
面试官:给我讲一下分库分表方案
2019-08-09 05:49:07来源:编程学习网 阅读 ()

一、数据库瓶颈
不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。接下来就可以想象了吧(并发量、吞吐量、崩溃)。
1、IO瓶颈
2、CPU瓶颈
二、分库分表
1、水平分库
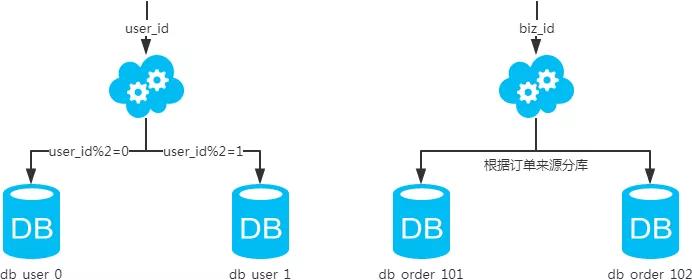
2、结果:
每个库的结构都一样;
每个库的数据都不一样,没有交集;
所有库的并集是全量数据;
2、水平分表

2、结果:
每个表的结构都一样;
每个表的数据都不一样,没有交集;
所有表的并集是全量数据;
3、垂直分库
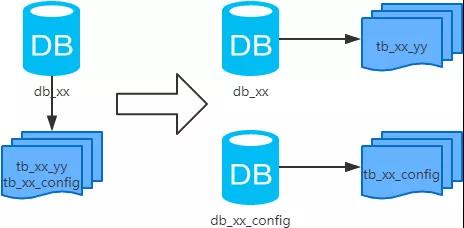
2、结果:
每个库的结构都不一样;
每个库的数据也不一样,没有交集;
所有库的并集是全量数据;
4、垂直分表

2、结果:
每个表的结构都不一样;
每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据;
所有表的并集是全量数据;
三、分库分表工具
1、sharding-sphere:jar,前身是sharding-jdbc;2、TDDL:jar,Taobao Distribute Data Layer;3、Mycat:中间件。
四、分库分表步骤
根据容量(当前容量和增长量)评估分库或分表个数 -> 选key(均匀)-> 分表规则(hash或range等)-> 执行(一般双写)-> 扩容问题(尽量减少数据的移动)。五、分库分表问题
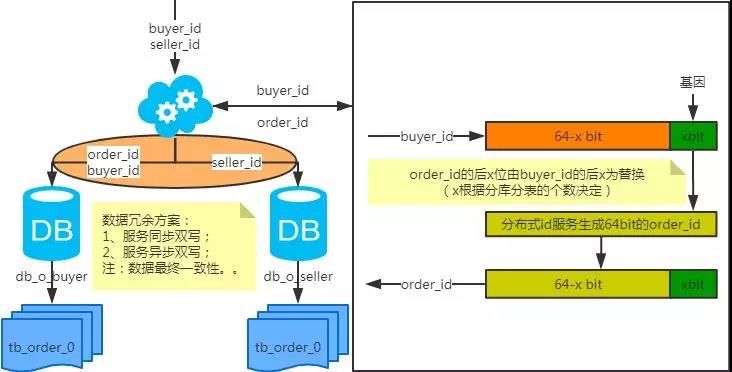
1、非partition key的查询问题(水平分库分表,拆分策略为常用的hash法)
1、端上除了partition key只有一个非partition key作为条件查询
映射法
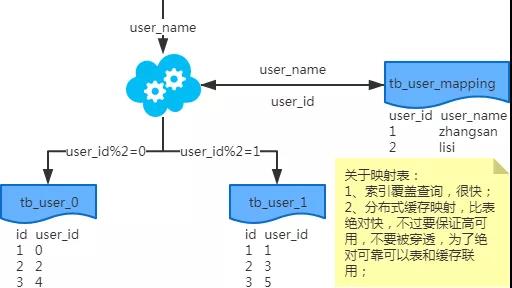
-
基因法
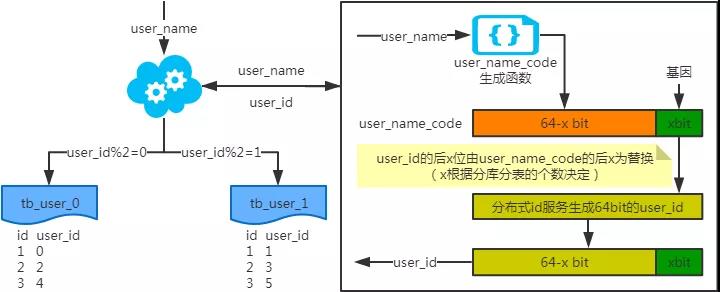
2、端上除了partition key不止一个非partition key作为条件查询
映射法
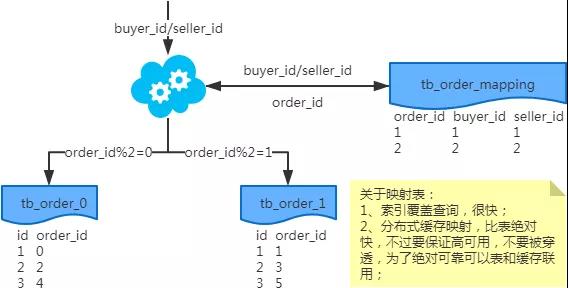
-
冗余法
3、后台除了partition key还有各种非partition key组合条件查询
NoSQL法
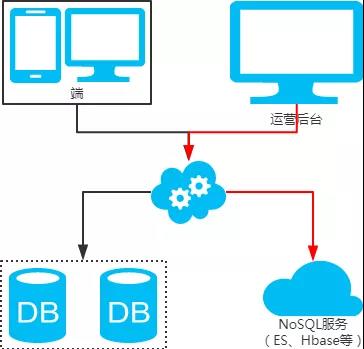
-
冗余法
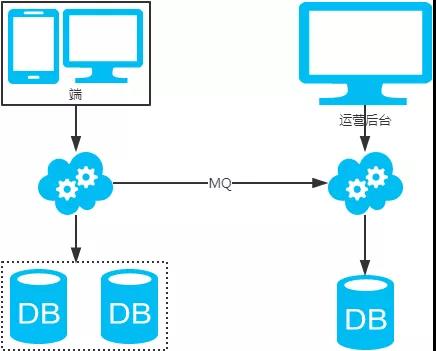
2、非partition key跨库跨表分页查询问题(水平分库分表,拆分策略为常用的hash法)
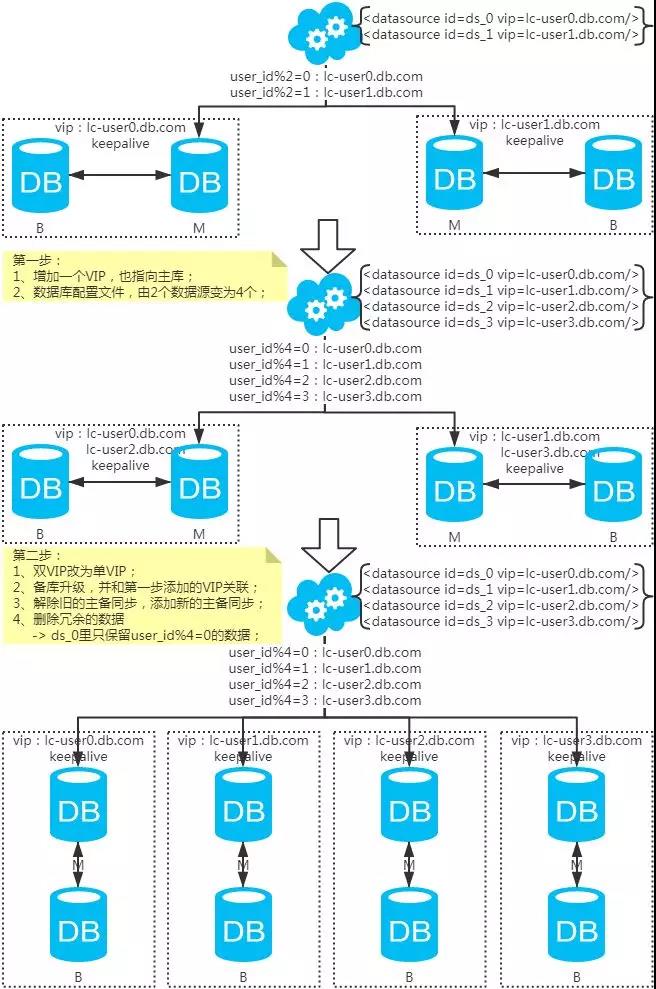
3、扩容问题(水平分库分表,拆分策略为常用的hash法)
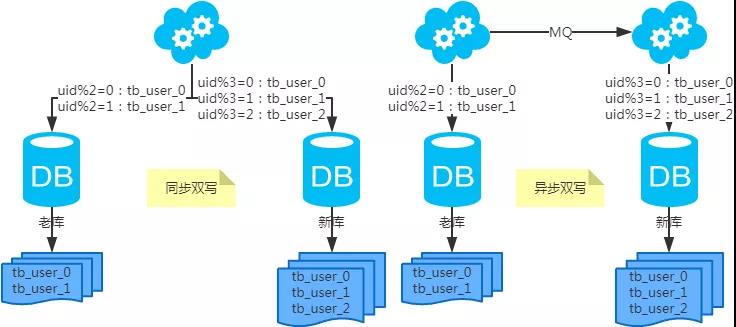
第二步:(同步双写)将老库中的老数据复制到新库中;
第三步:(同步双写)以老库为准校对新库中的老数据;
第四步:(同步双写)应用去掉双写,部署;
六、分库分表总结
分库分表,首先得知道瓶颈在哪里,然后才能合理地拆分(分库还是分表?水平还是垂直?分几个?)。且不可为了分库分表而拆分。
七、分库分表示例
示例GitHub地址:https://github.com/littlecharacter4s/study-sharding原文链接:http://www.phpxs.com/post/6436/
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- 面试官问我:一个 TCP 连接可以发多少个 HTTP 请求?我竟然 2019-09-30
- 提问频率较高的php面试题 2019-09-23
- 学PHP必知PHP岗位面试题 2019-09-17
- 面试:如何解决web高并发?这个回答给满分 2019-09-08
- 项目上线后,谈一下感触比较深的一点:查询优化 2019-09-08
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
