
高级必问:Linux 中的零拷贝技术是什么?
2020-04-01 16:08:37来源:博客园 阅读 ()

高级必问:Linux 中的零拷贝技术是什么?
作者:卡巴拉的树
https://www.jianshu.com/p/fad3339e3448
正文
本文探讨Linux中 主要的几种零拷贝技术 以及零拷贝技术 适用的场景 。为了迅速建立起零拷贝的概念,我们拿一个常用的场景进行引入:
01 引文
在写一个服务端程序时(Web Server或者文件服务器),文件下载是一个基本功能。这时候服务端的任务是:将服务端主机磁盘中的文件不做修改地从已连接的socket发出去,我们通常用下面的代码完成:
while((n?=?read(diskfd,?buf,?BUF_SIZE))?>?0)????write(sockfd,?buf?,?n);
基本操作就是循环的从磁盘读入文件内容到缓冲区,再将缓冲区的内容发送到socket。但是由于Linux的I/O操作默认是缓冲I/O。这里面主要使用的也就是read和write两个系统调用,我们并不知道操作系统在其中做了什么。实际上在以上I/O操作中,发生了多次的数据拷贝。
当应用程序访问某块数据时,操作系统首先会检查,是不是最近访问过此文件,文件内容是否缓存在内核缓冲区,如果是,操作系统则直接根据read系统调用提供的buf地址,将内核缓冲区的内容拷贝到buf所指定的用户空间缓冲区中去。如果不是,操作系统则首先将磁盘上的数据拷贝的内核缓冲区,这一步目前主要依靠DMA来传输,然后再把内核缓冲区上的内容拷贝到用户缓冲区中。
接下来,write系统调用再把用户缓冲区的内容拷贝到网络堆栈相关的内核缓冲区中,最后socket再把内核缓冲区的内容发送到网卡上。说了这么多,不如看图清楚:
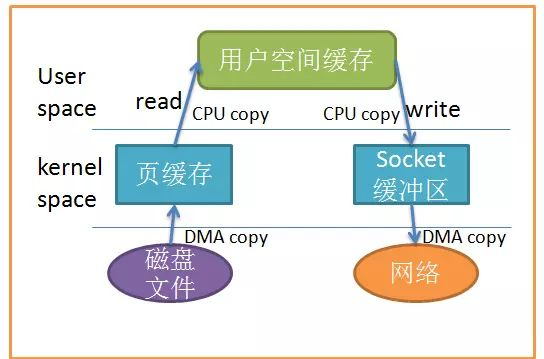
数据拷贝
从上图中可以看出,共产生了四次数据拷贝,即使使用了DMA来处理了与硬件的通讯,CPU仍然需要处理两次数据拷贝,与此同时,在用户态与内核态也发生了多次上下文切换,无疑也加重了CPU负担。
在此过程中,我们没有对文件内容做任何修改,那么在内核空间和用户空间来回拷贝数据无疑就是一种浪费,而零拷贝主要就是为了解决这种低效性。
2 什么是零拷贝技术(zero-copy)?
零拷贝主要的任务就是避免CPU将数据从一块存储拷贝到另外一块存储,主要就是利用各种零拷贝技术,避免让CPU做大量的数据拷贝任务,减少不必要的拷贝,或者让别的组件来做这一类简单的数据传输任务,让CPU解脱出来专注于别的任务。这样就可以让系统资源的利用更加有效。
我们继续回到引文中的例子,我们如何减少数据拷贝的次数呢?一个很明显的着力点就是减少数据在内核空间和用户空间来回拷贝,这也引入了零拷贝的一个类型:让数据传输不需要经过 user space。
3 使用 mmap
我们减少拷贝次数的一种方法是调用mmap()来代替read调用:
buf?=?mmap(diskfd,?len);write(sockfd,?buf,?len);
应用程序调用mmap(),磁盘上的数据会通过DMA被拷贝的内核缓冲区,接着操作系统会把这段内核缓冲区与应用程序共享,这样就不需要把内核缓冲区的内容往用户空间拷贝。应用程序再调用write(),操作系统直接将内核缓冲区的内容拷贝到socket缓冲区中,这一切都发生在内核态,最后,socket缓冲区再把数据发到网卡去。同样的,看图很简单:
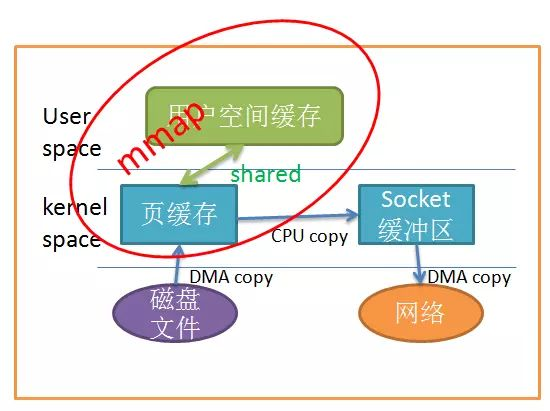
mmap
使用mmap替代read很明显减少了一次拷贝,当拷贝数据量很大时,无疑提升了效率。但是使用mmap是有代价的。当你使用mmap时,你可能会遇到一些隐藏的陷阱。例如,当你的程序map了一个文件,但是当这个文件被另一个进程截断(truncate)时, write系统调用会因为访问非法地址而被SIGBUS信号终止。SIGBUS信号默认会杀死你的进程并产生一个coredump,如果你的服务器这样被中止了,那会产生一笔损失。
通常我们使用以下解决方案避免这种问题:
1. 为SIGBUS信号建立信号处理程序
当遇到SIGBUS信号时,信号处理程序简单地返回,write系统调用在被中断之前会返回已经写入的字节数,并且errno会被设置成success,但是这是一种糟糕的处理办法,因为你并没有解决问题的实质核心。
2. 使用文件租借锁
通常我们使用这种方法,在文件描述符上使用租借锁,我们为文件向内核申请一个租借锁,当其它进程想要截断这个文件时,内核会向我们发送一个实时的RTSIGNALLEASE信号,告诉我们内核正在破坏你加持在文件上的读写锁。这样在程序访问非法内存并且被SIGBUS杀死之前,你的write系统调用会被中断。write会返回已经写入的字节数,并且置errno为success。
我们应该在mmap文件之前加锁,并且在操作完文件后解锁:
if(fcntl(diskfd,?F\_SETSIG,?RT\_SIGNAL\_LEASE)?==?-1)?{???perror("kernel?lease?set?signal");return?-1;}/*?l\_type?can?be?F\_RDLCK?F\_WRLCK??加锁*//*?l\_type?can?be??F\_UNLCK?解锁*/if(fcntl(diskfd,?F\_SETLEASE,?l\_type)){perror("kernel?lease?set?type");return?-1;}
4 使用sendfile
从2.1版内核开始,Linux引入了sendfile来简化操作:
#include<sys/sendfile.h>ssize\_t?sendfile(int?out\_fd,?int?in\_fd,?off\_t?*offset,?size_t?count);
系统调用sendfile()在代表输入文件的描述符infd和代表输出文件的描述符outfd之间传送文件内容(字节)。描述符outfd必须指向一个套接字,而infd指向的文件必须是可以mmap的。这些局限限制了sendfile的使用,使sendfile只能将数据从文件传递到套接字上,反之则不行。
使用sendfile不仅减少了数据拷贝的次数,还减少了上下文切换,数据传送始终只发生在kernel space。
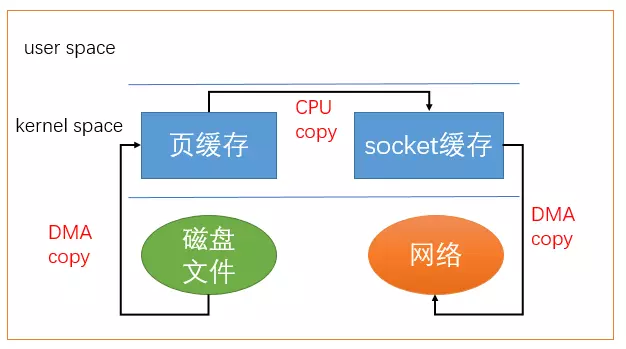
sendfile系统调用过程
在我们调用sendfile时,如果有其它进程截断了文件会发生什么呢?假设我们没有设置任何信号处理程序,sendfile调用仅仅返回它在被中断之前已经传输的字节数,errno会被置为success。如果我们在调用sendfile之前给文件加了锁,sendfile的行为仍然和之前相同,我们还会收到RTSIGNALLEASE的信号。
目前为止,我们已经减少了数据拷贝的次数了,但是仍然存在一次拷贝,就是页缓存到socket缓存的拷贝。那么能不能把这个拷贝也省略呢?
借助于硬件上的帮助,我们是可以办到的。之前我们是把页缓存的数据拷贝到socket缓存中,实际上,我们仅仅需要把缓冲区描述符传到socket缓冲区,再把数据长度传过去,这样DMA控制器直接将页缓存中的数据打包发送到网络中就可以了。
总结一下,sendfile系统调用利用DMA引擎将文件内容拷贝到内核缓冲区去,然后将带有文件位置和长度信息的缓冲区描述符添加socket缓冲区去,这一步不会将内核中的数据拷贝到socket缓冲区中,DMA引擎会将内核缓冲区的数据拷贝到协议引擎中去,避免了最后一次拷贝。

带DMA的sendfile
不过这一种收集拷贝功能是需要硬件以及驱动程序支持的。
5 使用splice
sendfile只适用于将数据从文件拷贝到套接字上,限定了它的使用范围。Linux在2.6.17版本引入splice系统调用,用于在两个文件描述符中移动数据:
#define?\_GNU\_SOURCE?????????/*?See?feature\_test\_macros(7)?*/#include<fcntl.h>ssize\_t?splice(int?fd\_in,?loff\_t?\*off\_in,?int?fd\_out,?loff\_t?\*off\_out,?size\_t?len,?unsignedint?flags);
splice调用在两个文件描述符之间移动数据,而不需要数据在内核空间和用户空间来回拷贝。他从fdin拷贝len长度的数据到fdout,但是有一方必须是管道设备,这也是目前splice的一些局限性。flags参数有以下几种取值:
-
SPLICEFMOVE?:尝试去移动数据而不是拷贝数据。这仅仅是对内核的一个小提示:如果内核不能从pipe移动数据或者pipe的缓存不是一个整页面,仍然需要拷贝数据。Linux最初的实现有些问题,所以从2.6.21开始这个选项不起作用,后面的Linux版本应该会实现。
-
SPLICEFNONBLOCK?:splice 操作不会被阻塞。然而,如果文件描述符没有被设置为不可被阻塞方式的 I/O ,那么调用 splice 有可能仍然被阻塞。
-
SPLICEFMORE:后面的splice调用会有更多的数据。
splice调用利用了Linux提出的管道缓冲区机制, 所以至少一个描述符要为管道。
以上几种零拷贝技术都是减少数据在用户空间和内核空间拷贝技术实现的,但是有些时候,数据必须在用户空间和内核空间之间拷贝。这时候,我们只能针对数据在用户空间和内核空间拷贝的时机上下功夫了。Linux通常利用写时复制(copy on write)来减少系统开销,这个技术又时常称作COW。
由于篇幅原因,本文不详细介绍写时复制。大概描述下就是:如果多个程序同时访问同一块数据,那么每个程序都拥有指向这块数据的指针,在每个程序看来,自己都是独立拥有这块数据的,只有当程序需要对数据内容进行修改时,才会把数据内容拷贝到程序自己的应用空间里去,这时候,数据才成为该程序的私有数据。如果程序不需要对数据进行修改,那么永远都不需要拷贝数据到自己的应用空间里。这样就减少了数据的拷贝。写时复制的内容可以再写一篇文章了。。。
除此之外,还有一些零拷贝技术,比如传统的Linux I/O中加上O_DIRECT标记可以直接I/O,避免了自动缓存,还有尚未成熟的fbufs技术,本文尚未覆盖所有零拷贝技术,只是介绍常见的一些,如有兴趣,可以自行研究,一般成熟的服务端项目也会自己改造内核中有关I/O的部分,提高自己的数据传输速率。
推荐去我的博客阅读更多:
1.Java JVM、集合、多线程、新特性系列教程
2.Spring MVC、Spring Boot、Spring Cloud 系列教程
3.Maven、Git、Eclipse、Intellij IDEA 系列工具教程
4.Java、后端、架构、阿里巴巴等大厂最新面试题
生活很美好,明天见~
原文链接:https://www.cnblogs.com/javastack/p/12610841.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

上一篇:java join()方法
下一篇:数据结构总结
- Linux简单命令的学习 2020-06-10
- Java高级实战Maven+JSP+SSM+Mysql实现的音乐网站,70%人不会 2020-06-04
- 那些面试官必问的JAVA多线程和并发面试题及回答 2020-05-28
- linux连个文件都删除不了,什么鬼! 2020-05-27
- SpringMVC高级-拦截器如何正确运用?案例详解 2020-05-21
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
