
透彻分析和解决一切javaWeb项目乱码问题
2020-02-13 16:04:29来源:博客园 阅读 ()

透彻分析和解决一切javaWeb项目乱码问题
前言
乱码是我们在程序开发中经常碰到且让人头疼的一件事,尤其是我们在做javaweb开发,如果我们没有清楚乱码产生的原理,碰到乱码问题了就容易摸不着头脑,无从下手。
乱码主要出现在两部分,如下:
第一,浏览器通过表单提交到后台,如果表单内容有中文,那么后台收到的数据可能会出现乱码。
第二,后端服务器需要返回给浏览器数据,如果数据中带有中文,那么浏览器上可能会显示乱码。
接下来我们逐一分析乱码产生的原因,以及如何解决乱码问题。
一、后端收到浏览器提交的中文乱码
这里又分为get请求和post请求。
get请求
get请求,请求参数中带有中文,后台接收会出现乱码,原因是tomcat默认编码是“ISO-8859-1”,所以tomcat会使用“ISO-8859-1”对中文进行编码,该编码不支持中文,所以后台接收到就乱码了。解决方式有两种。
param = new String(param.getBytes("ISO-8859-1"),"utf-8");- 修改tomcat编码为"utf-8",不建议使用这种方式。
post请求
post请求,出现乱码的原因同get请求,解决方式比较简单,如下:
request.setCharacterEncoding("utf-8");设置请求参数的编码格式为“utf-8”,这样就不会有问题了。
二、后端返回中文给浏览器发生乱码
后端返回数据给浏览器,一般也有两种形式,一种是response.getOutputStream(),一种是response.getWriter()。
两者区别以及使用规则
- getOutputStream()就是得到了OutputStream,用来向客户端(浏览器)输出任何数据,如果输出的是字符,会被转换成二进制输出,如果字符中出现中文,那么会出现“java.io.CharConversionException:Not an ISO 8859-1 character:”异常
- getWriter()是对outputStream进行了包装,用来输出字符用的。
因此,调用requonse.getWriter()方法时可实现文本字符串数据输出,调用response.getOutputStream()方法可现实字节流数据的输出。所以,如果要输出图片等二进制数据时,需要使用response.getOutputStream。
注意,getOutputStream()和getWriter()不能同时使用,否则会抛出”getWriter() has already been called for this response“异常。
区别讲完了,下面我们主要还是通过实践分析下乱码产生的原理。
response.getOutputStream().print()
返回英文数据就不说了,没什么问题,看下返回中文是什么效果;
@RequestMapping("/helloworld.do")
public void helloworld(HttpServletRequest request, HttpServletResponse response) throws IOException {
String str = "中国加油,武汉加油";
response.getOutputStream().print(str);
}结果如下:
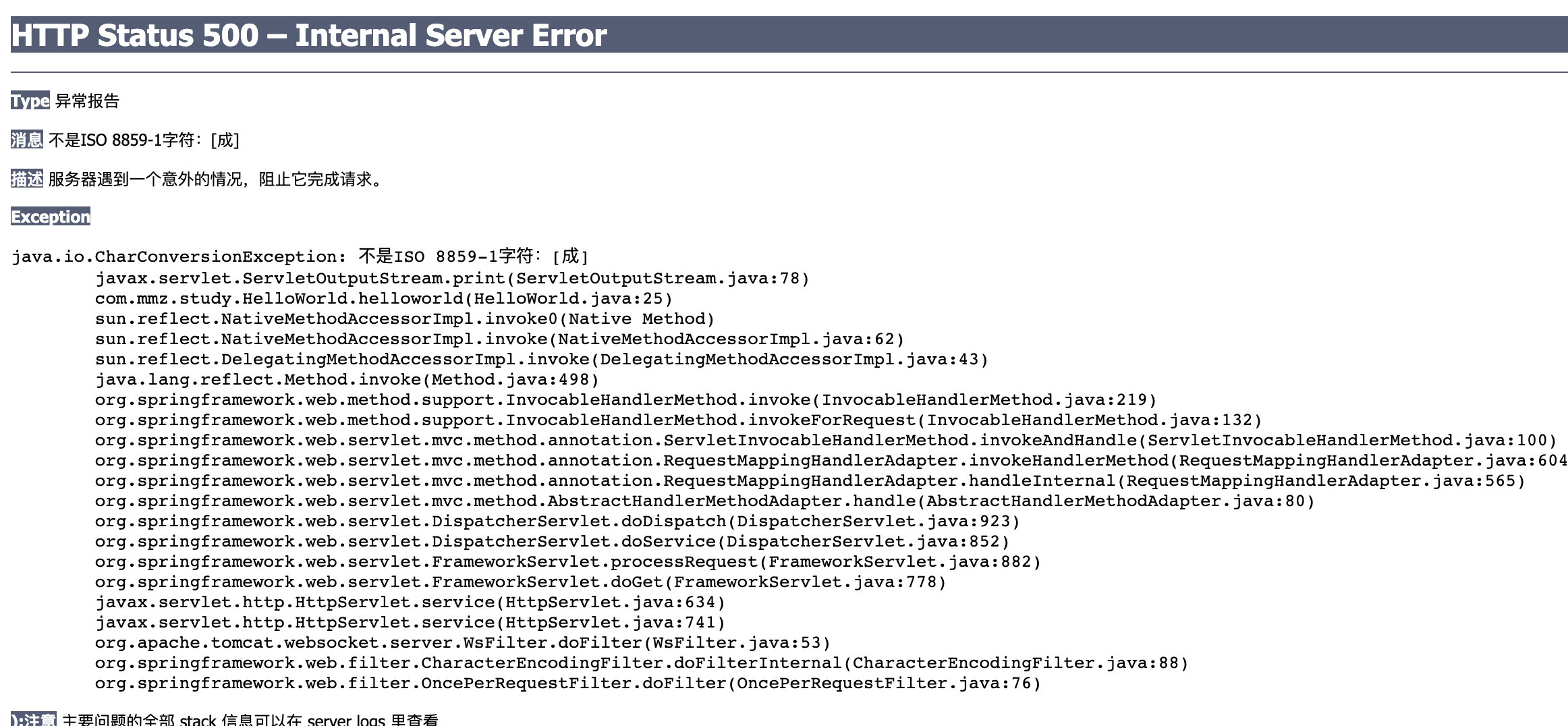
分析:
OutPutStream是输出二进制数据的,所以需要对字符串改成二进制输出,Tomcat使用的是"ISO8859-1"编码对其进行转换,而中文对”ISO859-1“不支持,所以就抛异常了。
response.getOutputStream.write()
同样的,我们再来看下输出中文会怎么样。
@RequestMapping("/helloworld.do")
public void helloworld(HttpServletRequest request, HttpServletResponse response) throws IOException {
String str = "中国加油,武汉加油";
response.getOutputStream().write(str.getBytes());
}页面输出结果如下:
涓浗鍔犳补锛屾姹夊姞娌?分析:
在java中,String的getBytes()方法是得到一个操作系统默认的编码格式的字节数组,我电脑的系统是macos,默认编码格式是utf-8,返回给浏览器是utf-8编码格式的字节数组,但是浏览器默认是"gbk"编码解析,所以就乱码了。
既然这样,那我们换成“gb2312”编码(gb2312编码是gbk编码的一种)试试呢?
@RequestMapping("/helloworld.do")
public void helloworld(HttpServletRequest request, HttpServletResponse response) throws IOException {
String str = "中国加油,武汉加油";
response.getOutputStream().write(str.getBytes());
}页面输出:
中国加油,武汉加油原理我们弄清楚了,但是在项目开发中,我们需要编码统一,最常用的就是中文字符编码"UTF-8",可是按照我们的理解,如果我们直接response.getOutputStream().write(str.getBytes("utf-8"));肯定会乱码,我们需要用某种方式,告诉浏览器,你要用我指定的“utf-8”编码接受我返回的中文。response.setContentType("text/html;charset=UTF-8")这样就完事了,看看效果吧。
@RequestMapping("/helloworld.do")
public void helloworld(HttpServletRequest request, HttpServletResponse response) throws IOException {
String str = "中国加油,武汉加油";
response.setContentType("text/html;charset=utf-8");
response.getOutputStream().write(str.getBytes("utf-8"));
}页面输出:
中国加油,武汉加油response.getWriter()
前面已经总结过了,response.getWriter()跟response.getOutputStream()不一样,outputStream是输出二进制的,writer是输出字符串的。response.getWriter()输出也有两种方法,一种是print(),一种是write(),其实两者在处理乱码这一块没有什么区别,就不分开讲述了。
示例:
@RequestMapping("/helloworld.do")
public void helloworld(HttpServletRequest request, HttpServletResponse response) throws IOException {
String str = "中国加油,武汉加油";
response.getWriter().print(str);
}页面输出:
?????????分析:
同样的,Tomcat默认的编码是ISO 8859-1,当我们输出中文数据的时候,Tomcat会依据ISO 8859-1码表给我们的数据编码,中文不支持这个码表呀,所以出现了乱码。
这个时候response.setContentType("text/html;charset=UTF-8")又派上用场了。
@RequestMapping("/helloworld.do")
public void helloworld(HttpServletRequest request, HttpServletResponse response) throws IOException {
String str = "中国加油,武汉加油";
response.setContentType("text/html;charset=utf-8");
response.getWriter().print(str);
}页面输出:
中国加油,武汉加油在这里,response.setContentType("text/html;charset=UTF-8")做了两件事,response.setCharacterEncoding("UTF-8");和response.setHeader("Content-Type", "text/html;charset=UTF-8");具体就是,第一,输出中文”中国加油,武汉加油“的时候,对中文进行”utf-8“编码;第二,告诉浏览器,你也要用"utf-8"来显示我返回的中文。
最后
对于springMVC项目,如何解决乱码问题呢?项目中一般会在web.xml中配置编码过滤器。配置如下:
<filter>
<filter-name>encodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>encodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>这样能保证请求的参数按照指定的编码格式进行编码,简单翻看下过滤器源码如下:
@Override
protected void doFilterInternal(
HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
if (this.encoding != null && (this.forceEncoding || request.getCharacterEncoding() == null)) {
request.setCharacterEncoding(this.encoding);
if (this.forceEncoding) {
response.setCharacterEncoding(this.encoding);
}
}
filterChain.doFilter(request, response);
}代码中有两处重要的地方值得注意,分别是request.setCharacterEncoding(this.encoding);和response.setCharacterEncoding(this.encoding);前者表示我们对请求过来的参数使用指定的"utf-8"进行编码,后者便是,返回给浏览器时,后端返回字符的编码是“utf-8”。
好了,经过以上分析是不是乱码也没有那么可怕了。只要明白其中的缘由,解决起来就是一行代码或者几行配置的事儿了,如果大家觉得有帮助,不妨点赞支持一下?
如果大家觉得我写的不错、清晰易懂的话,可以关注我的公众号“灰太狼学爪哇”,不定期分享原创技术文章,与君共勉。
原文链接:https://www.cnblogs.com/xiaoming0601/p/12304418.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

上一篇:Spring资源访问
- 聊聊微服务架构及分布式事务解决方案! 2020-06-10
- 这可能是目前最透彻的Netty讲解了... 2020-06-08
- 解决IDEA Maven下载依赖包速度慢问题 2020-06-05
- 数据结构:用实例分析ArrayList与LinkedList的读写性能 2020-06-04
- 数据分析 | 数据可视化图表,BI工具构建逻辑 2020-06-02
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
