
如何保障MySQL主从复制关系的稳定性?关键词(新…
2019-07-24 09:03:40来源:博客园 阅读 ()


一 前言
MySQL 主从架构已经被广泛应用,保障主从复制关系的稳定性是大家一直关注的焦点。MySQL 5.6 针对主从复制稳定性提供了新特性: slave 支持 crash-safe。该功能可以解决之前版本中系统异常断电可能导致 relay_log.info 位点信息不准确的问题。
本文将从原理,参数,新的问题等几个方面对该特性进行介绍。
二 crash-unsafe
在了解 slave crash-safe 之前,我们先分析 MySQL 5.6 之前的版本出现 slave crash-unsafe 的原因。我们知道在一套主从结构体系中,slave 包含两个线程:即 IO thread 和 SQL thread。两个线程的执行进度(偏移量)都保存在文件中。
IO thread 负责从 master 拉取 binlog 文件并保存到本地的 relay-log 文件中。SQL thread 负责执行重复 sql,执行 relay-log 记录的日志。
crash-unsafe 情况下 SQL_thread 的 的工作模式:
START TRANSACTION; Statement 1 ... Statement N COMMIT; Update replication info files (master.info, relay_log.info)
IO thread 的执行状态信息保存在 master.info 文件, SQL thread 的执行状态信息保存在 relay-log.info 文件。slave 运行正常的情况下,记录位点没有问题。但是每当系统发生 crash,存储的偏移量可能是不准确的(需要注意的是这些文件被修改后不是同步写入磁盘的)。因为应用 binlog 和更新位点信息到文件并不是原子操作,而是两个独立的步骤。比如 SQL thread 已经应用 relay-log.01 的4个事务
trx1(pos:10) trx2(pos:20) trx3(pos:30) trx4(pos:40)
但是 SQL thread 更新位点 (relay-log.01,30) 到 relay-log.info 文件中,slave 实例重启的时候 sql thread 会重复执行事务 trx4,于是乎,大家就看到比较常见的复制报错 error 1062,error 1032。
MySQL 5.5 通过两个参数来缓解该问题,使用 sync_master_info=1 和sync_replay_log_info=1 来保证 Slave 的两个线程每次写一个事务就分别向两个文件同步一次 IO thread 和 SQL thread 当前执行的位点信息。当然同步操作不是免费的,频繁更新磁盘文件需要消耗性能。
但是,即使设置了 sync_master_info=1 和 sync_relay_info=1,问题还是会出现,因为复制信息是在 transactions 提交后写入的,如果 crash 发生在事务提交和 OS 写文件之间,那么 relay-log.info 就可能是错误的。当 slave 从新启动的时候,最后那个事务可能会被执行两次.具体的影响取决于事务的具体操作.复制可能会继续运行比如 update/delete,或者报错 比如 insert 操作,此时主从数据的一致性可能会被破坏。
三 crash-safe 特性
3.1 保障 apply log 和更新位点信息操作的原子性
通过上面的分析,我们知道 slave crash-unsafe 的原因在于应用 binlog 和更新文件的非原子性。MySQL 5.6 版本通过将更新位点信息存放到表中,并且和正常的事务一起执行,进而保障 apply binlog 的事务和更新 relay info 信息到 slave_relay_log_info 的原子性.
就是把 SQL thread 执行事务和更新 mysql.slave_replay_log_info 的语句合并为同一个事务,由 MySQL 系统来保障事务的原子性。我们可以通过伪代码来模拟 crash-safe 的原理:crash-safe 情况下 SQL_thread 的工作模式
START TRANSACTION; Statement 1 ... Statement N Update replication info COMMIT
一图胜千言:
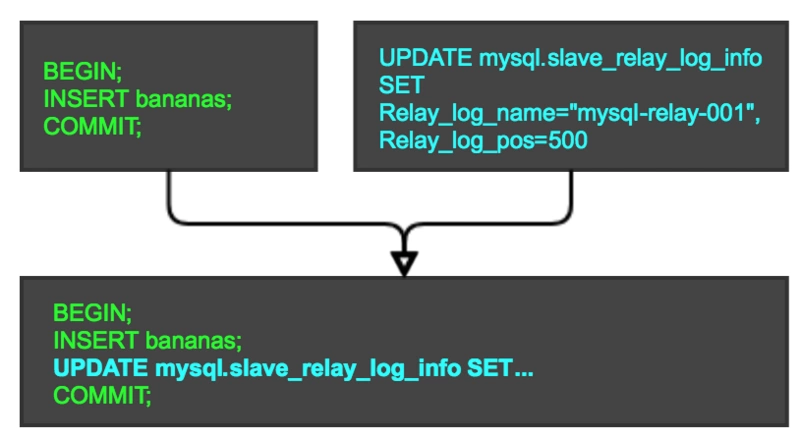
绿色的代表实际业务的事务,蓝色的是开启 MySQL 执行的更新slave_replay_log_info 相关位点信息的 sql ,然后将这两个 sql 合并在一个事务中执行,利用 MySQL 事务机制和 InnoDB 表保障原子性。不会出现应用 binlog 和更新位点信息两个动作割裂导致不一致的问题。
3.2 crash 后的恢复动作
通过设置 relay_log_recovery = ON,slave 遇到异常 crash,然后重启的时候,系统会删除现有的 relay log,然后 IO thread 会从 mysql.slave_replay_log_info 记录的位点信息重新拉取主库的 binlog。MySQL 如此设计的出发点是:
- SQL thread apply binlog 的位点永远小于等于 IO thread 从主库拉取的位点。
- SQL thread 记录的位点是已经执行并且提交的事务之后位点信息。
一图胜千言:
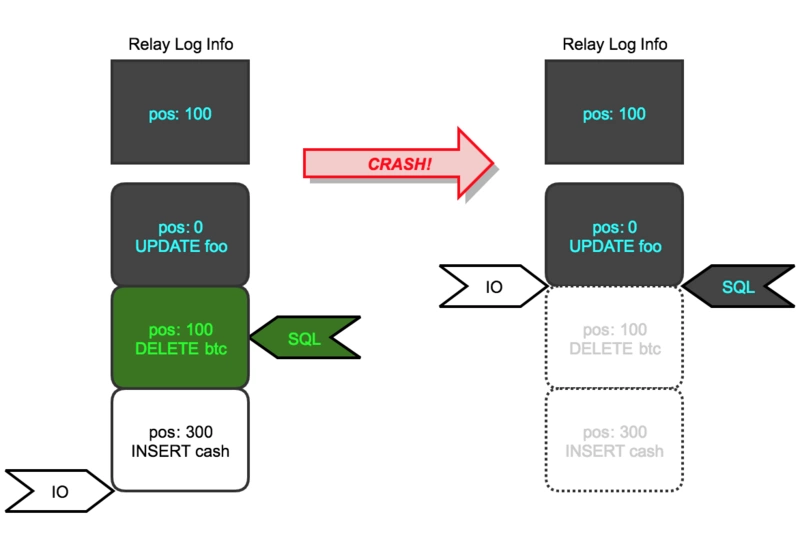
蓝色的 update 语句代表已经执行并提交的事务,绿色的 delete 语句表示正在执行的 sql,还未提交。此时 slave_replay_log_info 表记录的 relay log info是**update 语句结束,delete 语句开始之前的位点
(relay_log.01,100)** 。如果遇到系统 crash,slave 实例重启之后,会删除已经有的 relaylog,并且 IO thread 会从(relay_log.01,100)对应的 master binlog 位点重新拉取主库的 binlog,SQL thread 也会从这个位点开始应用 binlog。
3.3 GTID 模式下的 crash safe
和基于位点的复制不同,GTID 模式下使用新的复制协议 COM_BINLOG_DUMP_GTID 进行复制。举个??
实例 a 的事务集合 set_a, 实例 b 的事务集合 set_b ,设置 b 为 a 的从库的时候,其中的 binlog 协议伪算法如下:
- 实例 b 指向主库实例 a, 基于主备协议建立主从关系
-
实例 b 将 GTID 信息发送给实例 a
UNION(@@global.gtid_executed, Retrieved_gtid_set - last_received_GTID)
- 实例 a 计算出 set_b 与 set_a 的差集,也就是存在于 set_a 但是不存在与 set_b 的 GTID 集合,判断实例 a 本地的 binlog 是否包含了该差集所需要的所有 binlog 事务。
a 如果不包含,表示实例 a 已经把实例 b 需要的 binlog 删除了,直接返回报错。
b 如果确认全部包含 实例 a 从本地 binlog 文件里面,找到第一个不在 set_b 的事务,发送给实例 b。
- 从这个事务开始,往后读文件,按顺序取 binlog 发送给实例 b。
GTID 模式下,slave crash-safe 运行机制
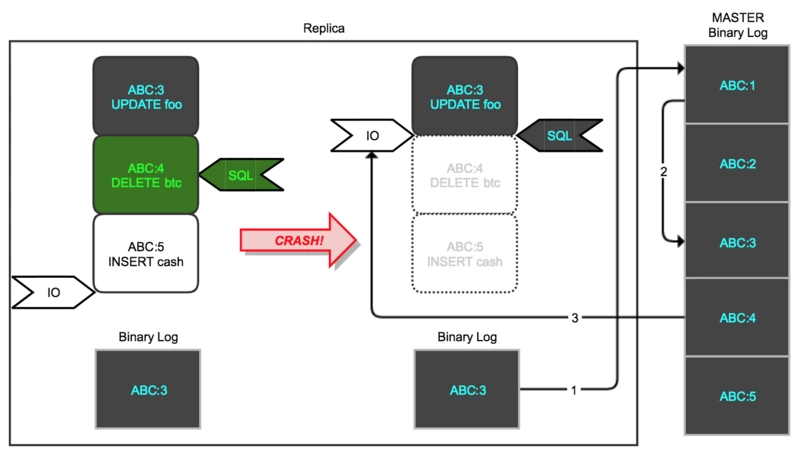
蓝色 ABC:3 表示已经执行并提交的事务,绿色 ABC:4表示正在执行的事务,此时 slave crash,实例记录的 gtid_executed=ABC:1-3,系统重启 relay_log 被删除。slave 将 UNION(@@global.gtid_executed, null) 发送到主库,主库会将 ABC:3 以后的 binlog 传送给 slave 继续执行。
注意
从新的复制协议中slave重启时是基于binlog中的GTID信息进行复制的,并不依赖于mysql.slave_replay_log_info。为了保障binlog及时落盘slave要设置 双1模式 **sync_binlog = 1
innodb_flush_log_at_trx_commit = 1**
3.4 如何开启 crash-safe 特性
通过配置两个如下两个参数开启该特性。
relay_log_info_repository = TABLE
relay_log_recovery = ON
看到这里是不是有疑问为什么没有 master.info 相关的参数配置?
其实开启 slave 的 crash-safe 之后,slave 重启的时候会自动清空之前的 relay-log,IO thread 从 mysql.slave_relay_log_info 表中记录的位点开始拉取数据,而不是依赖 slave_master_info 表相关数据。
注意:
如果是 MySQL 5.6.5 或者更早期。slave_master_info 和 slave_relay_log_info 表默认使用 MyISAM 引擎。所以还得修改成 innodb,如下:
ALTER TABLE mysql.slave_master_info ENGINE=InnoDB;
ALTER TABLE mysql.slave_relay_log_info ENGINE=InnoDB;
3.5 相关参数
-
开启 crash-safe 之后,slave 重启之后,不再依赖 master info 相关的参数,所以这两个参数不做过多讨论。不过为了和 relay log info 存储一致,推荐存储 maste-info 到表里,sync_master_info 保持默认,设置为比较低的值,在写压力比较大的情况下,会有 IO 损耗。
master_info_repository =TABLE sync_master_info=0 -
开启 crash-safe 必要参数
relay_log_info_repository = TABLE relay_log_recovery = 1这 2 个不多做介绍了,前面已经将的非常透彻。
- relay log 相关
当 relay_log_info_repository=file 时,
更新位点信息的频率依赖于sync_relay_log_info = N (N>=0):a 当 sync_relay_log_info=0 时,MySQL 依赖 OS 系统定期更新。
b 当 sync_relay_log_info=N时(N>0),
MySQL server 会在每执行 N 个事务之后调用 fdatasync() 刷 relay-log.info 文件。当 relay_log_info_repository=table
如果 mysql.slave_relay_log_info 是 innodb 存储引擎,则每次事务更新,系统会自动忽略 sync_relay_log_info 的设置。
如果 mysql.slave_relay_log_info 是非事务存储引擎,则
a 当 sync_relay_log_info=0 时,不更新。
b 当 sync_relay_log_info=N 时(N>0),
MySQL server 会在每执行 N 个事务之后调用 fdatasync() 刷 relay-log.info 文件。sync_relay_log 控制着 relay-log 的刷新策略,类似 sync_binlog。不过这个参数在开启 crash-safe 特性之后没有什么实质的意义。建议保持该参数为默认值即可。

四 其他问题
每个硬币都有它的两面性。开启 crash-safe 会带来哪些潜在的问题?
1 重启 slave,重新拉取 relay-log,一主多从的集群会给主库带来 IO 和带宽压力。
2 主库不可用,或者 binlog 被删除了,slave 找不到所需要的 binlog。
参考文章
[1] https://hackmongo.com/post/cr...
[2] http://dev.mysql.com/doc/refm...
[3] http://dev.mysql.com/doc/refm...
原文链接:https://www.cnblogs.com/lfs2640666960/p/11191768.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- MySQL replace函数怎么替换字符串语句 2020-03-09
- PHP访问MySQL查询超时怎么办 2020-03-09
- mysql登录时闪退 2020-02-27
- MySQL出现1067错误号 2020-02-27
- mysql7.x如何单独安装mysql 2020-02-27
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
