
一篇文章看懂微服务
2020-02-10 16:06:02来源:博客园 阅读 ()

一篇文章看懂微服务
微服务的概念
传统单体大项目的缺点:
- 系统较大、较复杂,开发难度大
- 部署速度慢
- 难以升级、维护
微服务:
- 小:微服务是体积较小的功能单元,将一个大项目拆分为多个微服务
- 独:服务都是独立的,运行在单独的JVM进程中,需要单独部署、维护,服务可以使用不同的编程语言来写,可以使用不同的数据库
- 轻:服务之间的通信机制是轻量级的
- 松:服务之间是松耦合的
微服务的优点:
- 易于开发、维护,扩展性好
- 启动快,修改局部无需重新部署整个项目
- 技术栈不受限制
微服务的缺点:
- 要部署、维护多个服务,运维要求高
- 单体应用使不使用分布式都行,微服务一般都要使用分布式,对开发人员的技术要求较高
- 调整接口成本高,需要同时修改调用它的其它微服务
- 代码重复多。单体应用把要重复调用代码封装为工具类,项目中直接调用即可;每个微服务都是独立的,不能调用其它微服务中的类,需要把要用的类copy到要本服务中。
微服务的拆分与设计
如果项目拆分过粗,那和单体应用差不多;如果拆分过细,则服务太多,管理难度大,服务调用开销大。
拆分的大原则:一个模块不依赖、或极少依赖其它模块,但需要给多个模块、客户端提供数据(一般2个或2个以上)。
微服务的设计原则:
- 单一职责:每个服务只管本模块的业务,不处理其他模块的业务。
- 服务自治:每个服务都是单独的,单独进行开发、测试、部署。
- 轻量级通信:服务之间的通信要是轻量级的、跨平台、跨语言,这样可以让服务的开发不收技术种类限制。
- 接口明确:服务之间往往要相互调用,设计服务之间的接口时,要将接口设计得通用些、考虑全面些,后续维护、升级时不轻易修改接口。
常用的微服务框架
- Spring Cloud
- Dubbo 阿里巴巴的开源框架
springboot、springcloud的区别
- springboot是对spring的封装,提供了很多开箱即用的微服务功能(业余),有默认配置,简单修改下就可以使用
- springcloud是一个专业的微服务框架,需要自己写很多代码
springboot、springcloud可以联合部署。
前台如何访问、调用微服务?
比如查询订单信息,要访问订单的微服务,有时候需要访问多个微服务。
微服务部署在不同的服务器上,一般是无状态的,不保存用户的状态信息(比如是否已登录),需要找一个地方来保存用户的状态信息、检查用户权限。
一般要通过API Gateway来访问微服务。
API Gateway,其实就是一个代理,代理所有微服务,请求交给API Gateway,由API Gateway调用相应的微服务来处理。
API Gateway提供统一的接口,供前台调用,并保护用户状态、检查用户权限。
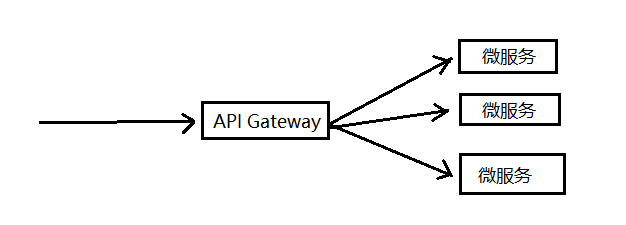
API Gateway只是一个称谓,有多种实现:可以是MVC框架,可以是node.js服务器,也可以是其它的。
服务之间如何通信(相互调用)?
服务之间有2种通信方式:
(1)同步调用
简单、一致性强,但容易出现调用问题、体验差,特别是调用层次多的时候(服务A调用服务B,服务B又要调用其它服务,类似于递归)。
同步调用有2种常见的实现技术:
- REST。基于HTTP,简单灵活,跨语言、跨客户端(只要SDK封装HTTP就可以调用),应用广泛。springboot使用的就是REST。
- RPC。传输更高效,更安全可控,但需要有统一开发规范、统一的服务器框架才能展现这些优点。Dubbo使用的就是RPC。
要应用广泛、兼容多种情况,需要提供大量代码处理各种情况,移植性倒是上去了,性能就一般般(REST);
对环境有要求,针对特定情况,移植性差一些,但性能杠杠的(RPC)。
(2)异步消息
在分布式系统中用得较多,Kafka就是一种异步消息技术。能降低服务之间的耦合,可以保证被调用者的性能。
同步消息:妈耶,一大堆服务调用我,我得加紧干,加大功率——强度大了可能直接拉闸,被搞垮;
异步消息:就像食堂的打饭大妈,不管排多长的队,依然不紧不慢地打饭,学生(其它服务的调用)都得排着队等着——想搞垮我,不存在的。
付出的代价:数据一致性差。
你倒是不紧不慢干着,人家都等着你,等了老半天,这期间数据可能被其它服务修改了、不一致了。
所以往往要写数据一致模块来保证数据的一致性。
服务发现
通常要把一个服务拷贝一下,部署到多个服务器上,实现服务的分布式。
运行过程中,一些服务器可能会下线,负载大的时候也会增加节点(服务器),节点会变化,要发给哪个节点来处理?
找到、发现某个节点,使用这个节点来处理请求,所以叫做服务发现,常用的技术是zookeeper。
使用zookeeper来做服务的分布式管理:
服务提供者(各服务节点)把信息(本机地址、所提供的的服务)注册到zookeeper上,并实时更新信息。zookeeper根据这些注册信息、调用特定算法来计算,确定要调用哪个节点来处理请求,即发现一个服务。
那把zookeeper放到客户端、还是放到服务器端?
- 放到服务器端:简单,服务信息对前台透明,小公司用得多。
- 放到客户端:架构简单、扩展灵活,只依赖服务注册器,但客户端要维护所有服务的地址,技术难度大,需要微服务框架的支持(比如Dubbo),大公司用得多。
访问量上升的处理
访问量上升,对某一服务的调用增加,如果不加处理,节点负载太大,会影响所有调用此服务的前台。
常用的处理方式:
- 重试机制
- 限流
- 熔断机制
- 负载均衡
- 降级(本地缓存)
原文链接:https://www.cnblogs.com/chy18883701161/p/12292352.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

上一篇:JVM内存模型
- Java--注解 2020-06-11
- 今天来介绍java 各版本的新特性,一篇文章让你了解 2020-06-10
- 我终于看懂了HBase,太不容易了... 2020-06-03
- 到底是程序员的世界有 10 种人,你是哪一种?看懂的都是老司 2020-06-02
- 只有程序员才能看懂的车牌,懂得自然懂 2020-05-31
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
