
JVMбЇЯАЃЈ4ЃЉЃКРЌЛјЛиЪе
2020-03-13 16:02:01РДдДЃКВЉПЭдА дФЖС ()

JVMбЇЯАЃЈ4ЃЉЃКРЌЛјЛиЪе
НјааРЌЛјЛиЪеЕФЧјгђЃКЖбЃЌЗНЗЈЧј
дЫааЪБЪ§ОнЧјЕФЁОЖбЁПКЭЁОЗНЗЈЧјЁПдкЫљгаЯпГЬМфЪЧЙВЯэЕФЃЌНјааЛиЪе
ЁОеЛЁПЪЧЯпГЬЫНгаЕФЃЌЫљгаВЛНјааЛиЪе
ЪВУДЧщПіЯТНјааЛиЪеЃК
ПЊЗЂжаОГЃгаетбљЕФаДЗЈ
List<String> list = new ArrayList<>(); list.add(); list.add(); list.add(); //вЕЮёТпМДњТы return ;
етбљЪЧВЛКЯРэЕФЃЌlistЪЧвЛИіОжВПБфСПЃЌЪЙгУЭъБЯжЎКѓгІИУИГжЕЮЊnull
етЖЮДњТыЃЌШЛКѓЪЙгУВЮЪ§-XX:+PrintGCDetails -XX:+UseSerialGC
public class ReferenceCountingGC { private static final int MB = 1024 * 1024; Object instance = null; private byte[] size = new byte[2 * MB]; public static void main(String[] args) { ReferenceCountingGC o1 = new ReferenceCountingGC(); ReferenceCountingGC o2 = new ReferenceCountingGC(); o1.instance = o2; o2.instance = o1; o1 = null; o2 = null; System.gc(); } }
ДђгЁжагаетбљвЛЖЮЃК[УћГЦЃКGCЧАФкДцеМгУ->GCКѓФкДцеМгУЃЈИУЧјФкДцзмДѓаЁЃЉ]
[Tenured: 0K->643K(349568K), 0.0016527 secs]
в§гУМЦЪ§ЦїЃКУПЕБвЛИіЖдЯѓНјаавЛДЮв§гУЕФЪБКђЃЌМЦЪ§ЦїМгвЛЃЛУПЕБв§гУЪЇаЇЕФЪБКђЃЌМЦЪ§ЦїМѕвЛЃЛЕБвЛИів§гУМЦЪ§ЦїЕШгк0ЕФЪБКђЃЌБэЪОетИіЖдЯѓВЛЛсдйБЛв§гУСЫ
o1КЭo2newЭъГЩКѓЪЧЧПв§гУЃЌШЛКѓНјааЛЅЯрв§гУЃЌзюКѓЫфШЛИГжЕЮЊnullСЫЃЌЕЋЪЧв§гУМЦЪ§ЦїВЛЮЊ0ЃЌАДРэРДЫЕЪЧВЛЛиЪеЕФЃЌЪЕМЪЩЯНјааСЫЛиЪе
ЫФжжв§гУЃК
ЃЈ1ЃЉЧПв§гУЃКДњТыжагаУїЯдЕФnew Object()етРрв§гУЃЌжЛвЊв§гУЛЙДцдкЃЌФЧУДОЭВЛЛсНјааЛиЪеЃЌШчЙћФкДцВЛЙЛЃЌХзГіOOMвьГЃ
ЃЈ2ЃЉШэв§гУЃКЕБФкДцЙЛгУЪБЃЌВЛНјааЛиЪеЃЛЕБФкДцВЛЙЛгУЪБЃЌНјааЛиЪеЃЌШѕв§гУЕФЪЙгУШчЯТЃЈjava.lang.ref.SoftReferenceЃЉ
Object object = new Object(); SoftReference test = new SoftReference(object);
ЃЈ3ЃЉШѕв§гУЃКЩњДцЕНЯТвЛДЮРЌЛјЛиЪежЎЧАЃЌЮоТлФкДцЪЧЗёЙЛгУЃЌЖМЛсЛиЪеШѕв§гУЙиСЊЕФЖдЯѓЃЈjava.lang.ref.WeakReferenceЃЉ
ЃЈ4ЃЉащв§гУЃКУЛгаЪЕМЪгУЭОЃЌЮЈвЛгУЭОЪЧдкЖдЯѓБЛРЌЛјЛиЪеЧАЪеЕНвЛИіЯЕЭГЭЈжЊЃЈjava.lang.ref.PhantomReferenceЃЉ
ПЩДяадЗжЮіЃК
дкJavaжаЃЌПЩзїЮЊGC RootsЕФЖдЯѓАќРЈЯТУцЫФжжЃК
ЃЈ1ЃЉащФтЛњеЛЃЈеЛжЁжаЕФБОЕиБфСПБэЃЉжав§гУЕФЖдЯѓ
ЃЈ2ЃЉЗНЗЈЧјжаРрОВЬЌЪєадв§гУЕФЖдЯѓ
ЃЈ3ЃЉЗНЗЈЧјжаГЃСПв§гУЕФЖдЯѓ
ЃЈ4ЃЉБОЕиЗНЗЈеЛжаJNIЃЈNativeЗНЗЈЃЉв§гУЕФЖдЯѓЃЌР§ШчЯТУцетОфЛАЕїгУtest(person)КѓЕФPerson
private native void test(Person person);
ИљОнЭМЫуЗЈЃЌПЩвдЭЈЙ§ЖдЯѓВуВув§гУевЕНGC RootЃЌЪЧВЛПЩЛиЪеЕФЃЌжЛвЊКЭGC RootЖЯПЊЃЌОЭЪЧПЩЛиЪеЕФ
OopMapЃК
дке§ЪНЕФGCжЎЧАЃЌвЊНјааПЩДяадЗжЮіРДБъМЧГіНЋРДПЩФмвЊаћИцЫРЭіЕФЖдЯѓ
ШчЙћУПДЮGCЕФЪБКђЖМвЊБщРњЫљгаЕФв§гУЃЌетбљЕФЙЄзїСПЪЧЗЧГЃДѓЕФ
вђЮЊдкПЩДяадЗжЮіЕФЪБКђвЊБЃжЄЦкМфВЛЗЂЩњв§гУЙиЯЕЕФБфЛЏЃЌЫљгажДааЯпГЬвЊЭЃЖйЕШД§ЃЌГЬађжаЕФЯпГЬашвЊЭЃжЙРДХфКЯПЩДяадЗжЮі
ЫљвдЃЌУПДЮжБНгБщРњећИів§гУСДПЯЖЈЪЧВЛЯжЪЕЕФЁЃ ЮЊСЫгІЖдетжжоЯоЮЕФЮЪЬтЃЌзюдчгаБЃЪиЪНGCКЭКѓРДЕФзМШЗЪНGC
етРязМШЗЪНGCОЭЛсЬсЕНвЛИіOopMapЃЌгУРДБЃДцРраЭЕФгГЩфБэ
ЭЈЫзРДНВЃКOopMapОЭЪЧИцЫпЮвУЧGCЕФЪБКђПЩвдЛиЪеФФаЉЪ§Он
Safe PointЃК
гаСЫOopMapЃЌHotSpotПЩвдПьЫйзМШЗЭъГЩGC RootsУЖОй
ЕЋЪЧСэвЛИіЮЪЬтРДСЫЃЌЮвУЧвЊдкЪВУДЕиЗНДДНЈOopMap
ГЬађдЫааЦкМфЃЌв§гУЕФБфЛЏдкВЛЖЯЗЂЩњЃЌШчЙћУПвЛЬѕжИСюЖМЩљГЦOopMapЃЌФЧеМгУПеМфОЭЬЋДѓСЫЃЌЫљвдгаСЫАВШЋЕуЃЈSafe PointЃЉ
жЛдкАВШЋЕуНјааGCЭЃЖйЃЌжЛвЊБЃжЄв§гУБфЛЏЕФМЧТМЭъГЩгкGCЭЃЖйжЎЧАОЭПЩвд
АВШЋЕубЁЖЈЬЋЩйЃЌGCЕШД§ЪБМфОЭЬЋГЄЃЌбЁЕФЬЋЖрЃЌGCОЭЙ§гкЦЕЗБЁЃ
бЁЖЈддђЪЧ”ОпгаШУГЬађГЄЪБМфжДааЕФЬиеї“ЃЌвВОЭЪЧдкетИіЪБПЬЯжгаЕФжИСюЪЧПЩвдИДгУЕФЁЃ
вЛАубЁдкЗНЗЈЕїгУЁЂбЛЗЬјзЊЁЂХзГівьГЃЕФЮЛжУЁЃ
ЭЈЫзРДНВЃКSafePointОЭЪЧИцЫпЮвУЧдкФФвЛИіЕуНјааGC
STWЃКstop the worldЕФЫѕаДЃЌжИе§ГЃжДааЕФгУЛЇЯпГЬШЋВПЭЃжЙ
ЯждкЕФЮЪЬтЪЧдкSafe PointШУЯпГЬУЧвддѕбљЕФЛњжЦжаЖЯЃПЗНАИгаСНжжЃКЧРЯШЪНжаЖЯЁЂжїЖЏЪНжаЖЯЁЃ
ЧРЯШЪНжаЖЯЃК
GCЗЂЩњЪБЃЌжаЖЯЫљгаЯпГЬЃЌШчЙћЗЂЯжгаЯпГЬВЛдйАВШЋЕуЩЯЃЌОЭЛжИДЯпГЬШУЫќдЫааЕНАВШЋЕуЩЯЁЃЯждкМИКѕВЛгУетжжЗНАИЁЃ
ШБЕуЃКThread.sleep()ЃЛwait()ЧщПіЮоЗЈХмЕНетИіАВШЋЕуЕФ
жїЖЏЪНжаЖЯЃК
ЩшжУвЛИіБъжОЃЌКЭАВШЋЕужиКЯЃЌдйМгЩЯДДНЈЖдЯѓЗжХфФкДцЕФЕиЗНЁЃИїИіЯпГЬжїЖЏТжбЏетИіБъжОЃЌЗЂЯжжаЖЯБъжОЮЊецОЭЙвЦ№здМК
HotSpotЪЙгУжїЖЏЪНжаЖЯ
БъМЧ-ЧхГ§ЫуЗЈЃК
ИУЫуЗЈБъМЧГіЫљгаашвЊЛиЪеЕФЖдЯѓЃЌдкБъМЧЭъГЩКѓЭГвЛЛиЪеЫљгаБЛБъМЧЕФЖдЯѓ
ШБЯнЃК
ЃЈ1ЃЉаЇТЪВЛИп
ЃЈ2ЃЉБъМЧЧхГ§КѓЛсВњЩњДѓСПВЛСЌајЕФФкДцЫщЦЌ
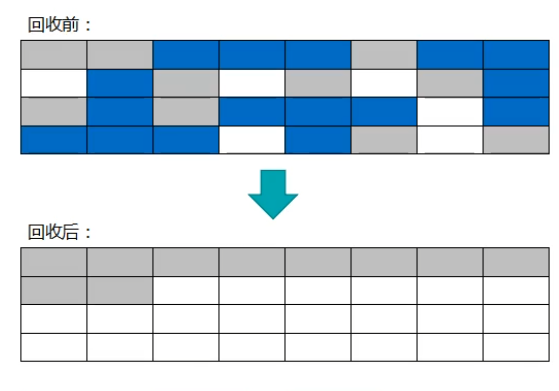
ИДжЦЫуЗЈЃК

НЋФкДцЗжЮЊДѓаЁЯрЕШЕФСНПщЃЌУПДЮжЛЪЙгУЦфжавЛПщЃЌФкДцгУЭъКѓЃЌОЭНЋЛЙЛюзХЕФЖдЯѓИДжЦЕНСэвЛПщЩЯЃЌШЛКѓАбвбЪЙгУЙ§ЕФФкДцПеМфвЛДЮЧхРэЕє
ШБЕуЃКФкДцЫѕаЁЮЊдРДЕФвЛАыЃЌРћгУТЪЙ§ЕЭ
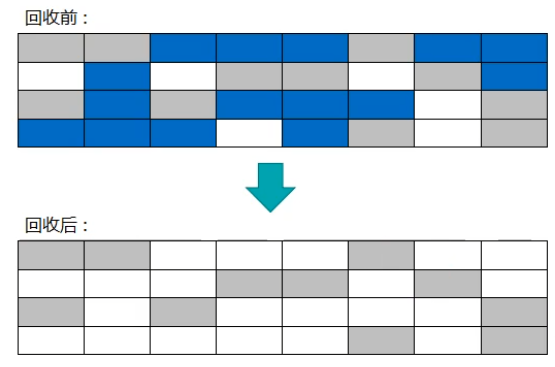
БъМЧећРэЫуЗЈЃК
БъМЧЙ§ГЬКЭБъМЧЧхГ§ЫуЗЈвЛбљЃЌЕЋЪЧВЛжБНгЖдПЩЛиЪеЖдЯѓНјааЧхРэЃЌШУЫљгаДцЛюЕФЖдЯѓЖМЯђвЛЖЫвЦЖЏЃЌШЛКѓжБНгЧхРэЕєЖЫБпНчвдЭтЕФФкДц
ЗжДњЫуЗЈЃК
вЛАуАбJavaЖбЗжЮЊаТЩњДњКЭРЯФъДњЃЌетбљОЭПЩвдИљОнИїИіФъДњЕФЬиЕуВЩгУзюЪЪКЯЕФЪеМЏЫуЗЈЃЌаТЩњДњжаУПДЮЪеМЏЖМЛсЗЂЩњДѓХњЖдЯѓЫРЭіЃЌФЧУДбЁгУИДжЦЫуЗЈ
жЛашвЊИЖГіЩйСПДцЛюЖдЯѓЕФИДжЦГЩБООЭПЩвдЭъГЩЛиЪеЃЛРЯФъДњжаЖдЯѓДцЛюТЪИпЃЌУЛгаЖюЭтПеМфЖдЫќНјааЗжХфЕЃБЃЃЌгкЪЧБиаыЪЙгУБъМЧЧхРэЫуЗЈ
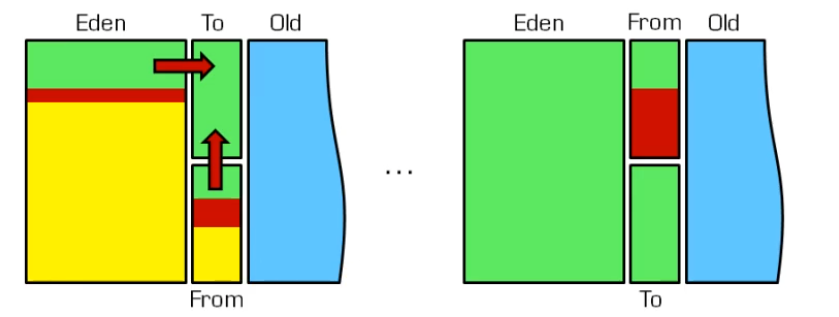
JavaФкДцЪОвтЭМ
ИќЯШНјЕФЫуЗЈЃЌгЩгкдкЪЕМЪЯюФПжаЃЌЖдЯѓДѓЖМЪЧвЛГіЩњОЭЫРЭіЃЌУПДЮРЌЛјЛиЪеЖдЯѓЫРЭівЛДѓХњЃЌОЙ§ЖрДЮЛиЪезюжеДцЛюЕФЗХШыИќИпМЖЕФЗжДњжа
ЩњЖЏаЮЯѓЕФБШгїЃКРрЫЦЪПБјДђеЬЃЌУПДЮавДцОќЯЮЖМЛсЩ§МЖЃЌзюжеДцЛюЯТРДЕФЖМЪЧНЋОќ
ЗжХфВпТдЃК
ЃЈ1ЃЉДѓЖдЯѓжБНгНјШыРЯФъДњЃЌЕфаЭЕФДѓЖдЯѓЪЧГЄзжЗћДЎКЭДѓЪ§зщ
ЪЙгУВЮЪ§-XX:PretenureSizeThresholdПЩвдСюДѓгкФГИіжЕЕФЖдЯѓжБНгБЃДцдкРЯФъДњЗжХфЃЌБмУтдквСЕщЧјКЭСНИіавДцЧјжЎМфЗЂЩњДѓСПЕФФкДцИДжЦ
ЃЈ2ЃЉГЄЦкДцЛюЕФЖдЯѓНјШыРЯФъДњЃЌЖдЯѓдкавДцДњАОЙ§вЛИіРЌЛјЛиЪеЃЈMinorGCЃЉФъСфОЭЛсдіМгвЛЫъЃЌФЌШЯЪЎЮхЫъНњЩ§ЕНРЯФъДњ
ЃЈ3ЃЉШчЙћавДцДњжаЯрЭЌФъСфЫљгаЖдЯѓДѓаЁзмКЭДѓгкавДцДњПеМфЕФвЛАыЃЌФъСфДѓгкЕШгкИУФъСфЕФЖдЯѓОЭПЩвджБНгНјШыРЯФъДњЃЌЮоашЪЎЮхЫъ
ЃЈ4ЃЉМьВщРЯФъДњзюДѓПЩгУЕФСЌајПеМфЪЧЗёДѓгкРњДЮНњЩ§ЕНРЯФъДњЖдЯѓЕФЦНОљДѓаЁЃЌШчЙћДѓгкЃЌГЂЪдвЛДЮMinorGCЃЌШчЙћаЁгкЃЌВЛдЪаэУАЯеЃЌетЪБашвЊНјаавЛДЮFullGC
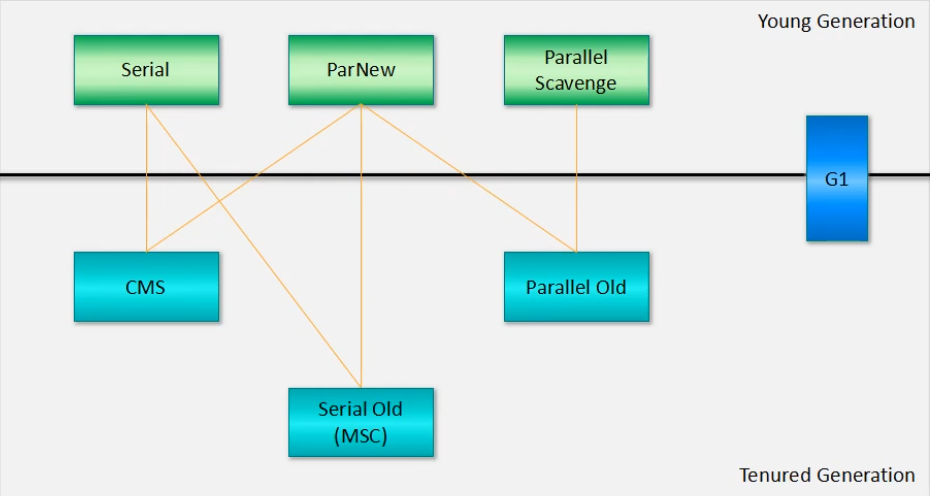
РЌЛјЛиЪеЦїЃК
ЃЈ1ЃЉSerialЪеМЏЦїЃЈ-XX:+UseSerialGCЃЉ
ЕЅЯпГЬЕФЪеМЏЦїЃЌВЛНіЪЧЪЙгУвЛИіЯпГЬЭъГЩРЌЛјЪеМЏЃЌЖјЧвдкЫќНјааРЌЛјЛиЪеЪБЃЌБиаыднЭЃЦфЫћЫљгаЕФЙЄзїЯпГЬЃЈSTWЃЉЃЌжБЕНЫќЪеМЏНсЪј
аТЩњДњВЩгУИДжЦЫуЗЈЃЌРЯФъДњВЩгУБъМЧећРэЫуЗЈ
ЪЪгУГЁОАЃКзРУцгІгУЃЈEclipseЃЌBurpsuiteЃЉ
ЃЈ2ЃЉSerialOldЪеМЏЦї
SerialЕФРЯФъДњАцБО
ЃЈ3ЃЉParNewЪеМЏЦїЃЈ-XX:+UserParNewGCЃЉ
SerialЪеМЏЦїЕФЖрЯпГЬАцБОЃЌГ§СЫЪЙгУЖрЯпГЬНјааРЌЛјЪеМЏЭтЃЌгыSerialЮоЧјБ№ЃЌаТЩњДњВЩгУЖрЯпГЬЃЌРЯФъДњЛЙЪЧЕЅЯпГЬ
аТЩњДњВЩгУИДжЦЫуЗЈЃЌРЯФъДњВЩгУБъМЧећРэЫуЗЈ
ЪЪгУГЁОАЃКЗўЮёЦїЖЫЪзбЁЕФаТЩњДњЪеМЏЦї
ЃЈ4ЃЉParallel ScavengeЪеМЏЦїЃЈ-XX:+UseParallelGCЃЉ
аТЩњДњЪеМЏЦїЃЌПЩПиЕФЭЬЭТСП
ЭЬЭТСПЃКдЫаагУЛЇДњТыЪЕМЪ/ЃЈдЫаагУЛЇДњТыЪЕМЪ+РЌЛјЪеМЏЪБМфЃЉ
ЭЃЖйЪБМфдНЖЬОЭдНЪЪКЯашвЊгыгУЛЇНЛЛЅЕФГЬађЃЌСМКУЕФЯьгІЫйЖШФмЬсЩ§гУЛЇЬхбщЃЌИпЭЬЭТСППЩвдИпаЇТЪЕиРћгУCPUЪБМфЃЌОЁПьЭъГЩГЬађЕФдЫЫуШЮЮё

гыParNewЪеМЏЦїЕФЧјБ№ЪЧЃКгУЛЇПЩвдПижЦGCЪБгУЛЇЯпГЬЕФЭЃЖйЪБМф
ЪЪгУГЁОАЃККѓЬЈМЦЫуЃЌВЛашвЊЬЋЖрНЛЛЅ
ЃЈ5ЃЉParallel OldЪеМЏЦїЃЈ-XX:+UseParallelOldGCЃЉ
ЪЧParalle ScavengeЪеМЏЦїЕФРЯФъДњАцБОЃЌЪЪгУЖрЯпГЬКЭБъМЧећРэЫуЗЈ
аТЩњДњКЭРЯФъДњЖМЪЧЖрЯпГЬ
ЃЈ6ЃЉCMSЃЈConcurrent Mark SweepЃЉЪеМЏЦїЃЈ-XX:+UseConcMarkSweepGCЃЉ
CMSЪеМЏЦїЗЧГЃИДдгЃЌЪЧвЛжжвдЛёШЁзюЖЬЛиЪеЭЃЖйЪБМфЮЊФПБъЕФЪеМЏЦїЃЌCMSЪЧЛљгкБъМЧЧхГ§ЫуЗЈЪЕЯжЕФЃЌБъМЧАќРЈвдЯТВПЗжЃК
ГѕЪМБъМЧЃКашвЊSTWЃЌЖдИљЖдЯѓзівЛИіБъМЧ
ВЂЗЂБъМЧЃКДгИљЖдЯѓПЊЪМж№ВНБъМЧ
жиаТБъМЧЃКашвЊSTWЃЌЧАСНВНУЛгаевЕНЕФЖдЯѓжиаТБъМЧЃЌБШШчЃЈString s=null;s="HelloWorld!"ЃЉ
ГЃгУВЮЪ§ЃК
-XX:CMSInitiatingOccupancyFraction гУРДЩшжУCMSПеМфВЮЪ§
-XX:+UseCMSCompactAtFullCollection GCжДааЭъКѓзівЛДЮећРэВйзї
-XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnlyетСНИіВйзївЛАудквЛЦ№ХфКЯЃКНЕЕЭCMS GCЦЕТЪЛђепдіМгЦЕТЪЁЂМѕЩйGCЪБГЄ
CMSЛиЪеЕФЯпГЬФЌШЯЪ§ЃКЃЈCPUЪ§СП+3ЃЉ/4
зЂвтЃКCMSЪеМЏЦїжЛФмдкРЯФъДњгУ
ЪЪгУГЁОАЃКWEBЯюФП
ЃЈ7ЃЉG1ЪеМЏЦї
G1ЪеМЏЦїгыжЎЧАЕФЭъШЋВЛЭЌЃЌЫуЗЈЗНУцРДЫЕЃЌМШЪєгкБъМЧећРэЃЌвВЪєгкИДжЦЫуЗЈ

YOUNG GCЃК
ЃЈ1ЃЉЩЈУшИљGC Roots
ЃЈ2ЃЉRememberSetМЧТМЛиЪеЖдЯѓЕФЪ§ОнНсЙЙ
ЃЈ3ЃЉМьВтRememberSetжаФЧаЉЪ§ОнашвЊДгФъЧсДњЕНРЯФъДњ
ЃЈ4ЃЉПНБДЖдЯѓЃЌПНБДЕНавДцДњЛђепРЯФъДњ
ЃЈ5ЃЉЧхРэЙЄзї
MIXED GCЃК
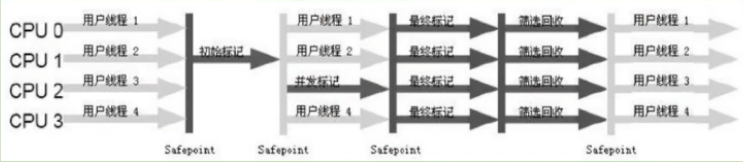
гыCMSРрЫЦЃЌетРяВЛдйЯИаДСЫ
G1ЪЪгУГЁОАЃКЗўЮёЦїЖЫГЬађ
ВЛЭЌЪеМЏЦїХфКЯЪЙгУЃК
КсЯпвдЩЯЕФЪЧаТЩњДњЃЌКсЯпвдЯТЕФЪЧРЯФъДњЃЌЦфжаG1ВЛФмгыЦфЫћЪеМЏЦїХфКЯ

зюКѓ
JDK1.8ФЌШЯРЌЛјЛиЪеЦїЃКParallel ScavengeЃЈаТЩњДњЃЉ+Parallel OldЃЈРЯФъДњЃЉ
JDK1.9ФЌШЯРЌЛјЛиЪеЦїЃКG1
дЮФСДНг:https://www.cnblogs.com/xuyiqing/p/12483294.html
ШчгавЩЮЪЧыгыдзїепСЊЯЕ
БъЧЉЃК
АцШЈЩъУїЃКБОеОЮФеТВПЗжздЭјТчЃЌШчгаЧжШЈЃЌЧыСЊЯЕЃКwest999com@outlook.com
ЬиБ№зЂвтЃКБОеОЫљгазЊдиЮФеТбдТлВЛДњБэБОеОЙлЕуЃЌБОеОЫљЬсЙЉЕФЩугАееЦЌЃЌВхЛЃЌЩшМЦзїЦЗЃЌШчашЪЙгУЃЌЧыгыдзїепСЊЯЕЃЌАцШЈЙщдзїепЫљга

ЩЯвЛЦЊЃКIDEAЧПКЗСЫЕїЪдЦїОЙШЛжЇГжЪЕЪБЪ§ОнСїЗжЮіРВЬсЧАжЊЕРДњТыдѕУДХмЃП
ЯТвЛЦЊЃКJavaСЌди96-FileInputStreamЗНЗЈНтЮіЁЂбЛЗЪфГіШЋВПФкШн
- бЇЯАJava 8 Stream Api (4) - Stream жеЖЫВйзїжЎ collect 2020-06-11
- javaбЇЯАжЎЕквЛЬь 2020-06-11
- JVMГЃМћУцЪдЬтНтЮі 2020-06-11
- JavaбЇЯАжЎЕкЖўЬь 2020-06-11
- Spring WebFlux бЇЯАБЪМЧ - (вЛ) ЧАДЋ:бЇЯАJava 8 Stream Ap 2020-06-11
IDCзЪбЖЃК жїЛњзЪбЖ зЂВсзЪбЖ ЭаЙмзЪбЖ vpsзЪбЖ ЭјеОНЈЩш
ЭјеОдЫгЊЃК НЈеООбщ ВпЛЎгЏРћ ЫбЫїгХЛЏ ЭјеОЭЦЙу УтЗбзЪдД
ЭјеОСЊУЫЃК СЊУЫаТЮХ СЊУЫНщЩм СЊУЫЕуЦР ЭјзЌММЧЩ
аавЕзЪбЖЃК ЫбЫїв§Чц ЭјТчгЮЯЗ ЕчзгЩЬЮё ЙуИцДЋУН
ЭјТчБрГЬЃК Asp.NetБрГЬ AspБрГЬ PhpБрГЬ XmlБрГЬ Access Mssql Mysql ЦфЫќ
ЗўЮёЦїММЪѕЃК WebЗўЮёЦї FtpЗўЮёЦї MailЗўЮёЦї DnsЗўЮёЦї АВШЋЗРЛЄ
ШэМўММЧЩЃК ЦфЫќШэМў Word Excel Powerpoint Ghost Vista QQПеМф QQ FlashGet бИРз
ЭјвГжЦзїЃК FrontPages Dreamweaver Javascript css photoshop fireworks Flash
ГЬађЩшМЦЃК JavaММЪѕ C/C++ VB delphi

- PhotoshopЛцжЦСЂЬхЗчИёЕФЮЂаІБэЧщ
- PSЮФзжЬиаЇНЬГЬЃКжЦзїЙЋТЗЩЯИіадЕФЭПбЛ
- PhotoshopЩшМЦОэБпаЇЙћЕФБфаЮН№ИеЕчгА
- PSЩЋВЪаоИДНЬГЬЃКРћгУЩЋНзЙЄОпПьЫйИјКь
- PSАыЭИУїЮяЬхПйЭМЃКРћгУЭЈЕРбЁЧјЙЄОпПй
- PSКЃБЈЩшМЦММЧЩНЬГЬЃКбЇЯАжЦзїИіадЕФХЄ
- PSЭМЦЌЬиаЇжЦзїНЬГЬЃКбЇЯАИјЬњЫўЭМЦЌжЦ
- бЇЯАгУphotoshopАбЛызЧЕФКЃЫЎееЦЌКѓЦк
- PSЙХЗчееЦЌНЬГЬЃКИјЙХЗчУРХЎДђдьГіХЎЯР
- PSИіадШЫЮяКЃБЈжЦзїЃКЩшМЦДДвтЪБЩаЕФВЃ
- ЪВУДШэМўПЩвдЕСШЁЮЂаХКХУмТы,дѕУДЕСБ№
- ДХСІЫбЫїЭјеОЕМКН2020ФъИќаТ
- springcloudбЇЯАжЎТЗ: (вЛ) зюМђЕЅЕФДю
- ДДНЈGradleЙЄГЬГіЯжCould not install
- ГЙЕзХЊЖЎЁАPKIX path building failed
- TomcatЦєЖЏБЈДэ:org.apache.catalina.L
- spring boot ДэЮѓЃКCheck your ViewRes
- ЛљгкHttpClientЕФаТАце§ЗННЬЮёЯЕЭГФЃФт
- жЛгаГЬађдБВХФмПДЖЎЕФГЕХЦЃЌЖЎЕУздШЛЖЎ
- mybatis зЂНт@ResultsЁЂ@ResultЁЂ@Resu