�����ݿ���滹��һЩ�������̣����緢�Ͷ��ţ�����Ҫ����Щ���̴�����ɺ��ڷ��ظ��û�
����ʽ�Ķ����ǣ�����һ���û�ע����Ϣ������ֱ�Ӷ������ݿ⣬��ֱ�ӷ��ظ��û��ɹ�
1.2.2��ʹ����Ϣ���еĺô�
A�� ����
B�� �ɻָ���
C�� ����
D�� �����&��ֵ��������
E�� �첽ͨ��
1.2.3����Ϣ���е�ģʽ
A����Ե�ģʽ
��Ϣ�����߷�����Ϣ����Ϣ�����У�Ȼ����Ϣ�����ߴӶ�����ȡ������������Ϣ����Ϣ�����Ѻ����в��ڴ洢��������Ϣ�����߲��������ѵ��Ѿ������ѵ���Ϣ������֧�ִ��ڶ�������ߣ����Ƕ���һ����Ϣ���ԣ�ֻ�� ��һ�������߿������ѣ�����뷢����������ߣ�����Ҫ��η�������Ϣ
B������/����ģʽ��һ�Զ࣬��������������֮�������Ϣ��
��Ϣ�����߽���Ϣ������topic�У�ͬʱ�ж����Ϣ�����ߣ����ģ����Ѹ���Ϣ���͵�Ե�ķ�ʽ��ͬ��������topic����Ϣ�ᱻ���еĶ��������ѣ��������ݱ��������ģ�Ĭ����7�죬��Ϊ�����Ǵ洢ϵͳ��kafka��������ģʽ�ģ������ַ�ʽ��һ������������ȥ����ȥ���ѣ���ȡ����Ϣ��������������������Ϣ�������ߣ�����һ�־�������������������Ϣ�������ߣ����ƹ��ں�
1.3��kafka�Ļ����ܹ�
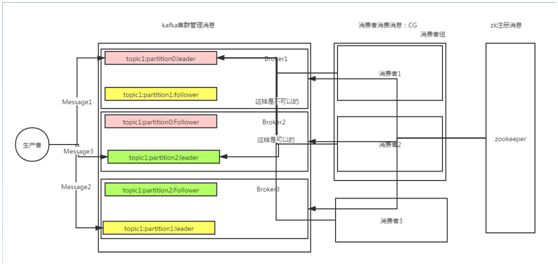
kafka�Ļ����ܹ���Ҫ��broker�������ߡ��������鹹�ɣ���ǰ������zookeeper
�����߸�������Ϣ
broker������Ϣ��broker�п��Դ���topic��ÿ��topic����partition��replication�ĸ���
�������鸺������Ϣ��ͬһ������������������߲�������ͬһ��partition�е����ݣ�����������Ҫ�������������������֮ǰ��һ������������100�����ݣ�������2������������100�����ݣ������������������������������������ߵĸ���ҪС��partition�ĸ�������Ȼ�ͻ���������û��partition�������ѣ������Դ���˷�
ע�����Dz�ͬ������������������ǿ���������ͬ��partition����
Kakfa���Ҫ�����Ⱥ����ֻ��Ҫע�ᵽһ��zk�оͿ����ˣ�zk�л�������Ϣ���ѵĽ��Ȼ���˵ƫ������������λ��
0.9�汾֮ǰƫ�����洢��zk��0.9�汾֮��ƫ�����洢��kafka�У�kafka������һ��ϵͳ��topic��ר�������洢ƫ���������ݣ�ΪʲôҪ�ģ���Ҫ�ǿ��ǵ�Ƶ������ƫ��������zk��ѹ���ϴ���kafka�����Լ��Ĵ���Ҳ�ϸ���
1.4��kafka��װ
A��Kafka�İ�װֻ��Ҫ��ѹ��װ���Ϳ�����ɰ�װ
tar -zxvf kafka_2.11-2.1.1.tgz -C /usr/local/��
B���鿴�����ļ�
[root@es1 config]# pwd /usr/local/kafka/config [root@es1 config]# ll total 84 -rw-r--r--. 1 root root 906 Feb 8 2019 connect-console-sink.properties -rw-r--r--. 1 root root 909 Feb 8 2019 connect-console-source.properties -rw-r--r--. 1 root root 5321 Feb 8 2019 connect-distributed.properties -rw-r--r--. 1 root root 883 Feb 8 2019 connect-file-sink.properties -rw-r--r--. 1 root root 881 Feb 8 2019 connect-file-source.properties -rw-r--r--. 1 root root 1111 Feb 8 2019 connect-log4j.properties -rw-r--r--. 1 root root 2262 Feb 8 2019 connect-standalone.properties -rw-r--r--. 1 root root 1221 Feb 8 2019 consumer.properties -rw-r--r--. 1 root root 4727 Feb 8 2019 log4j.properties -rw-r--r--. 1 root root 1925 Feb 8 2019 producer.properties -rw-r--r--. 1 root root 6865 Jan 16 22:00 server-1.properties -rw-r--r--. 1 root root 6865 Jan 16 22:00 server-2.properties -rw-r--r--. 1 root root 6873 Jan 16 03:57 server.properties -rw-r--r--. 1 root root 1032 Feb 8 2019 tools-log4j.properties -rw-r--r--. 1 root root 1169 Feb 8 2019 trogdor.conf -rw-r--r--. 1 root root 1023 Feb 8 2019 zookeeper.properties����
C���������ļ�server.properties
����broker.id �����kafka��Ⱥ����ÿ���ڵ��Ψһ��־��

D������kafka�����ݴ洢·��

ע�����Ŀ¼�²�����������kafka��Ŀ¼����Ȼ�ᵼ��kafka��Ⱥ������
E�������Ƿ����ɾ��topic��Ĭ�������kafka��topic�Dz�����ɾ����

F��Kafka�����ݱ�����ʱ�䣬Ĭ����7��

G��Log�ļ����Ĵ�С�����log�ļ�����1g�ᴴ��һ���µ��ļ�

H��Kafka���ӵ�zk�ĵ�ַ������kafka�ij�ʱʱ��
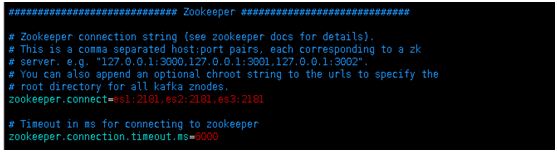
J��Ĭ�ϵ�partition�ĸ���

1.5������kafka
����kafka������ϨCdaemon����ôkafka�����ػ����̵ķ�ʽ����
bin/kafka-server-start.sh --daemon config/server.properties�鿴�����Ƿ�ɹ�
jps -l���Կ�����ͼ���������̣��ֱ���zookeeper��jps��kafka

ֹͣ
bin/kafka-server-stop.sh config/server.properties�������broker
�������ͬһ̨�������������broker���Ը��ƶ��config/server.propoerties�ļ�

��������server.properties�ļ��������ҿ�����������broker��������broker֮ǰ����Ҫ����server.properties�ļ��е��������ԣ�broker.id��listeners��log.dirs����֤���������Բ�ͬ��
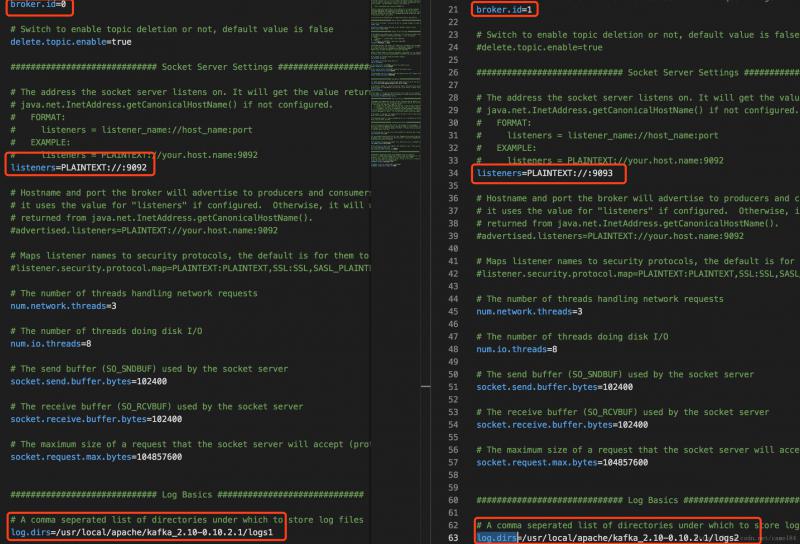
���ھͿ�����������kafka broker������
bin/kafka-server-start.sh --daemon config/server1.properties
bin/kafka-server-start.sh --daemon config/server2.properties
bin/kafka-server-start.sh --daemon config/server3.properties1.6��kafka����
A���鿴��ǰkafka��Ⱥ���е�topic
bin/kafka-topics.sh --zookeeper localhost:2181 --listע�⣺�������ӵ�zookeeper�����������ӵ�kafka
B������topic��ָ����Ƭ��������
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic demo --partitions 10 --replication-factor 3�Czookeeperָ��zookeeper�ĵ�ַ�Ͷ˿�
�Cpartitionsָ��partition������
�Creplication-factorָ�����ݸ���������
Ҳ����˵�������100�����ݣ��ᱻ�зֳ�10�ݣ�ÿһ������������������ڲ�ͬ��partition�
�����ǰkafka��Ⱥֻ��3��broker�ڵ㣬��replication-factor������3�ˣ���������Ӵ�������Ϊ4����ᱨ��
C��ɾ��topic
ɾ��֮ǰ����Ҫ�Ƚ�server.properties�ļ��е�����delete.topic.enable=true����һ�£�����ִ��ɾ���������Ч��
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic demo
���Կ��������topicֻ�DZ����ɾ���������topic���������ݽ�������ô�鿴topic list��ʱ����ʾ��topicΪ���ɾ����ֱ��û�пͻ���ʹ�ø�topic���Ż������ı�ɾ����
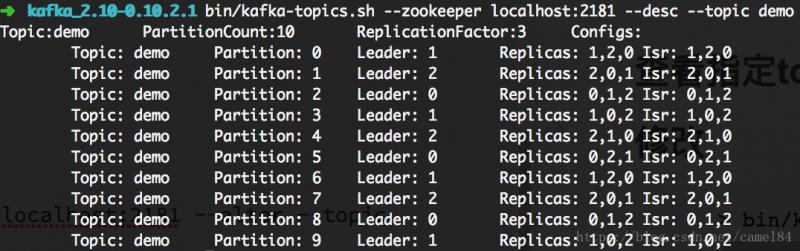
D���鿴topic��Ϣ
bin/kafka-topics.sh --zookeeper localhost:2181 --desc --topic demo�ӵ�һ�ſ��Կ���topic�����ƣ�partition����������������
�ӵڶ��ſ�ʼ��������������У���ʾpartition��������ֱ��ʾ��topic���ơ�partition��ţ���partions��leader broker��ţ�������ŵ�broker��ţ�ͬ��broker��š�
ʹ��3�ݸ��������DZ�֤���ݵĿ����ԣ���ʹ����̨broker���������ˣ�Ҳ�ܱ�֤kafka���������С�
��Ϊ���ǿ���������broker����Ӧ��broker.id�ֱ�Ϊ0��1��2����ÿ��partion���������������Ծ��а����е�broker��ʹ���ˣ�ֻ����ÿ��partition��leader��ͬ��
E����
�����������partion��������10��partition���ӵ�20��
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic demo --partitions 20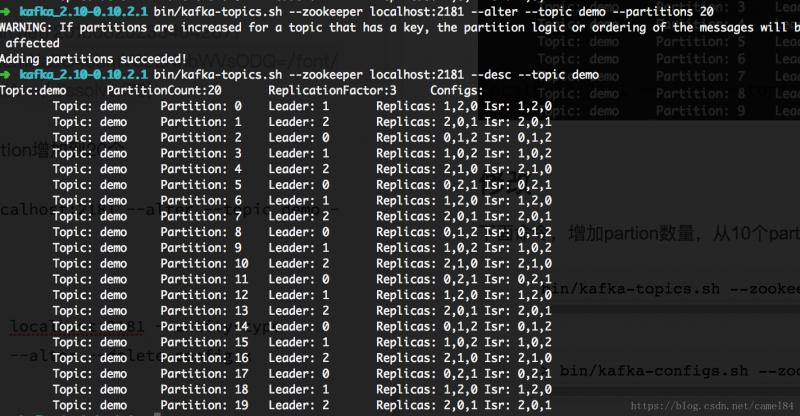
���Ǽ���partition�Dz������ġ����ִ�����õ�partition���٣����׳�һ��������ʾpartition����ֻ������
1.7������������Ϣ
����������������Ϣ��kafka�Դ�һ�������ߺ������ߵĿͻ���
A������һ�������ߣ�ע���ʱ����9092�˿ڣ����ӵ�kafka��Ⱥ
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic demoB������һ�������ߣ�ע���ʱ���ӵĻ���9092�˿ڣ���0.9�汾֮ǰ���ӵĻ���2181�˿�
�������from-beginningָ���ӵ�һ�����ݿ�ʼ����
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic demo --from-beginningע�������ָ������������������ļ��Ļ���Ĭ��ÿ�������߶����ڲ�ͬ����������
����kafka�ܹ�����
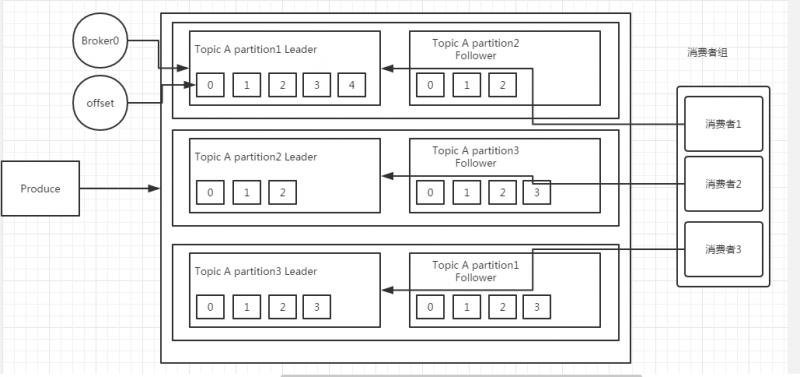
Kafka���ܱ�֤��Ϣ��ȫ������ֻ�ܱ�֤��Ϣ��partition��������Ϊ������������Ϣ���ڲ�ͬ��partition�������
2.1��kafka��������
Kafka�е���Ϣ����topic���з���ģ�������������Ϣ��������������Ϣ����������topic��
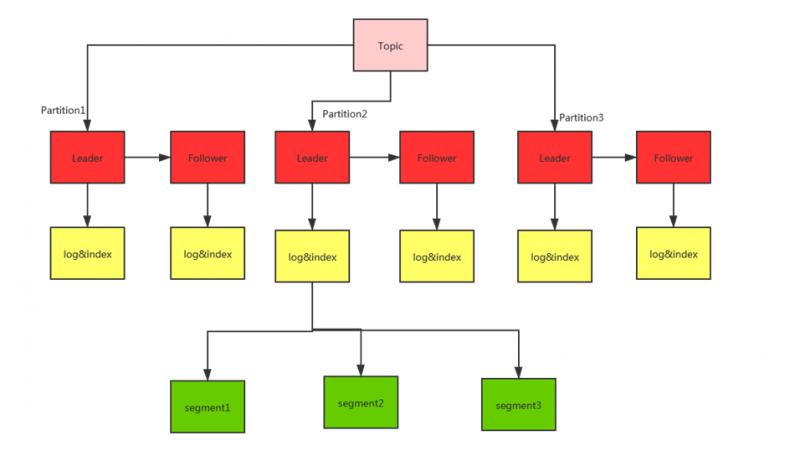
Topic��һ�����ϵĸ����partition�������ϵĸ���
ÿ��partition���и����ĸ���
ÿ��partition��Ӧ��һ��log�ļ�����log�ļ��д洢�ľ������������ɵ����ݣ����������ɵ����ݻ�ϵ��ӵ���log���ļ�ĩ�ˣ���ÿ�����ݶ����Լ���offset�������߶���ʵʱ��¼�Լ����ѵ����Ǹ�offset���Ա������ʱ����ϴε�λ�ü������ѣ����offset�ͱ�����index�ļ���
kafka��offset�Ƿ���������ģ������ڲ�ͬ����������˳��ģ�kafka����֤���ݵ�ȫ������
2.2��kafkaԭ��
������������������Ϣ����ӵ�log�ļ���ĩβ��Ϊ��ֹlog�ļ����������ݶ�λЧ�ʵ��£�Kafka���÷�Ƭ�������Ļ��ƣ���ÿ��partition��Ϊ���segment��ÿ��segment��Ӧ2���ļ�----index�ļ���log�ļ�����2���ļ�λ��һ����ͬ���ļ����£��ļ��е���������Ϊtopic����+�������

Indx��log���ļ����ļ����ǵ�ǰ�����������С�����ݵ�offset
Kafka��ο��ٵ����������أ�
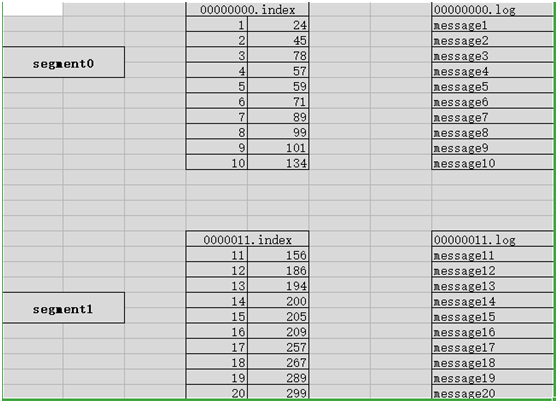
Index�ļ��д洢�����ݵ�������Ϣ����һ����offset���ڶ����������������Ӧ��log�ļ��е�ƫ��������������ȥ���ļ���ʹ��seek�������õ�ǰ����λ��һ�������Ը�����ҵ�����
���Ҫȥ����offsetΪ3�����ݣ�����ͨ�����ַ��ҵ��������ĸ�index�ļ��У�Ȼ����ͨ��index��offset�ҵ�������log�ļ��е�offset�������Ϳ��Կ��ٵĶ�λ�����ݣ�������
����kakfa��Ȼ�����ݴ洢�ڴ����У��������Ķ�ȡ�ٶȻ��Ƿdz����
����kafka�������ߺ�������
3.1��kafka��������
Kafka�ķ�����ԭ����Ҫ�����ṩ����������ܣ���Ϊ��д��partitionΪ��λ��д�ģ�
�������߷�����Ϣ�Ƿ��͵��ĸ�partition���أ�
A���ڿͻ�����ָ��partition
B����ѯ���Ƽ�����Ϣ1ȥp1����Ϣ2ȥp2����Ϣ3ȥp3����Ϣ4ȥp1����Ϣ5ȥp2����Ϣ6ȥp3 ��������������
3.2 kafka��α�֤���ݿɿ����أ�ͨ��ack����֤
Ϊ��֤�����߷��͵����ݣ��ܿɿ��ķ��͵�ָ����topic��topic��ÿ��partition�յ������߷��͵����ݺ���Ҫ�������߷���ack��ȷ���յ���������������յ�ack���ͻ������һ�ֵķ��ͣ��������·�������


��ôkafkaʲôʱ���������߷���ack
ȷ��follower��leaderͬ����ɣ�leader�ڷ���ack�������ߣ���������ȷ��leader�ҵ�֮������follower��ѡ�ٳ��µ�leader�����ݲ��ᶪʧ
�Ƕ��ٸ�followerͬ����ɺ���ack
����1�������Ѿ����ͬ�����ͷ���ack
����2��ȫ�����ͬ�����ŷ���ack��kafka�������ַ�ʽ��
���õڶ��ַ������������³�����leader�յ����ݣ����е�follower����ʼͬ�����ݣ�������һ��follower��Ϊij�ֹ��ϣ�һֱ�����ͬ������leader��Ҫһֱ���£�ֱ����ͬ����ɣ����ܷ���ack�������ͷdz�Ӱ��Ч�ʣ����������ô�����

Leaderά����һ����̬��ISR�б���ͬ�����������ã���ֻ��Ҫ����б����е�follower��leaderͬ������ISR�е�follower������ݵ�ͬ��֮��leader�ͻ�������߷���ack�����follower��ʱ��δ��leaderͬ�����ݣ����follower������ISR�����ʱ����ֵҲ���Զ���ģ�ͬ��leader���Ϻͻ��ISR��ѡ���µ�leader
��ôѡ��ISR�Ľڵ��أ�
����ͨ�ŵ�ʱ��Ҫ�죬Ҫ��leaderҪ���Ժܿ�����ͨ�ţ����ʱ��Ĭ����10s
Ȼ��Ϳ�leader���ݲ�࣬��Ϣ����Ĭ����10000��������汾���Ƴ���
Ϊʲô�Ƴ�����Ϊkafka������Ϣ���������͵ģ����Ի�һ˲��leader������ɣ�����follower��û����ȡ�����Ի�Ƶ�����߳�����ISR��������ݻᱣ�浽zk���ڴ��У����Ի�Ƶ���ĸ���zk���ڴ档
���Ƕ���ijЩ��̫��Ҫ�����ݣ������ݵĿɿ���Ҫ���Ǻܸߣ��ܹ��������ݵ�������ʧ������û��Ҫ��ISR�е�followerȫ�����ܳɹ�
����kafkaΪ�û��ṩ�����ֿɿ��Լ����û����Ը��ݿɿ��Ժ��ӳٽ���Ȩ�⣬������kafka�����������ã�
acks��������
A��acksΪ0
�����߲���ack��ֻ����topic�����ݾͿ����ˣ���������ݵĸ��ʷdz���
B��ackΪ1
Leader���̺�ͻ᷵��ack���������ݶ�ʧ���������leader��ͬ����ɺ���ֹ��ϣ����������ݶ�ʧ
C��ackΪ-1��all��
Leader��follower��ISR�����̲Ż᷵��ack�����������ظ����������leader�Ѿ�д��ɣ���followerͬ����ɣ������ڷ���ack�ij��ֹ��ϣ������������ظ�����������£����Ҳ�������ݶ�ʧ�����������follower��leaderͨ�Ŷ�����������ISR��ֻ��һ��leader�ڵ㣬���ʱ��leader������̣��ͻ᷵��ack�������ʱleader���Ϻͻᵼ�¶�ʧ����
3.3 Kafka��α�֤�������ݵ�һ���ԣ�
ͨ��HW����֤
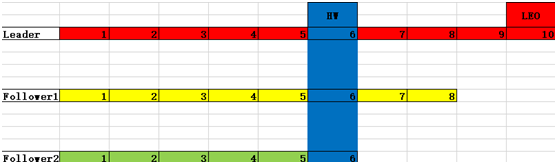
LEO��ָÿ��follower������offset
HW����ˮλ����ָ�������ܼ���������offset��LSR��������С��LEO��Ҳ����˵������ֻ�ܿ���1~6�����ݣ���������ݿ�������Ҳ���Ѳ���
����leader�ҵ����統ǰ����������8�������ݺ�leader���ˣ���ʱ����f2��Ϊleader��f2������û��9�������ݣ���ô�����߾ͻᱨ�������������HW���������ֻ��¶���ٵ����ݸ������ߣ��������������
3.3.1��HW��֤���ݴ洢��һ����
A��Follower����
Follower�������Ϻ�ᱻ��ʱ���LSR������follower�ָ���follower���ȡ���صĴ��̼�¼���ϴε�HW��������log�ļ�����HW�IJ��ֽ�ȡ������HW��ʼ��leader����ͬ�����ȸ�follower��LEO���ڵ��ڸ�Partition��hw����follower��leader�Ϳ������¼���LSR
B��Leader����
Leader�������Ϻ��ISR��ѡ��һ���µ�leader��֮��Ϊ�˱�֤�������֮�������һ���ԣ������follower���Ƚ����Ե�log�ļ�����hw�IJ��ֽص�����leader�Լ�����ص�����Ȼ����µ�leaderͬ������
ע�⣺�����Ϊ�˱�֤�������������ݴ洢��һ���ԣ������ܱ�֤���ݲ���ʧ���߲��ظ�
3.3.2��һ�Σ��ݵ��ԣ�����֤���ݲ��ظ�
Ack����Ϊ-1������Ա�֤���ݲ���ʧ�����ǻ���������ظ���at least once��
Ack����Ϊ0������Ա�֤���ݲ��ظ������Dz��ܱ�֤���ݲ���ʧ��at most once��
�������������Ƽ�ã�����ô�죿���ʱ��;�������Exactl once����һ�Σ�
��0.11�汾�������ݵ��Խ��kakfa��Ⱥ�ڲ��������ظ�����0.11�汾֮ǰ���������ߴ��Լ�������
����������ݵ��ԣ���ackĬ�Ͼ���-1��kafka�ͻ�Ϊÿ�������߷���һ��pid����δÿ����Ϣ����seqnumber�����pid��partition��seqnumber����һ������kafka��Ϊ���ظ����ݣ��Ͳ������̱��棻������������߹ҵ���Ҳ������������ظ������������ݵ��Խ���ڵ��λỰ�ĵ��������������ظ��������ڷ�������߿�Ự���������ظ������������
3.4 kafka��������
3.4.1 ���ѷ�ʽ
��Ϣ����������������Ϣ�ķ�ʽ��push���Ź��ںţ���pull��kafka����pushģʽ������Ӧ�������ʲ�ͬ�������ߣ���Ϊ���ѷ�����������broker�����ģ�����Ŀ���Ǿ����������ĵ��ٶȴ�����Ϣ�������������������������������������Ϣ�����͵ı��־��Ǿܾ������Լ�����ӵ������pull�ķ�ʽ���������ߵ������������ʵ�������������Ϣ
Pull��ģʽ����֮�������kafkaû�����ݣ������߿��ܻ�������ѭ����һֱ���ؿ����ݣ������һ�㣬kafka������������������ʱ��ش���һ��timeout�����������ʱû�����ݿɹ����ѣ�������ȴ�һ��ʱ���ڷ���
3.4.2 �����������
һ�����������ж�������ߣ�һ��topic�ж��partition�����Ա�Ȼ���漰��partition�ķ������⣬��ȷ���ĸ�partition���ĸ�������������
Kafka�ṩ���ַ�ʽ��һ������ѯ��RountRobin������topic����Ч��һ���ǣ�Range�����ڵ���topic��Ч
��ѵ��
ǰ����������Ҫһ����������������߶��ĵ�����ͬ��topic��
ͬһ������������������߲���ͬʱ����ͬһ������
������������������һ��topic��9������
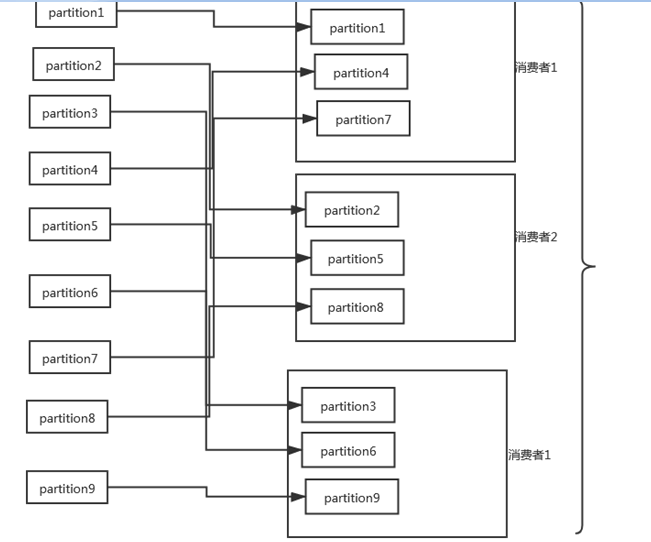
���һ��������������2�������ߣ��������������ͬʱ����2��topic��ÿ��topic��������partition
���Ȼ��2��topic����һ�����⣬Ȼ�����topic��partition��hash��Ȼ���ڰ���hash����Ȼ����ѵ�����һ�����������е�2��������
��������������ķ�ʽ���ĵ��أ�
������3��topic��ÿ��topic��3��partition��һ��������������2�������ߡ�������1����topic1��topic2��������2����topic2��topic3����ô�����ij�����ʹ����ѵ�ķ�ʽ����topic�ͻ�������
������������ַ�ʽ������
������2��topic��ÿ��topic��3��partition��һ���������� ��2�������ߣ�������1����topic1��������2����topic2������ʹ����ѵ�ķ�ʽ����topicҲ��������
������ѵ�ķ�ʽ����kafkaĬ�ϵķ�ʽ��ʹ����ѵ�ķ�ʽ����topic��ǰ����һ�����������е����������߶��ĵ�������һ���ģ�
Range��
�ǰ��յ���topic�����ֵģ�Ĭ�ϵķ��䷽ʽ
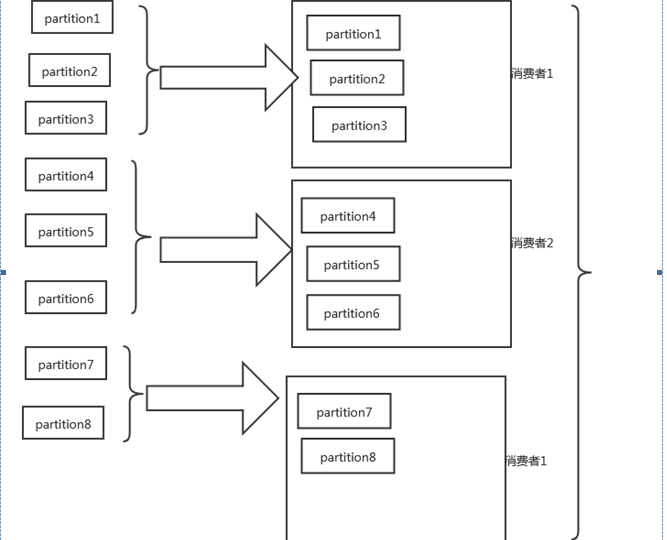
Range�������������������ݲ����������
������������ӣ�һ���������鶩����2��topic���ͻ����������1����4��partition��������һ��������ֻ����2��partition
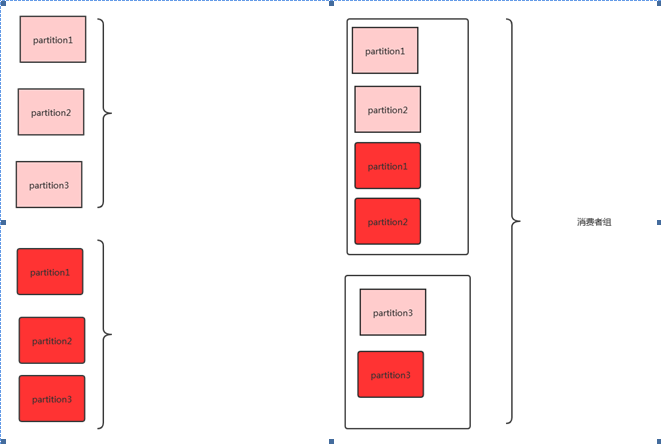
��������ʲôʱ��ᴥ���أ�������������������߸����仯��ʱ�ᴥ���������Ե��������������������������ߣ�������������
3.4.3 offset����
���������������ѹ����п��ܻ���ֶϵ�崻��ȹ��ϣ������ָ�����Ҫ�ӹ���ǰ��λ�ü������ѣ�������������Ҫʵʩ��¼�Լ������ĸ�offset���Ա���ϻָ����������
Offset�����λ����2����һ��zk��һ����kafka
���ȿ���offset���浽zk
���������顢topic��partition����Ԫ��ȷ��Ψһ��offset
�������������е�ij�������߹ҵ�֮���ߵ��������ǿ����õ����offset��
Controller����ڵ��zkͨ�ţ�ͬ�����ݣ�����ڵ����˭��������˭����ע��controller��˭����controller�������ڵ��controller��Ϣ����ͬ��
3.4.5�������������
����������id
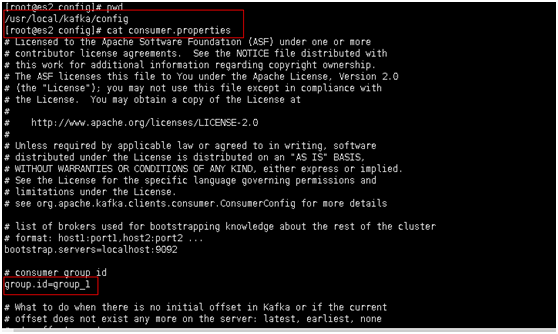
����һ�������߷���3������

ָ�������������������ߣ��������������ߣ����Կ���ÿ��������������һ������



����ʾ�²�ͬ���������ͬһ��topic�ģ����ǿ���2�������ߵ������߶����ѵ�ͬһ������
�ٴ�����һ�������ߣ������������������һ����������

�ġ�Kafka�ĸ�Ч��д����
4.1���ֲ�ʽ����
��ڵ㲢�в���
4.2��˳��д����
Kafka��producer�������ݣ�Ҫд�뵽log�ļ��У�д�Ĺ�����һֱ�ӵ��ļ�ĩβ��Ϊ˳��д�����������ݱ�����ͬ���Ĵ��̣�˳��д�ܵ�600M/S�������дֻ��100K/S��������̵Ļ�е�ṹ�йأ�˳��д֮���Կ죬����Ϊ��ʡȥ�˴�����ͷѰַ��ʱ��
4.3���㸴�Ƽ���
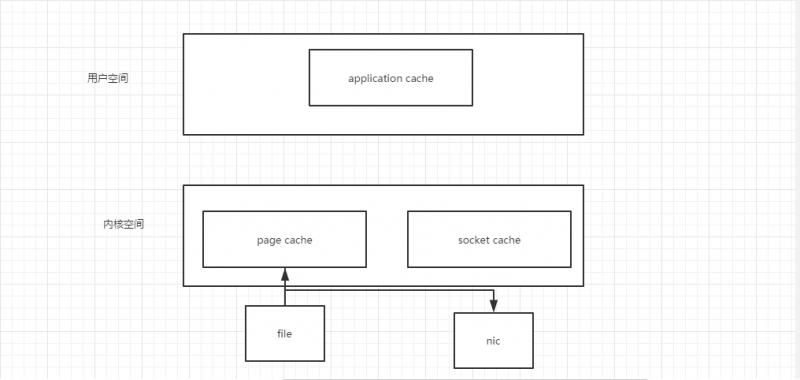
��������£��Ȱ����ݶ����ں˿ռ䣬�ڴ��ں˿ռ�����ݶ����û��ռ䣬Ȼ���ڵ�����ϵͳ��io�ӿ�д���ں˿ռ䣬������д��Ӳ����
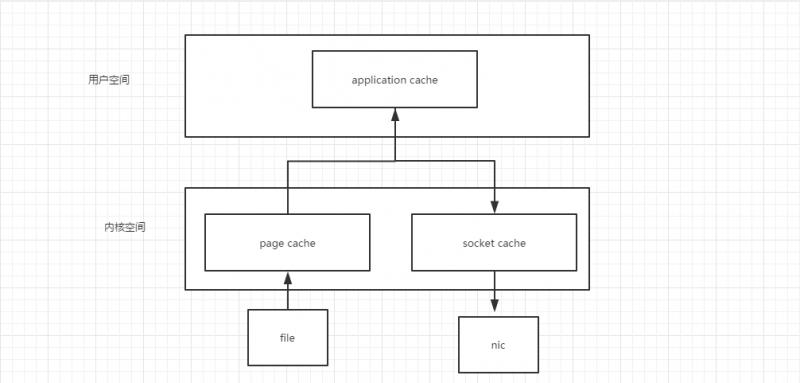
Kafka���������ģ�ֱ�����ں˿ռ���תio��������kafka�����ܷdz���
�塢 zookeeper��kafka�е�����
Kafka��Ⱥ����һ��broker�ᱻѡ��Ϊcontroller�����������Ⱥbroker�������ߣ����е�topic�ķ������������leaderѡ�ٵȹ���
���
https://www.cnblogs.com/bainianminguo/p/12247158.html
ԭ������:https://www.cnblogs.com/chen-chen-chen/p/12272267.html
������������ԭ������ϵ
��ǩ��
��Ȩ��������վ���²��������磬������Ȩ������ϵ��west999com@outlook.com
�ر�ע�⣺��վ����ת���������۲�������վ�۵㣬��վ���ṩ����Ӱ��Ƭ���廭�������Ʒ������ʹ�ã�����ԭ������ϵ����Ȩ��ԭ��������

- ����Դ���� | Kafka��Ⱥ���������Ϣ�洢������� 2020-06-11
- kafka 2020-06-09
- JAVA�Զ���ע�� 2020-06-01
- DDD֮2������� 2020-05-30
- ���������ķֲ�ʽ����������ϢϵͳKafka֮ProducerԴ����� 2020-05-30
IDC��Ѷ�� ������Ѷ ע����Ѷ �й���Ѷ vps��Ѷ ��վ����
��վ��Ӫ�� ��վ���� ��ӯ�� �����Ż� ��վ�ƹ� �����Դ
��վ���ˣ� �������� ���˽��� ���˵��� ������
��ҵ��Ѷ�� �������� ������Ϸ �������� ��洫ý
�����̣� Asp.Net��� Asp��� Php��� Xml��� Access Mssql Mysql ����
������������ Web������ Ftp������ Mail������ Dns������ ��ȫ����
�������ɣ� �������� Word Excel Powerpoint Ghost Vista QQ�ռ� QQ FlashGet Ѹ��
��ҳ������ FrontPages Dreamweaver Javascript css photoshop fireworks Flash
������ƣ� Java���� C/C++ VB delphi

- ʲô�������Ե�ȡ�ź�����,��ô����
- ����������վ����2020�����
- springcloudѧϰ֮·: (һ) ��Ĵ�
- ����Gradle���̳���Could not install
- ����Ū����PKIX path building failed
- Tomcat��������:org.apache.catalina.L
- spring boot ����Check your ViewRes
- ����HttpClient���°���������ϵͳģ��
- ֻ�г���Ա���ܿ����ij��ƣ�������Ȼ��
- mybatis ע��@Results��@Result��@Resu