
Spring-Cloud-Netflix-Hystrix
2020-04-09 16:06:14来源:博客园 阅读 ()

Spring-Cloud-Netflix-Hystrix
目录
- 雪崩问题
- Hystrix概述
- 降级
- 什么是降级?
- 降级步骤
- 超时监听
- 熔断
- 概述:
- 熔断配置
- 限流
- feign整合hystrix
- 方式1-fallback
- 方式2-fallbackFactory
- feign整合hystrix
- 降级
雪崩问题
一个服务,依赖于另一个功能服务的,如果这个功能服务挂掉了,那么依赖的服务就不能再用了,这种级联的失败, 我们可以称之为雪崩
Hystrix概述
Hystrix github地址
- Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等
- Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
降级
什么是降级?
- 降级是当我们的某个微服务响应时间过长,或者不可用了也就是那个微服务调用不了了,
- 我们不能吧错误信息返回出来,或者让他一直卡在那里,所以要在准备一个对应的策略(一个方法)
- 当发生这种问题的时候我们直接调用这个方法来快速返回这个请求,不让他一直卡在那
- 当某个微服务调用不了了要做降级,也就是说,要在调用方做降级(不然那个微服务都down掉了再做降级也没什么意义了)
降级步骤
- 在服务调用方法添加依赖
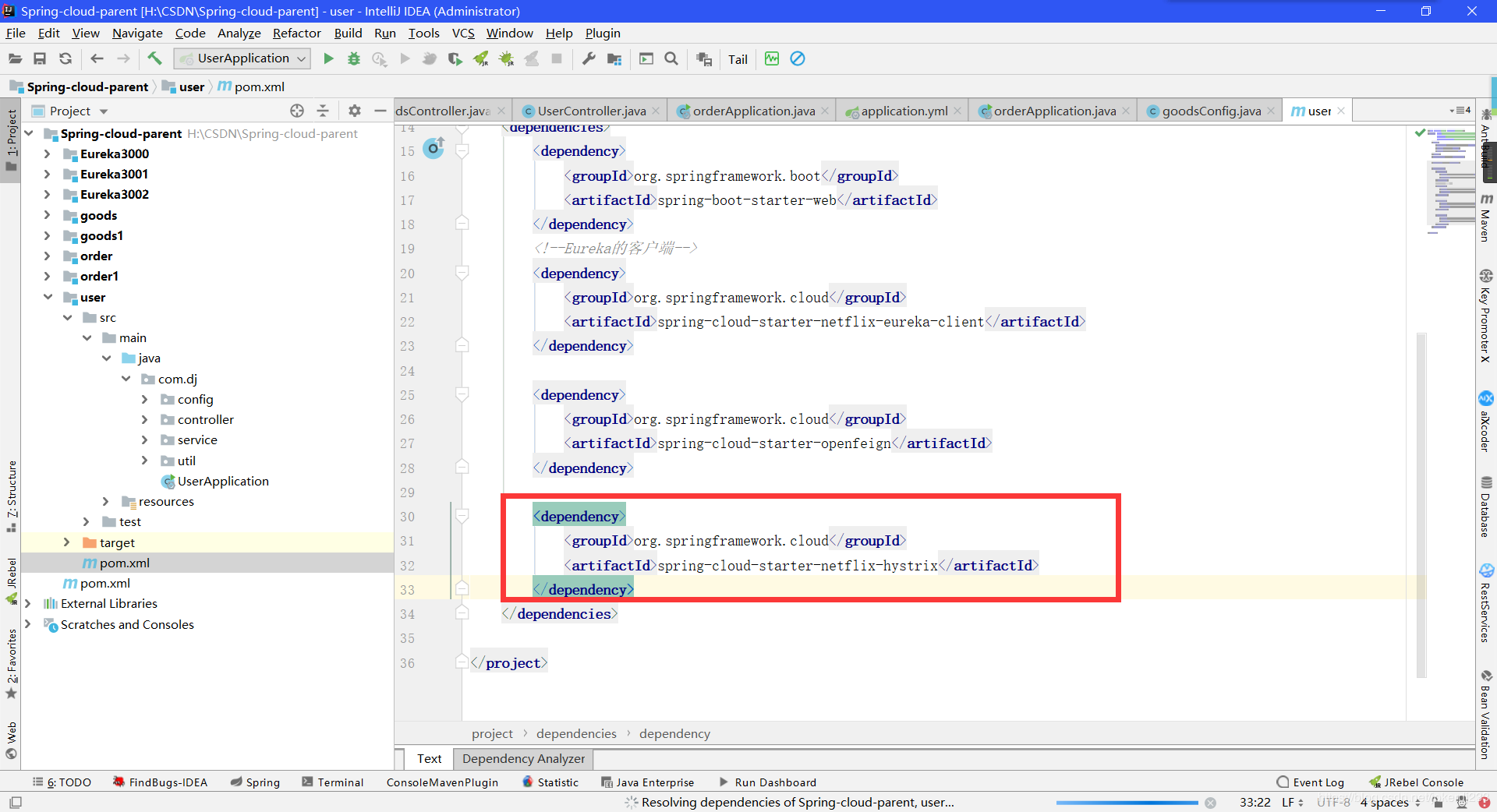
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
- 启动类加入注解@EnableHystrix
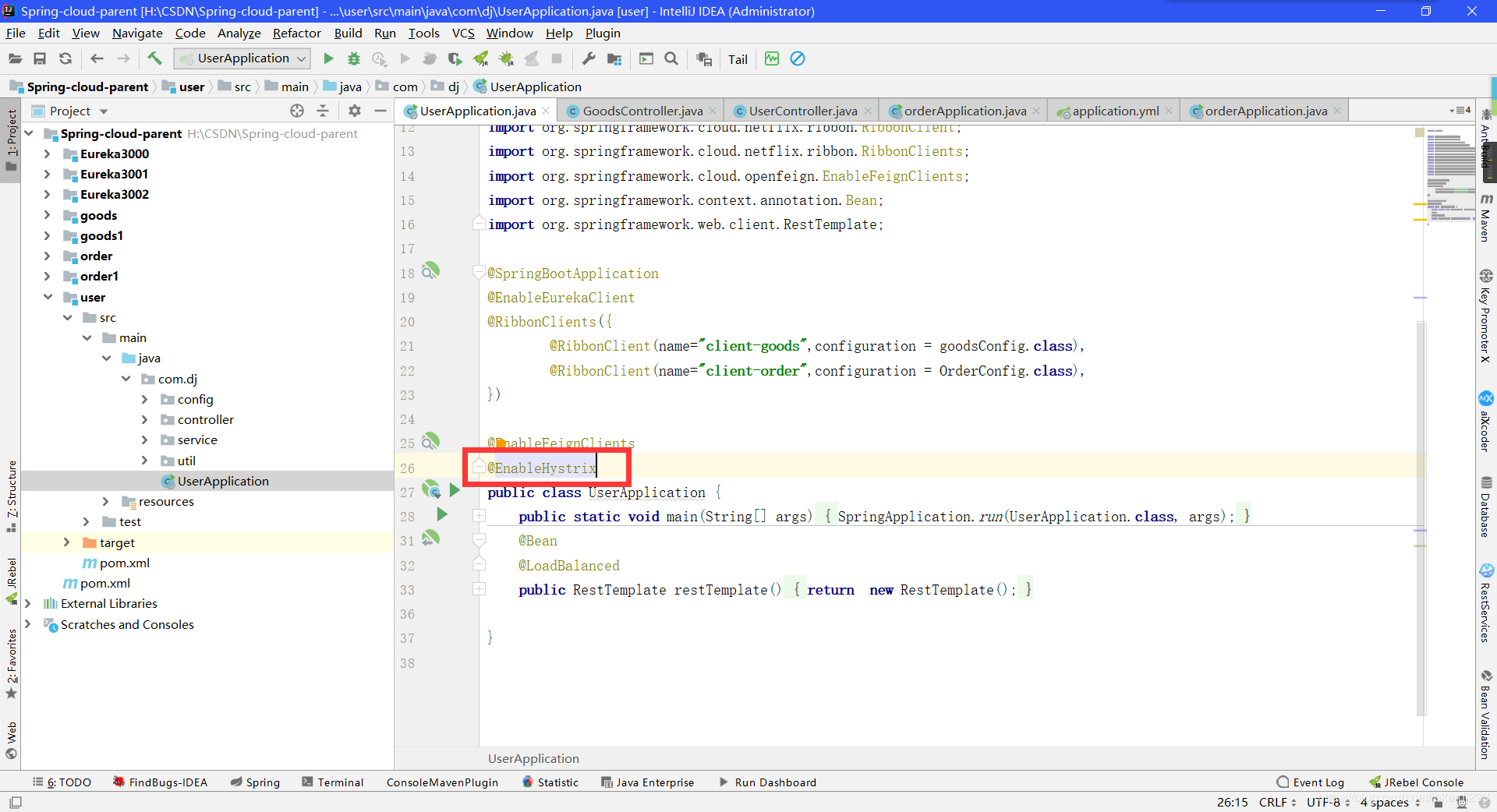
@EnableHystrix
- 在控制器调用方法上添加注解@HystrixCommand
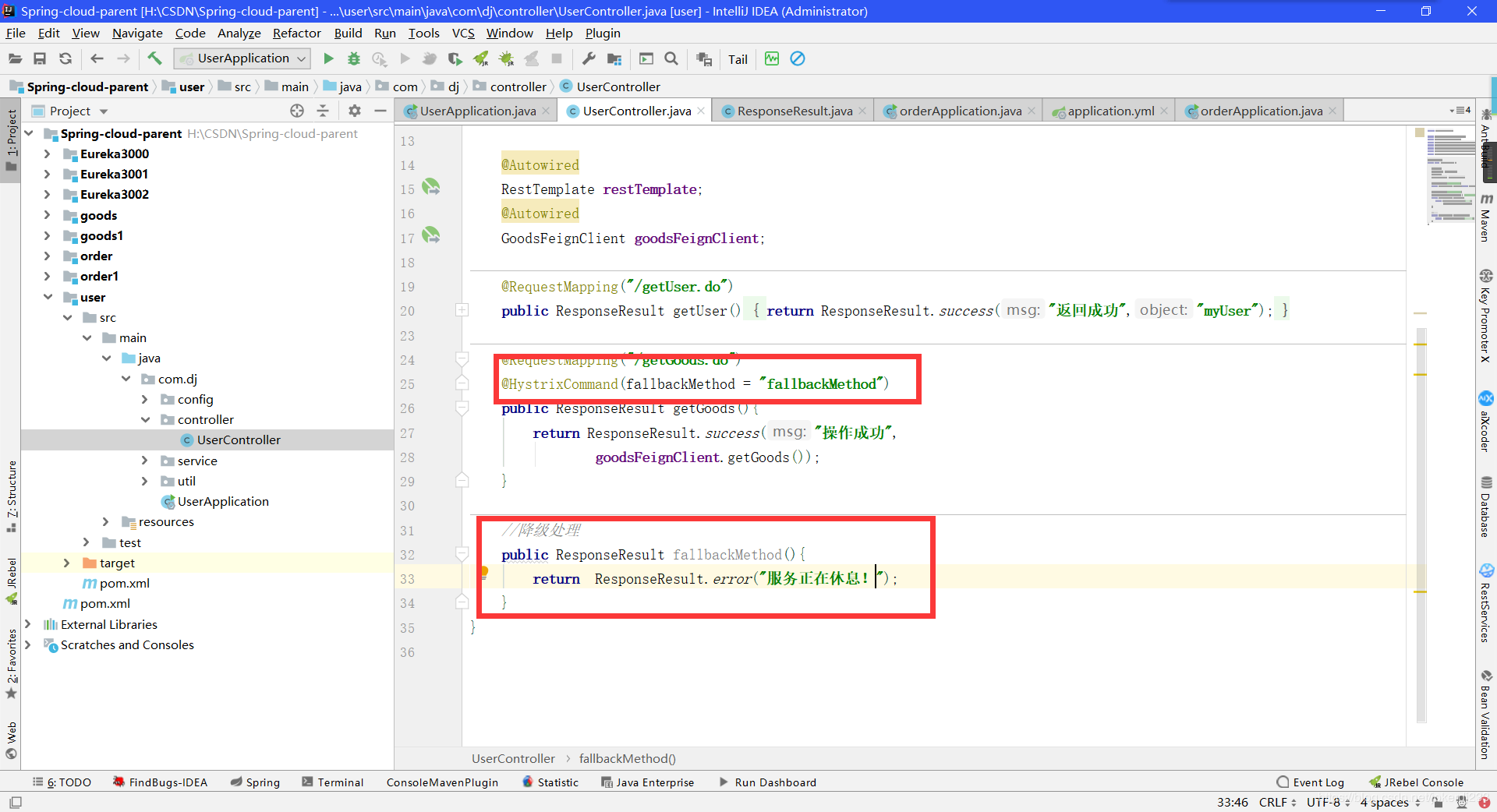
- 在goods服务当中模拟一个异常
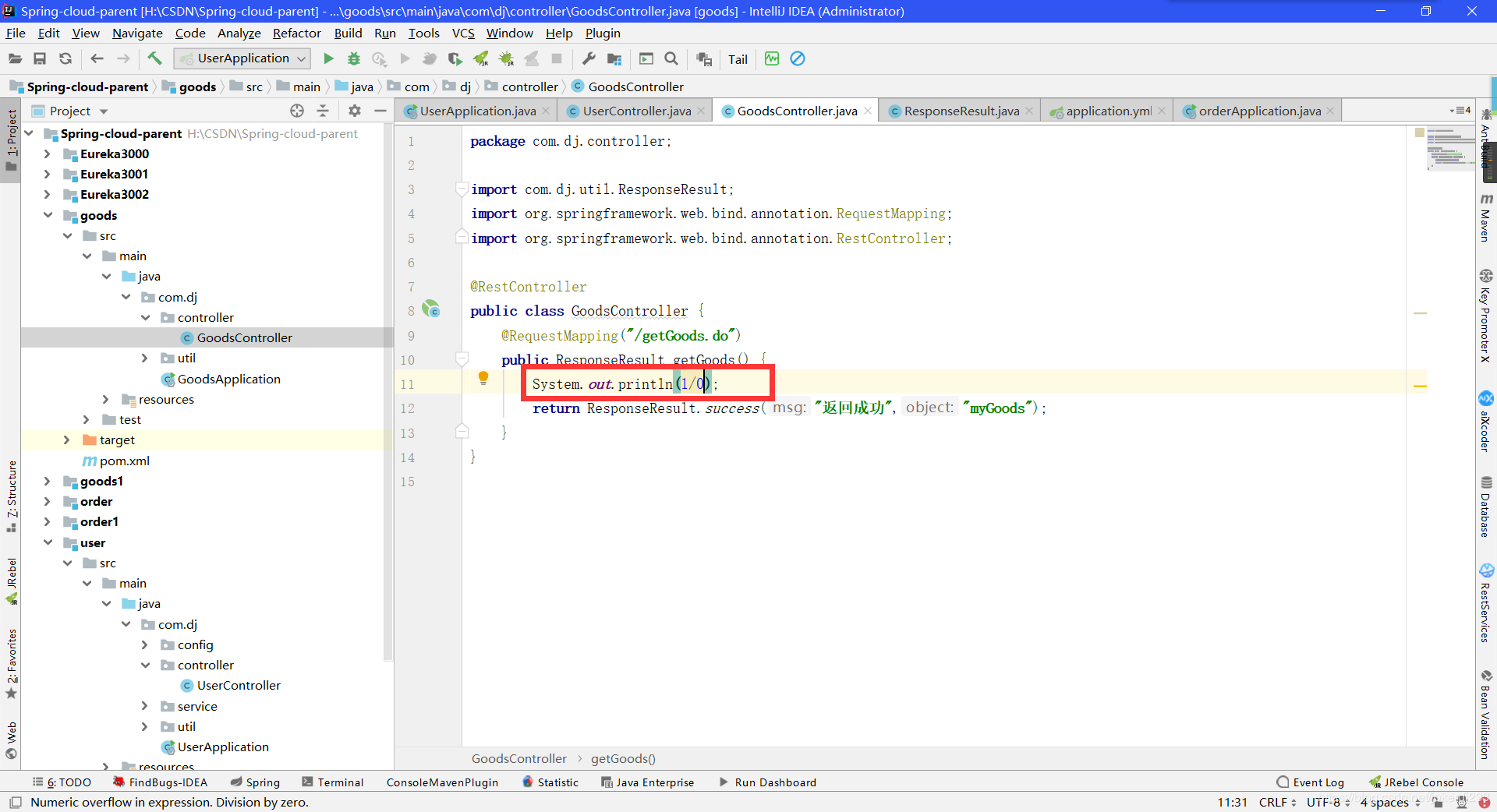
启动运行
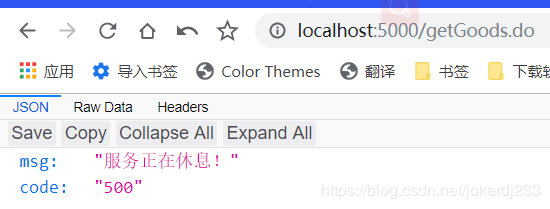
超时监听
-
模拟响应过慢
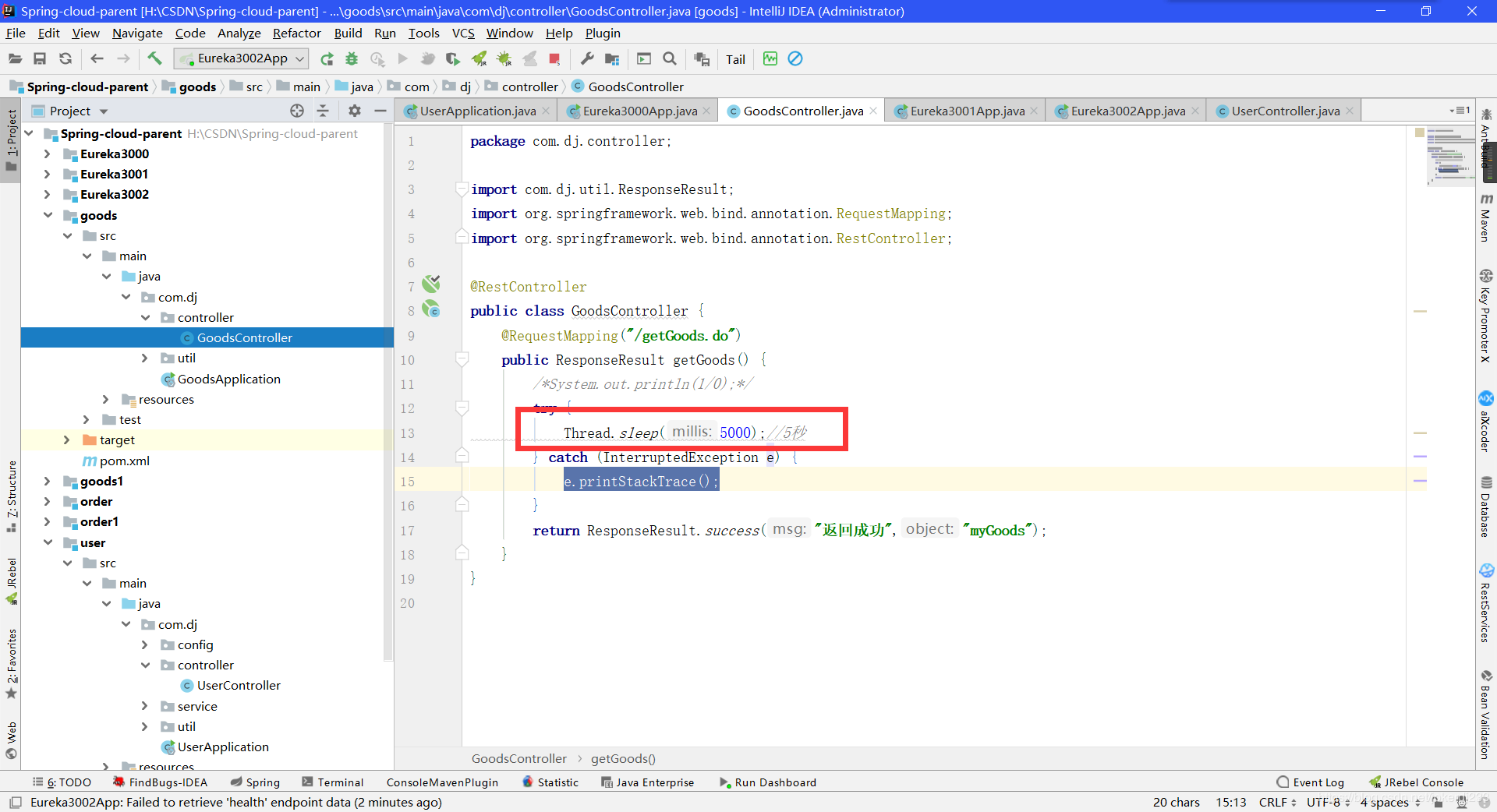
当响应过慢(默认值是1000),访问时,也会进入到指定的降级方法当中 -
在客户端配置文件当中配置超时时间
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 9000 # 设置hystrix的超时时间为9000ms
ribbon:
ReadTimeout: 10000
ConnectTimeout: 10000
使用Fengin调用
Feign默认也有对Hystix的集成,1默认情况下是关闭的。我们需要通过下面的参数来开启:
feign:
hystrix:
enabled: true # 开启Feign的熔断功能
运行
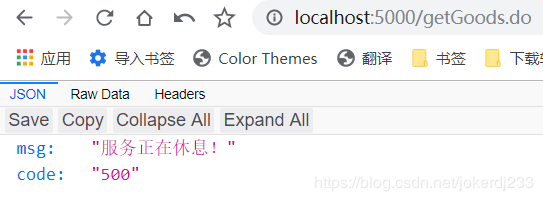
把goods的睡眠时间改成1000 运行:
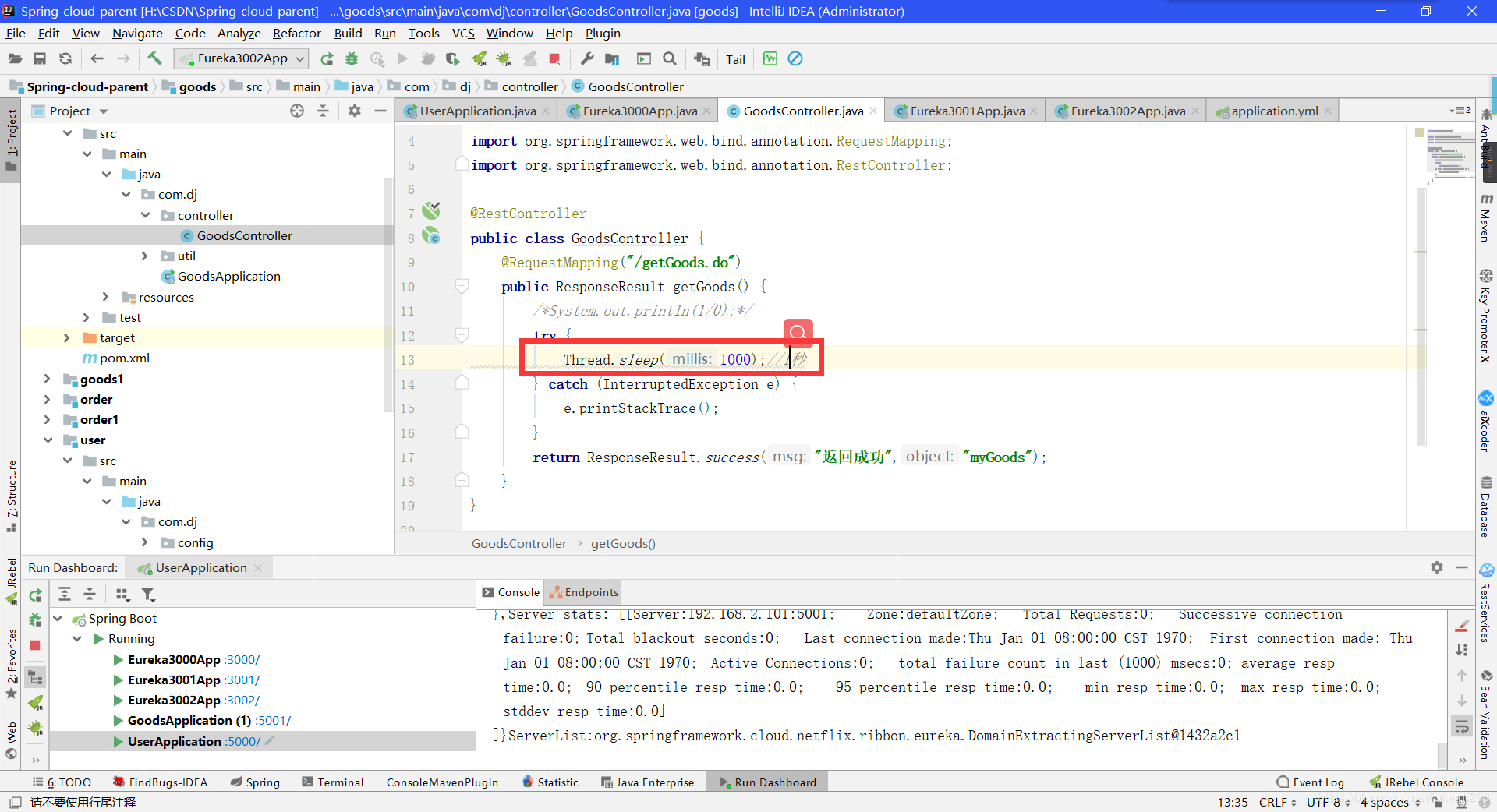
运行:
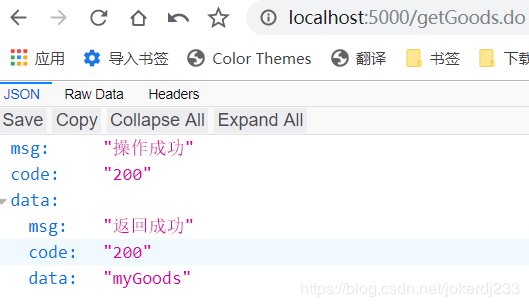
熔断
概述:
- 也叫断路器,CirleBreak
- 熔断,就好像我们生活中的跳闸一样, 比如说你的电路出故障了,为了防止出现大型事故 这里直接切断了你的电源以免意外继续发生
- 当一个微服务调用多次出现问题时(默认是10秒内20次当然 这个也能配置),hystrix就会采取熔断机制
- 不再继续调用你的方法, 而是直接调用降级方法,这样就一定程度上避免了服务雪崩的问题
- 会在默认5秒钟内和电器短路一样,5秒钟后会试探性的先关闭熔断机制,但是如果这时候再失败一次{之前是20次} 那么又会重新进行熔断
线程隔离降级处理, 如果请求延迟过高,如果超时,返回一个异常信息:
- 假设超时2秒, 但是用户也要等3秒才会返回异常信息
- 正常情况下, 一个请求只需要30ms就够了, 因为超时, 导致要多等2秒多,并发能力急剧下降,如果每次来都超时, 就认为这个服务可能存在问题,就可以认为 电路中负载最高的电压
- 此时, 就把此服务断开,再去访问时, 就不需要等待3秒,直接返回异常信息,把失败的时长急剧缩短 保证其它服务的高可用,这个服务就被临时断掉 4 断开很容易, 解决如何断开后, 再去给它连接回来, Hystrix就可以去解决这种问题
熔断配置
配置:
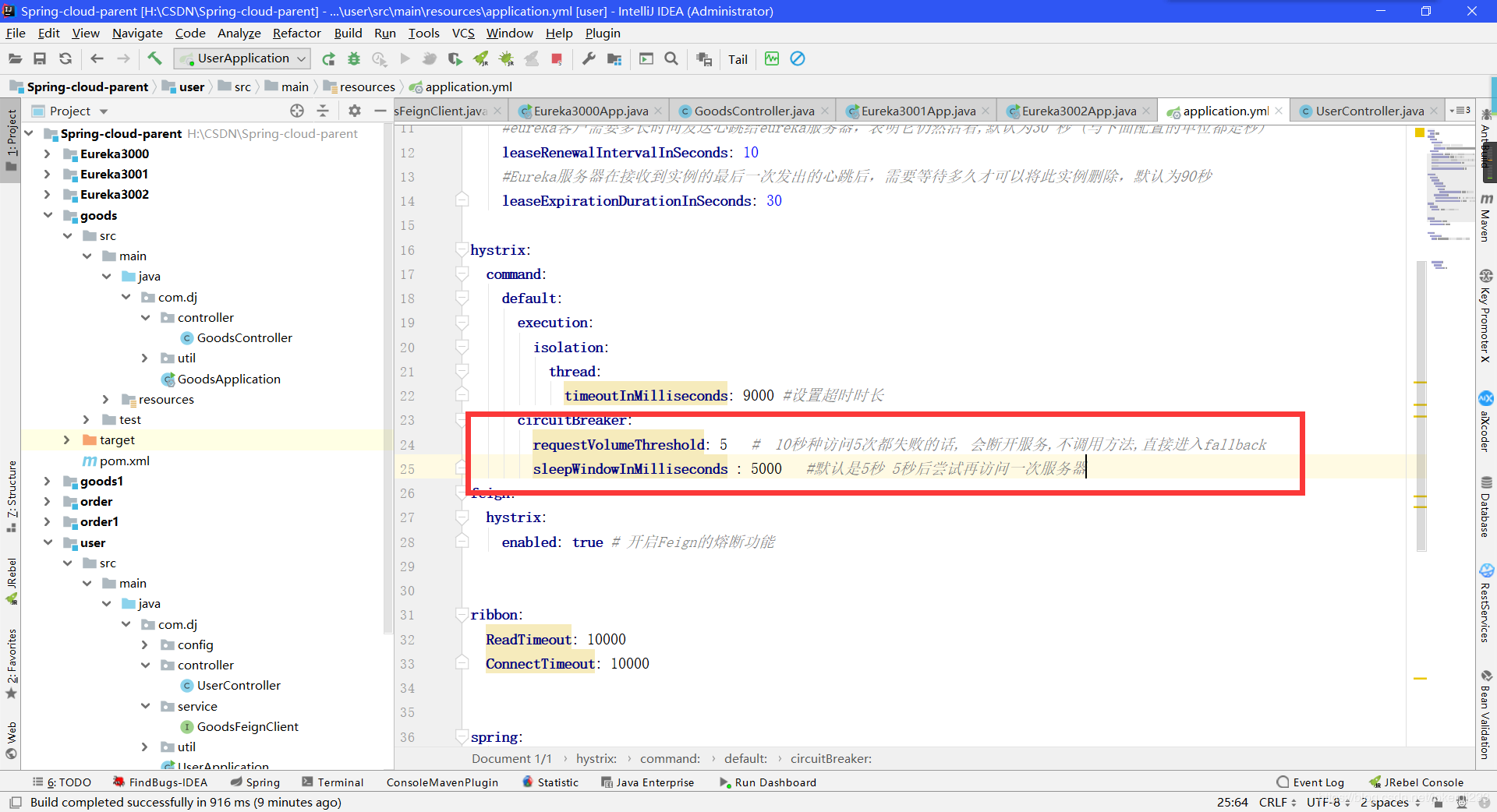
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 9000 #设置超时时长
circuitBreaker:
requestVolumeThreshold: 5 # 10秒种访问5次都失败的话, 会断开服务,不调用方法,直接进入fallback
sleepWindowInMilliseconds : 5000 #默认是5秒 5秒后尝试再访问一次服务器
goods模拟异常
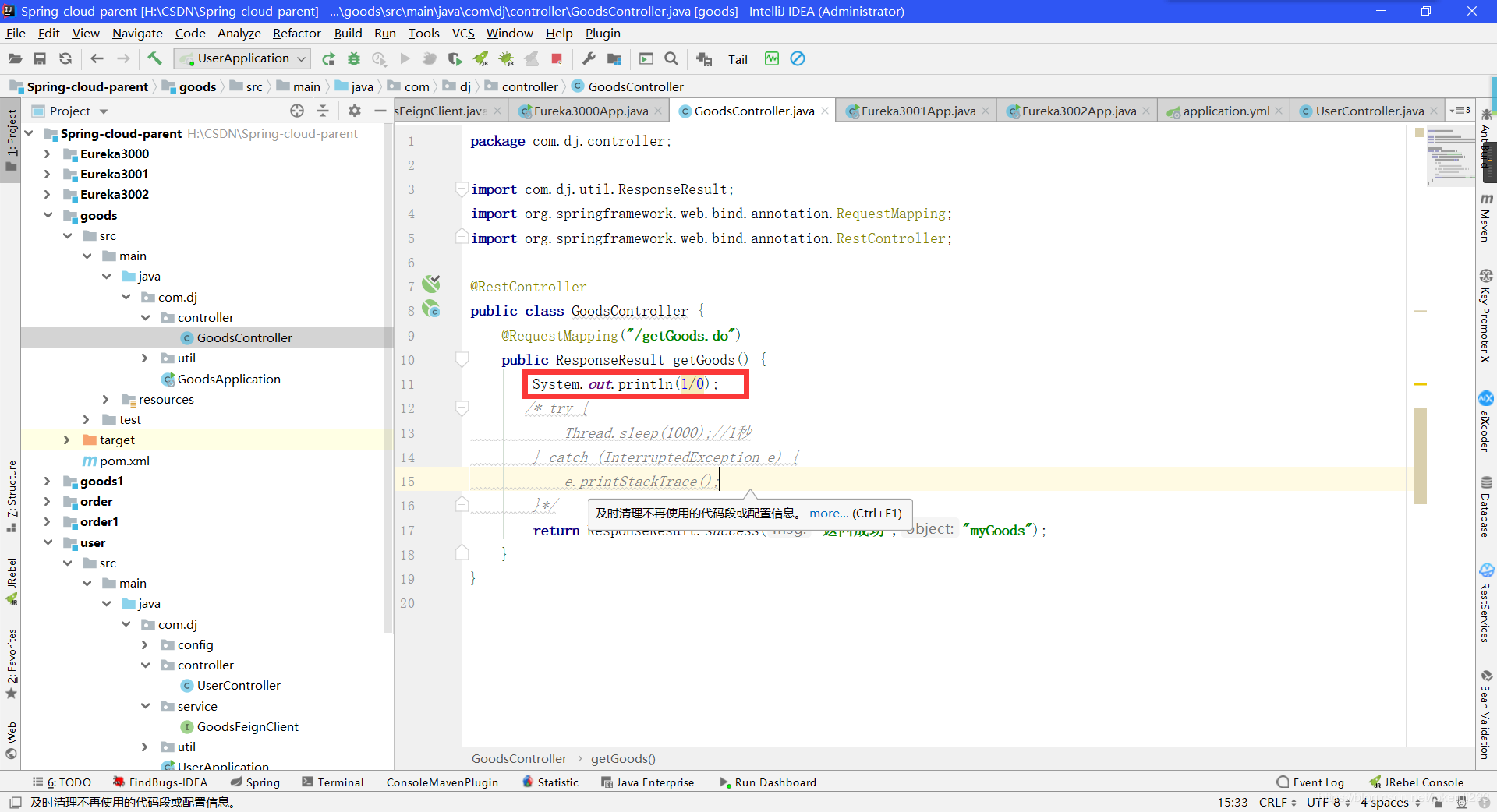
- 调用5次后,就不再调用goods方法 持续调用后,中间还会调用一次goods方法 ,之后, 就不会再调用
- 默认5秒钟后会试探性的先关闭熔断机制,但是如果这时候再失败一次{之前是20次} 那么又会重新进行熔断
限流
概念:
- 限流, 顾名思义, 就是限制你某个微服务的使用量(可用线程)
- hystrix通过线程池的方式来管理你的微服务调用,他默认是一个线程池(10大小) 管理你的所有微服务
- 一个线程可以理解为一个请求,当10请求同时访问, 都没有得要响应的时候,就会自动调用fallback方法
默认什么都不设置
当访问请求次数超过10的时候 , 会调用fallback方法
feign整合hystrix
feign 默认是支持hystrix的, 但是在Spring - cloud Dalston 版本之后就默认关闭了, 因为不一定业务需求要用的到
- 开启feign 对hystrix的支持
feign:
hystrix:
enabled: true #开启feign当中的hystrix
方式1-fallback
- 创建一个类实现服务FeignClient接口

- 在控制器当中调用
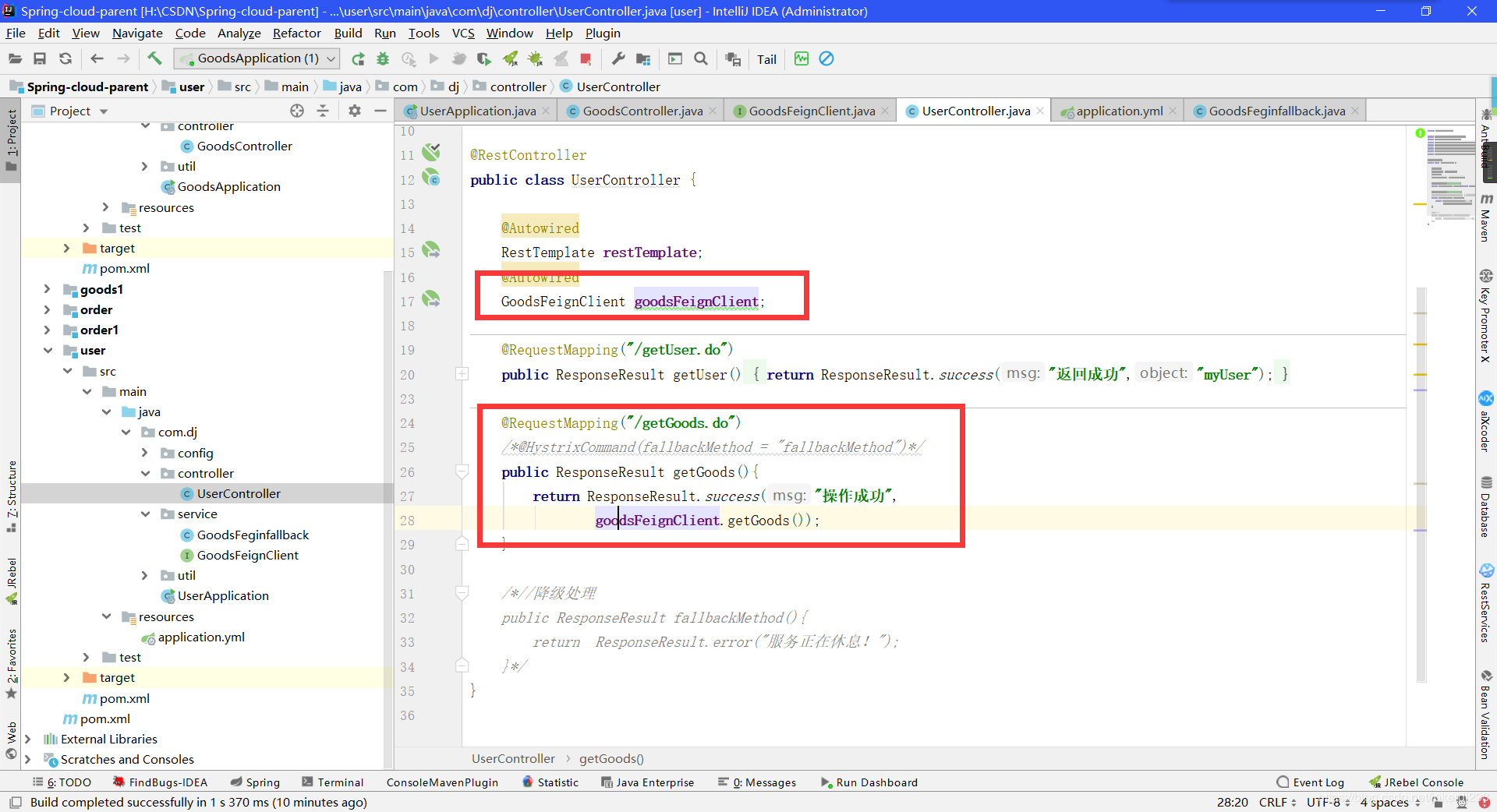
第一次运行
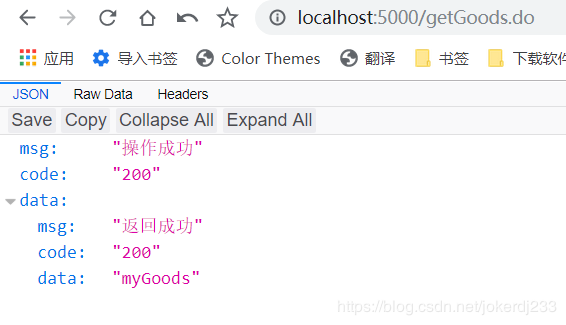
连续刷新11次后
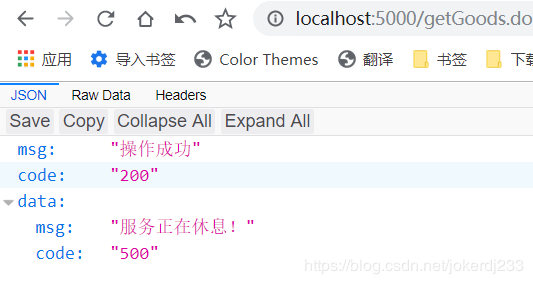
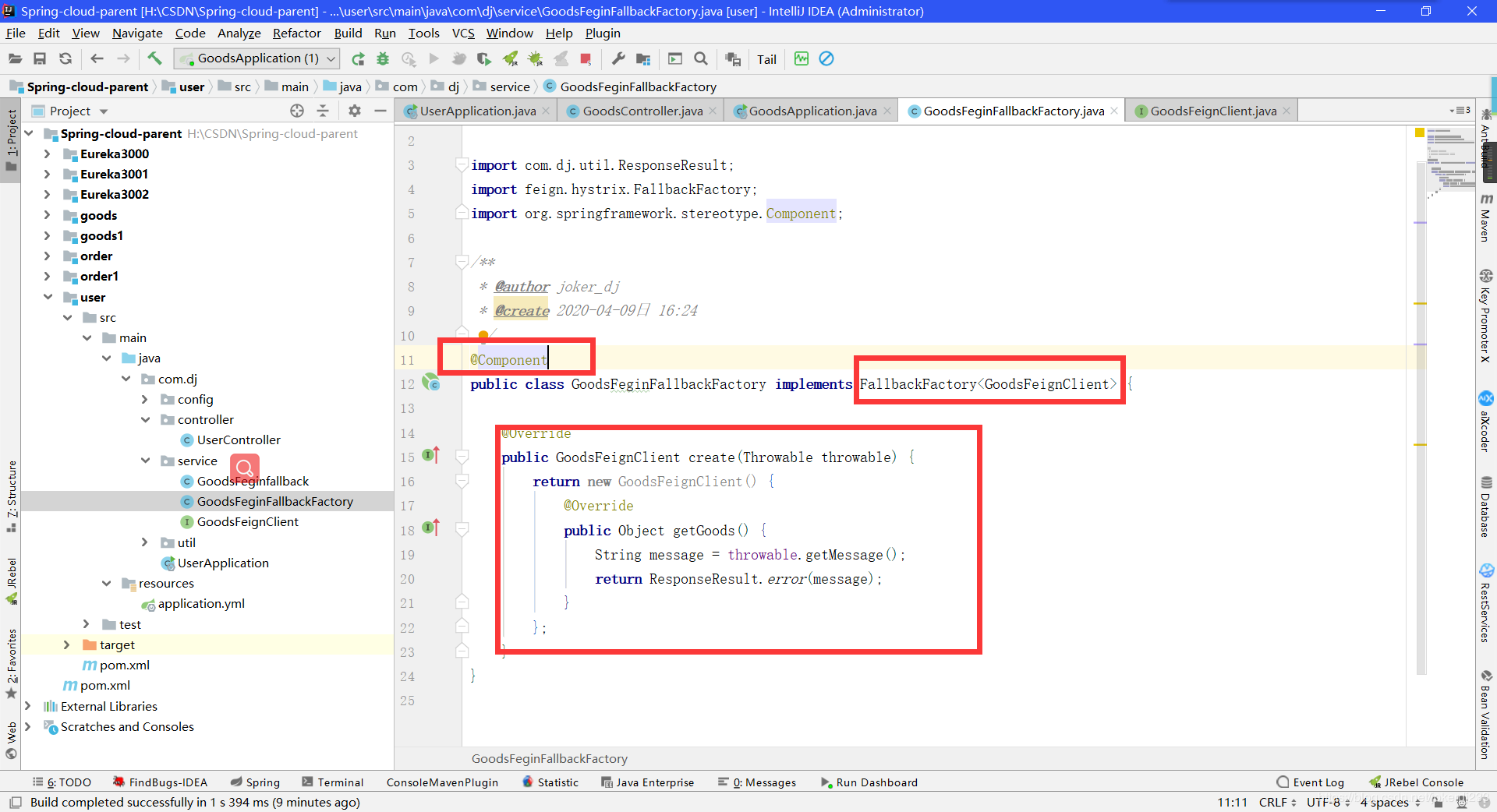
方式2-fallbackFactory
- 创建一个类实现FallbackFactory
- 在服务FeignClient接口上配置实现类
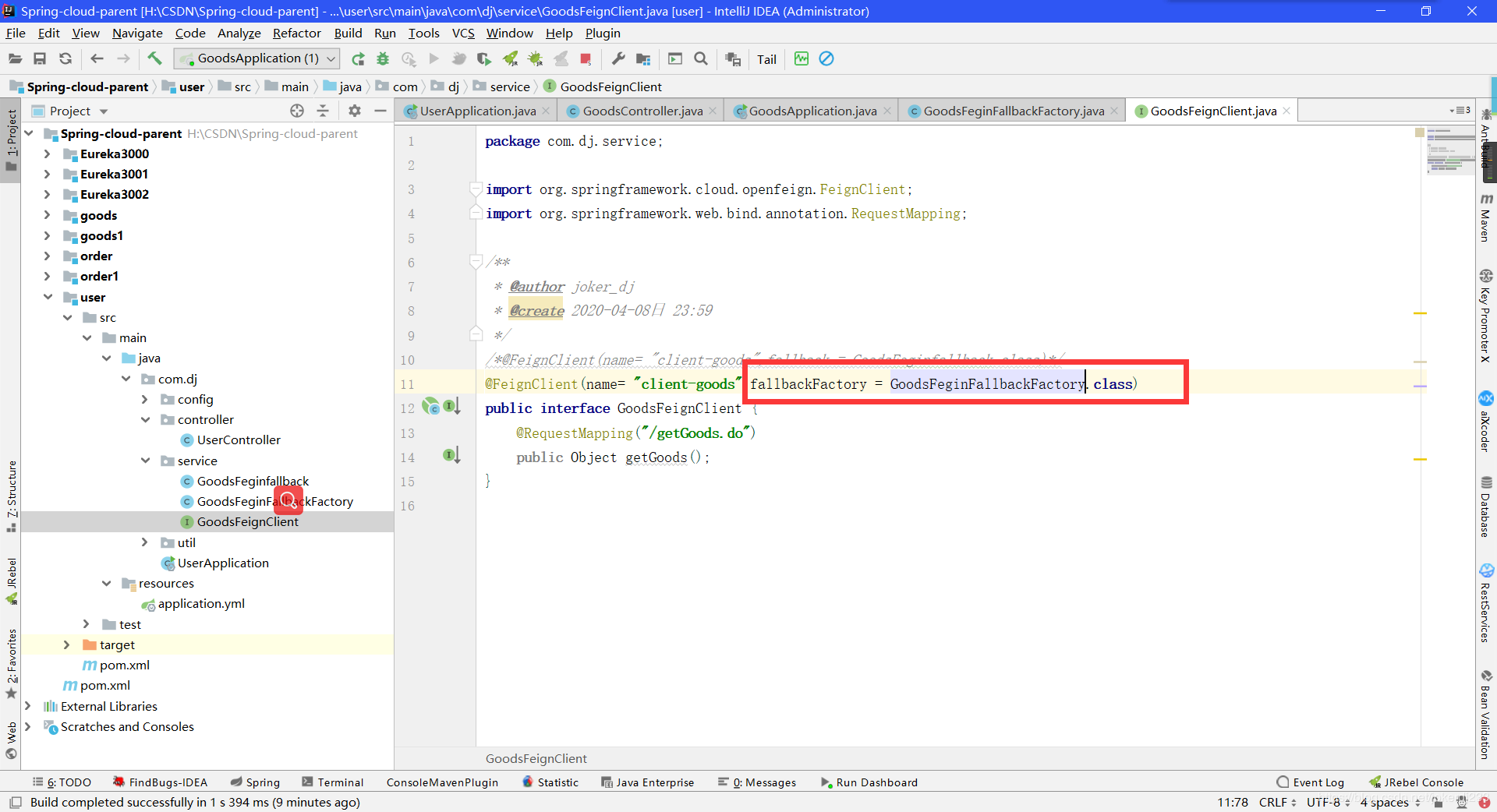
- 在控制器当中调用
效果和第一种方式一样
原文链接:https://www.cnblogs.com/joker-dj/p/12667799.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

下一篇:ONGL表达式的用法
- redis缓存 2020-06-12
- Spring系列.ApplicationContext接口 2020-06-11
- 代理项 Surrogate 2020-06-11
- DES/3DES/AES 三种对称加密算法实现 2020-06-11
- springboot2配置JavaMelody与springMVC配置JavaMelody 2020-06-11
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
