
[Flink] Flink的waterMark的通俗理解
2020-03-31 16:08:16来源:博客园 阅读 ()

[Flink] Flink的waterMark的通俗理解
导读
Flink 为实时计算提供了三种时间,即事件时间(event time)、摄入时间(ingestion time)和处理时间(processing time)。
遇到的问题:
假设在一个5秒的Tumble窗口,有一个EventTime是 11秒的数据,在第16秒时候到来了。图示第11秒的数据,在16秒到来了,如下图:该如何处理迟到数据
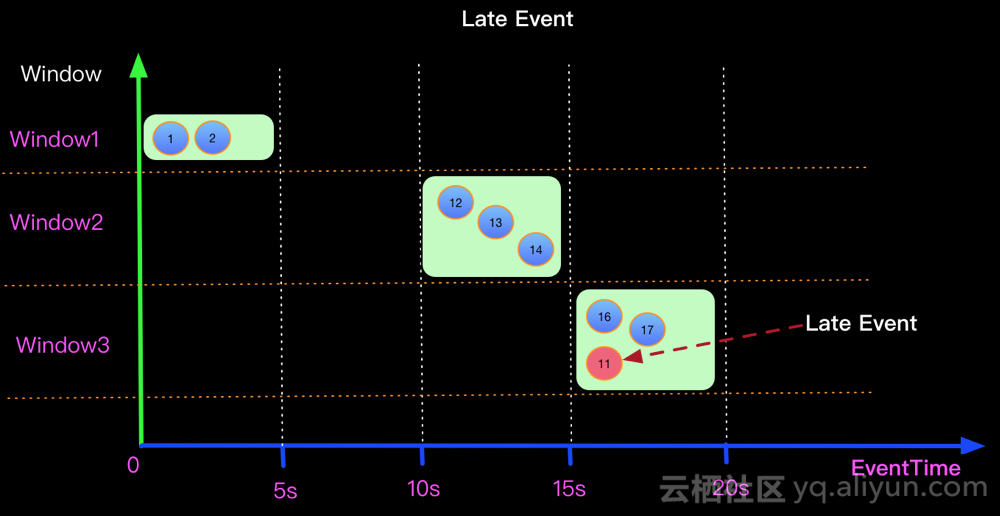
什么是Watermark
Watermark的关键点:
- 目的:处理EventTime 窗口计算
- 本质:时间戳
- 生成方式:Punctuated和Periodic(常用)
- 特性:单调递增
Watermark的产生方式
-
Punctuated
数据流中每一个递增的EventTime都会产生一个Watermark。
-
Periodic(推荐)
周期性的(一定时间间隔或者达到一定的记录条数)产生一个Watermark。
Watermark解决的问题
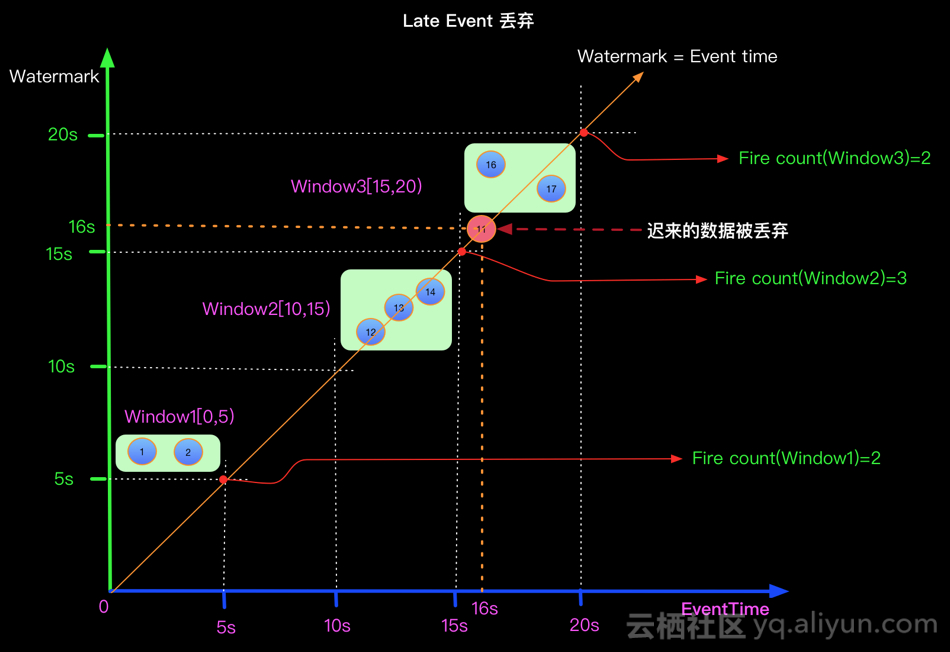
上面的问题在于如何将迟来的EventTime 位11的元素正确处理?
当Watermark的时间戳等于Event中携带的EventTime时候,上面场景(Watermark=EventTime)的计算结果如下:
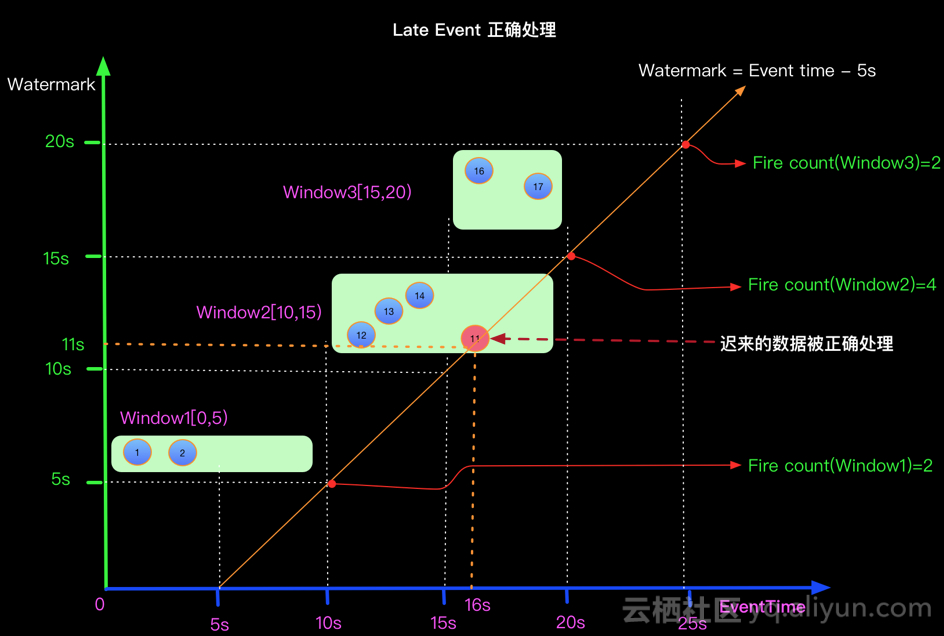
如果想正确处理迟来的数据可以定义Watermark生成策略为 Watermark = EventTime -5s, 如下:
WaterMark的例子
设置WaterMark步骤:
1.设置StreamTime Characteristic为Event Time,即设置流式时间窗口(也可以称为流式时间特性)
2.创建的DataStreamSource调用assignTimestampsAndWatermarks方法,并设置WaterMark种类:AssignerWithPeriodicWatermarks / AssignerWithPunctuatedWatermarks
或者 实现AssignerWithPeriodicWatermarks接口 / 实现AssignerWithPunctuatedWatermarks接口
3.重写getCurrentWatermark与extractTimestamp方法
getCurrentWatermark方法:获取当前的水位线
extractTimestamp方法:提取数据流中的时间戳(必须显式的指定数据中的Event Time)
实例
通过一段程序,实践一下WaterMark的设定以及WaterMark的工作方式
数据示例:
key + 时间戳
hello,1553503210000
程序说明:
1.使用Socket模拟接收数据
2.设置WaterMark
设置的逻辑:在第一条数据进来时,设置WaterMark为0,指定第一条数据的时间戳后,获取该时间戳与当前 WaterMark的最大值,并将最大值设置为下一条数据的WaterMark,以此类推
3.进行map基础转换,将String转换为Tuple2<String,String>
4.根据Key分组
5.使用滚动Event Time窗口,将5秒内的同组数据,进行Fold拼接输出
代码如下:
package waterMark;
import org.apache.flink.api.common.functions.FoldFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import javax.annotation.Nullable;
/**
* waterMark实例
*
* @author lixiyan
* @date 2019/10/22 4:45 PM
*/
public class MainWaterMark001 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
SingleOutputStreamOperator<String> dataStream = env.socketTextStream("localhost", 12345)
.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<String>() {
// 当前时间戳
long currentTimeStamp = 0L;
// 允许的迟到数据
long maxDelayAllowed = 0L;
// 当前水位线
long currentWaterMark;
@Nullable
@Override
public Watermark getCurrentWatermark() {
currentWaterMark = currentTimeStamp - maxDelayAllowed;
System.out.println("当前水位线:" + currentWaterMark);
return new Watermark(currentWaterMark);
}
@Override
public long extractTimestamp(String s, long l) {
String[] arr = s.split(",");
long timeStamp = Long.parseLong(arr[1]);
currentTimeStamp = Math.max(timeStamp, currentTimeStamp);
System.out.println("Key:" + arr[0] + ",EventTime:" + timeStamp + ",水位线:" + currentWaterMark);
return timeStamp;
}
});
dataStream.map(new MapFunction<String, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> map(String s) throws Exception {
return new Tuple2<String, String>(s.split(",")[0], s.split(",")[1]);
}
}).keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5)))
.fold("Start:", new FoldFunction<Tuple2<String, String>, String>() {
@Override
public String fold(String s, Tuple2<String, String> o) throws Exception {
return s + " - " + o.f1;
}
}).print();
env.execute("MainWaterMark001");
}
}
开启9999端口,并输入第一条数据:
hello,1553503185000
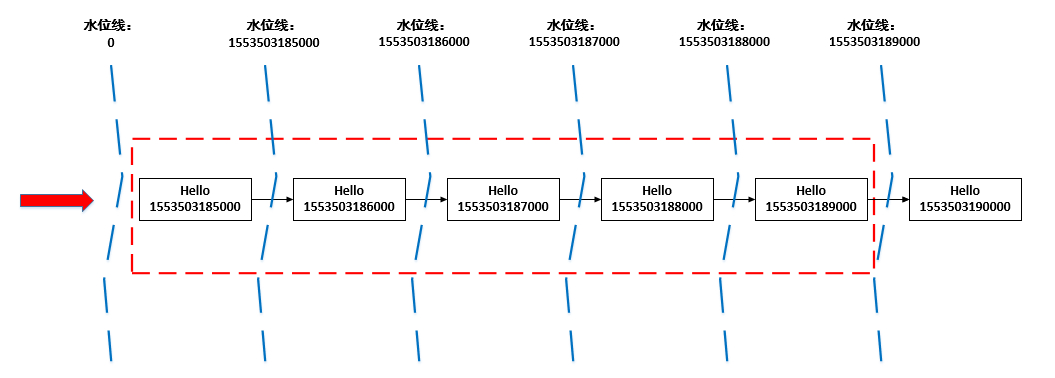
那么,我先假设后续的数据Event Time间隔为1秒,推断一下WaterMark的设定,如下图所示
1.第一条数据的Event Time为1553503185000,那么当前窗口时间为:1553503185000 -> 1553503189000,即下图中红色框线
2.第一条数据进来时,这条数据之前的WaterMark为0,当第一条数据已经进入后,指定Event Time位置,并与现在的WaterMark比较,将两者中大的那个值设置为新的WaterMark,那么当前数据的WaterMark为1553503185000
3.第二条数据进来时,前一条数据的WaterMark为1553503185000,第二条数据的Event Time比之前的WaterMark大,于是更新WaterMark,将当前的WaterMark更新为1553503186000,但还没到窗口触发时间,不进行计算
4.后面几个以此类推,直到Event Time为:1553503190000的数据进来的时候,前一条数据的WaterMark为1553503189000,于是更新当前的WaterMark为155350390000,Flink认为1553503190000之前的数据都已经到达,且达到了窗口的触发条件,开始进行计算
根据上面的推断,启动程序验证一下
先启动监听9999端口,再启动Flink程序,并向端口监听终端输入以下内容:
hello,1553503185000
hello,1553503186000
hello,1553503187000
hello,1553503188000
hello,1553503189000
hello,1553503190000
Flink输出结果:
Key:hello,EventTime:1553503185000,水位线:0
Key:hello,EventTime:1553503186000,水位线:1553503185000
Key:hello,EventTime:1553503187000,水位线:1553503186000
Key:hello,EventTime:1553503188000,水位线:1553503187000
Key:hello,EventTime:1553503189000,水位线:1553503188000
Key:hello,EventTime:1553503190000,水位线:1553503189000
2> Start: - 1553503185000 - 1553503186000 - 1553503187000 - 1553503188000 - 1553503189000
通过结果可以发现,Flink在指定WaterMark时,先调用extractTimestamp方法,再调用getCurrentWatermark方法, 所以打印信息中的WaterMark为上一条数据的WaterMark,并非当前的WaterMark
为了验证这个结论,修改一下代码:
@Nullable
@Override
public Watermark getCurrentWatermark() {
currentWaterMark = currentTimeStamp - maxDelayAllowed;
System.out.println("当前水位线:" + currentWaterMark);
return new Watermark(currentWaterMark);
}
@Override
public long extractTimestamp(String s, long l) {
String[] arr = s.split(",");
long timeStamp = Long.parseLong(arr[1]);
currentTimeStamp = Math.max(timeStamp, currentTimeStamp);
System.out.println("Key:" + arr[0] + ",EventTime:" + timeStamp + ",前一条数据的水位线:" + currentWaterMark);
return timeStamp;
}
在监听终端输入同一批数据:
hello,1553503185000
hello,1553503186000
hello,1553503187000
hello,1553503188000
hello,1553503189000
hello,1553503190000
Flink输出结果:
Key:hello,EventTime:1553503185000,前一条数据的水位线:0
当前水位线:1553503185000
Key:hello,EventTime:1553503186000,前一条数据的水位线:1553503185000
当前水位线:1553503186000
Key:hello,EventTime:1553503187000,前一条数据的水位线:1553503186000
当前水位线:1553503187000
Key:hello,EventTime:1553503188000,前一条数据的水位线:1553503187000
当前水位线:1553503188000
Key:hello,EventTime:1553503189000,前一条数据的水位线:1553503188000
当前水位线:1553503189000
Key:hello,EventTime:1553503190000,前一条数据的水位线:1553503189000
当前水位线:1553503190000
2> Start: - 1553503185000 - 1553503186000 - 1553503187000 - 1553503188000 - 1553503189000
通过上面的结果,验证了之前的结论,在设置WaterMark方法中,先调用extractTimestamp方法,再调用getCurrentWatermark方法
数据乱序
上面的实例,Event Time是有序,现在来做一下数据乱序的场景模拟
启动程序,在监听终端中输入如下数据:
其中,在触发了了第一个窗口计算后,又来了两条迟到数据hello,1553503187000,hello,1553503186000
hello,1553503185000
hello,1553503186000
hello,1553503187000
hello,1553503188000
hello,1553503189000
hello,1553503190000
hello,1553503187000
hello,1553503186000
hello,1553503191000
hello,1553503192000
hello,1553503193000
hello,1553503194000
hello,1553503195000
Flink结果:
Key:hello,EventTime:1553503185000,前一条数据的水位线:0
当前水位线:1553503185000
Key:hello,EventTime:1553503186000,前一条数据的水位线:1553503185000
当前水位线:1553503186000
Key:hello,EventTime:1553503187000,前一条数据的水位线:1553503186000
当前水位线:1553503187000
Key:hello,EventTime:1553503188000,前一条数据的水位线:1553503187000
当前水位线:1553503188000
Key:hello,EventTime:1553503189000,前一条数据的水位线:1553503188000
当前水位线:1553503189000
Key:hello,EventTime:1553503190000,前一条数据的水位线:1553503189000
当前水位线:1553503190000
2> Start: - 1553503185000 - 1553503186000 - 1553503187000 - 1553503188000 - 1553503189000
当前水位线:1553503190000
Key:hello,EventTime:1553503187000,前一条数据的水位线:1553503190000
当前水位线:1553503190000
Key:hello,EventTime:1553503186000,前一条数据的水位线:1553503190000
当前水位线:1553503190000
Key:hello,EventTime:1553503191000,前一条数据的水位线:1553503190000
当前水位线:1553503191000
Key:hello,EventTime:1553503192000,前一条数据的水位线:1553503191000
当前水位线:1553503192000
Key:hello,EventTime:1553503193000,前一条数据的水位线:1553503192000
当前水位线:1553503193000
Key:hello,EventTime:1553503194000,前一条数据的水位线:1553503193000
当前水位线:1553503194000
Key:hello,EventTime:1553503195000,前一条数据的水位线:1553503194000
当前水位线:1553503195000
2> Start: - 1553503190000 - 1553503191000 - 1553503192000 - 1553503193000 - 1553503194000
从结果中可以看到,在第二个窗口中,那两条迟到数据并没有进行处理,这个就是迟到丢弃。
乱序时间的设置:
为了解决上面的问题,我们允许Flink处理延迟以5秒内的迟到数据
修改最大乱序时间
long maxDelayAllowed = 5000l;
在监听终端中,输入数据
hello,1553503185000
hello,1553503186000
hello,1553503187000
hello,1553503188000
hello,1553503189000
hello,1553503190000
hello,1553503187000
hello,1553503186000
hello,1553503191000
hello,1553503192000
hello,1553503193000
hello,1553503194000
hello,1553503195000
Flink输出结果:
Key:hello,EventTime:1553503185000,前一条数据的水位线:-5000
当前水位线:1553503180000
Key:hello,EventTime:1553503186000,前一条数据的水位线:1553503180000
当前水位线:1553503181000
Key:hello,EventTime:1553503187000,前一条数据的水位线:1553503181000
当前水位线:1553503182000
Key:hello,EventTime:1553503188000,前一条数据的水位线:1553503182000
当前水位线:1553503183000
Key:hello,EventTime:1553503189000,前一条数据的水位线:1553503183000
当前水位线:1553503184000
Key:hello,EventTime:1553503190000,前一条数据的水位线:1553503184000
当前水位线:1553503185000
Key:hello,EventTime:1553503187000,前一条数据的水位线:1553503185000
当前水位线:1553503185000
Key:hello,EventTime:1553503186000,前一条数据的水位线:1553503185000
当前水位线:1553503185000
Key:hello,EventTime:1553503191000,前一条数据的水位线:1553503185000
当前水位线:1553503186000
Key:hello,EventTime:1553503192000,前一条数据的水位线:1553503186000
当前水位线:1553503187000
Key:hello,EventTime:1553503193000,前一条数据的水位线:1553503187000
当前水位线:1553503188000
Key:hello,EventTime:1553503194000,前一条数据的水位线:1553503188000
当前水位线:1553503189000
Key:hello,EventTime:1553503195000,前一条数据的水位线:1553503189000
当前水位线:1553503190000
2> Start: - 1553503185000 - 1553503186000 - 1553503187000 - 1553503188000 - 1553503189000 - 1553503187000 - 1553503186000
可以看到,设置了最大允许乱序时间后,WaterMark要比原来低5秒,可以对延迟5秒内的数据进行处理,窗口的触发条件也同样会往后延迟
关于延迟时间,请结合业务场景进行设置
至此,WaterMark实例就写完了
总结
一开始,你先不要把Windowing、WaterMark、Trigger三者混在一起去考虑最终输出的结果是什么,建议独立考虑清楚这三者都做了什么,以及三者之间的依赖关系是什么:
1、Windowing:就是负责该如何生成Window,比如Fixed Window、Slide Window,当你配置好生成Window的策略时,Window就会根据时间动态生成,最终得到一个一个的Window,包含一个时间范围:[起始时间, 结束时间),它们是一个一个受限于该时间范围的事件记录的容器,每个Window会收集一堆记录,满足指定条件会触发Window内事件记录集合的计算处理。
2、WaterMark:它其实不太好理解,可以将它定义为一个函数E=f(P),当前处理系统的处理时间P,根据一定的策略f会映射到一个事件时间E,可见E在坐标系中的表现形式是一条曲线,根据f的不同曲线形状也不同。假设,处理时间12:00:00,我希望映射到事件时间11:59:30,这时对于延迟30秒以内(事件时范围11:59:30~12:00:00)的事件记录到达处理系统,都指派到时间范围包含处理时间12:00:00这个Window中。事件时间超过12:00:00的就会由Trigger去做补偿了。
3、Trigger:为了满足实际不同的业务需求,对上述事件记录指派给Window未能达到实际效果,而做出的一种补偿,比如事件记录在WaterMark时间戳之后到达事件处理系统,因为已经在对应的Window时间范围之后,我有很多选择:选择丢弃,选择是满足延迟3秒后还是指派给该Window,选择只接受对应的Window时间范围之后的5个事件记录,等等,这都是满足业务需要而制定的触发Window重新计算的策略,所以非常灵活。
本文由博客群发一文多发等运营工具平台 OpenWrite 发布
原文链接:https://www.cnblogs.com/lixiyan/p/12603532.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- Flink 如何分流数据 2020-06-11
- 通俗理解spring源码(六)―― 默认标签(import、alias、be 2020-06-07
- 可能是把 Java 接口讲得最通俗的一篇文章 2020-05-15
- 漫画:通俗易懂的理解进程与线程 2020-05-14
- 通俗理解spring源码(四)―― 获取Docment 2020-04-21
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
