
我再也不怕面试被问 Redis 排行榜底层轮子了
2020-05-21 16:05:04来源:博客园 阅读 ()

我再也不怕面试被问 Redis 排行榜底层轮子了

[Redis]相信大家都不陌生,由于它是基于内存的,所以它相比 [MySQL] 等数据库在处理速度上,要快上 N 个数量级。
基于此,Redis 已经是现在面试中非问不可的知识点之一了。
掀起了一股学习 Redis 源码的热潮,所以今天就趁热打铁解读一个面试必问的 Redis 实时排行榜。
Redis 实现排行榜有多火呢?你只要在百度搜索 "Redis 实现排行榜", 一大波文章会跳出来。
基本都是围绕 Redis的有序集合—— zset 的 ZRANK 、ZADD 等命令展开。

如上代码所示,更多的命令用法这里就不再展开了,我们重点说说这些命令背后的原理是什么?
说到这里,你在网上接着搜索,关于底层原理几乎没有文章谈起。所以我这里打算从 Redis 4.0.9 的源码入手,针对 如何在O(logN)时间内获取一个 Redis 有序集合中的元素的排名 这一问题进行分析,并且最后手撸一个简化版的排行榜的轮子以加深理解。
分析
Redis 的 zset 的获取元素排名的核心命令为 ZRANK,官方给出的复杂度是 O(log(N))。
除了内存快于硬盘这个原因外,O(log(N)) 的时间复杂度也是根本上优于 MySQL 的 order by 进行排行的原因之二。那么我们自然好奇 Redis 是如何实现这一算法的。
在开始解毒源码之前,我们先来了解一下跳表。
跳表是神犇William Pugh于1990年发明的,这里会用最形象的语言讲清楚这玩意。
学过数据结构的都知道,数组和链表是最基本的线性数据结构,增删改查中,数组查快,增删改慢;链表恰好相反。
而且分别都是快到极致,数组 O(1) 时间完成查,链表 O(1) 时间完成增删改。
他俩就是有得必有失的典型代表。但是有些问题需要增删改查都有不错的性能,于是聪明的人类发明了半线性的数据结构,就是一大票的树结构。
例如最典型的平衡树,它能在均摊 O(logN) 时间内完成增删改查。针对特定问题,树结构成为不错的选择。
但是 William Pugh 这哥们不信邪,非要使用链表这种线性数据结构搞出 O(logN) 的查询效果出来。
于是办法就是空间换时间——多搞几层出来。
所以,典型的跳表长下面的样子(你可以将下面圆圈中的数字就视作 zset 中的分数)。
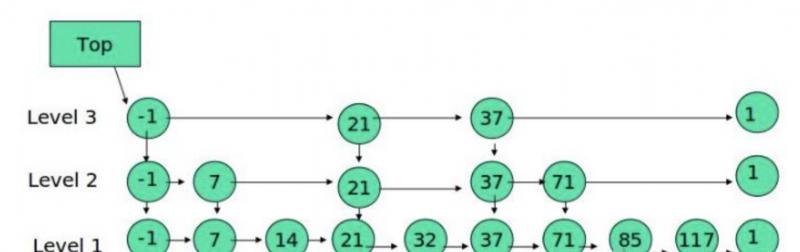
这里必须要指出跳表的特点
- 由若干层链表构成,每层都是有序的, 例如单调递增。
- 上层拥有的元素,下层一定都有,最底层拥有全部元素。
首先,跳表这玩意依旧是链表,所以完美的继承了链表的增删改的 O(1) 优良传统。其次,跳表查询的时候非常牛掰。
比如在上图中查询 117, 查询的轨迹如下图红线。
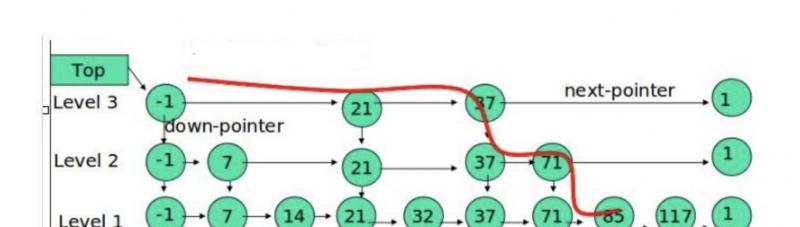
具体说要经过如下几个步骤
(1) 比较 21,比 21 大,往后面找
(2) 比较 37,比 37大,比链表最大值小,从 37 的下面一层开始找
(3) 比较 71,比 71 大,比链表最大值小,从 71 的下面一层开始找
(4) 比较 85, 比 85 大,从后面找
(5) 比较 117, 等于 117, 找到了节点。
我们知道,链表哪怕有序,也得老老实实一个一个遍历的顺序遍历去找一个元素,花费时间是 O(N),而不能像数组那样二分查找,花费时间是O(logN)。
但是跳表呢? 如上图所示,我们跳着、跳着就把元素找到了。所以跳表的名字取的还是很到位的。所谓跳着跳着,意思就是不像链表一个一个元素的去遍历,而是大步流星的前进,找到一个元素。所以跳表查询的性能远胜于普通链表。
那么, 回到获取排名的话题, 我们怎么 O(logN) 时间获取一个元素的排名呢? ?还是贴图,贴图秒懂~
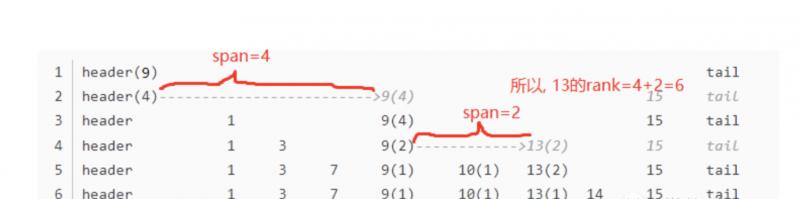
看到了吗? 我们想定位 13 这个元素在 zset 中的排名,只需要在跳表数据结构中额外维护一个叫 span 的域,它表示它在本层链表中到达下一个节点还需要走几步。上图中节点后面的圆括号里面的数字就是该节点的 span 域的值。例如第三层的节点 9 需要经过 9->10、10->13、13->14、14->15 走这 4 步才能来到它在本层链表的下一个节点 15,所以 9 的 span 是4。
有了 span 域之后,只需要在搜索 13 的过程中累加 span 即可得到。就像上图演示的那样,13 的排名是 4+2=6。
有了这些了解,我们再来回看 Redis 的源码就好懂很多了。
Redis 官网上显示,ZRANK 这一命令在 Redis2.0.0 开始就有了,我们翻看 Redis-4.0.9 的源码,就在 t_zset.c 文件中的zslGetRank 函数中。

注释写的很明白,就是通过 key 和 score 在入参 zsl 中寻找该键的排名。zsl 就是跳表,Redis 能 O(logN) 时间定位海量元素中任何一个元素的排名就靠这玩意儿。
第 11 行的 for 循环中的第 16 行在干的事情就是在累加每一层 span。而且通过第 13 行~第 15 行我们知道了 Redis 底层的排名逻辑是分数是第一关键字,key(字典序)是第二关键字进行升序排序。
最后理解了上面的跳表的思想之后,我们就可以理解,为什么 Reids 的 ZRANK 那么快,因为用跳表来实现实时排行榜功能是再合适不过的了。
Java 中,ConcurrentSkipListMap、ConcurrentSkipListSet 就是基于跳表的。根据我面试过的人来看,基本上很少有人看过它的源码,后面有时间我来唠叨它。
那么看完本文,我的面试问题来了!Redis Zset 采用跳表而不是平衡树的原因是什么?
Redis Zset 作者是这么解释的:

Redis 源码中还有非常多的精妙绝伦的设计,后面我们一起来揭开它的更多面纱吧!
收集了各方面的,当前公司的,还有自己收集总结的,下面的图片截取的有pdf,有如果有需要的自取.
各大公司面试题集合:
简历模板:

链接:?https://pan.baidu.com/s/1DO6XGkbmak7KIt6Y7JQqyw
提取码:fgj6
不知道会不会失效,如果失效点击(778490892)或者扫描下面二维码,进群获取,链接补发不过来,谢谢。

原文链接:https://www.cnblogs.com/xiaoxu456/p/12929863.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- 2020年深圳中国平安各部门Java中级面试真题合集(附答案) 2020-06-11
- JVM常见面试题解析 2020-06-11
- 作为一个面试官,我想问问你Redis分布式锁怎么搞? 2020-06-10
- 送你一份年薪百万的抖音Java岗内部面试题 2020-06-09
- 一口气说出 6种 延时队列的实现方案,面试稳稳的 2020-06-08
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
