
day06
2019-05-16 23:58:49来源:博客园 阅读 ()

1、小知识点汇总


1 # 赋值后的地址是一样的 2 li1 = [1,2,3] 3 li2 = li1 4 print(li1 is li2)# is 用于判断li1的地址是否和li2的地址一样,结果输出为True 5 print(id(li1))# id()用于输出地址 6 print(id(li2)) 7 # 2440684855944 8 # 2440684855944
在python3中,有小数据池的概念,凡是数字在-5到256之间,他们都共用一个地址,目的是为了节省空间,由于PyCharm的机制原因,不能体现出这种变化,所以我在cmd中实现。
2、编码讲解
以下是各个编码对A和中的表示。注意以下二进制的表示都是随意设置,并无根据,只是为了方便做笔记。
ASCLL码
A : 00000010 8位 一个字节
unicode
A : 00000000 00000001 00000010 00000100 32位 四个字节
中: 00000000 00000001 00000010 00000110 32位 四个字节
utf-8
A : 00100000 8位 一个字节
中: 00000001 00000010 00000110 24位 三个字节
gbk
A : 00000110 8位 一个字节
中 : 00000010 00000110 16位 两个字节
在python2和python3中:
1,各个编码之间的二进制,是不能互相识别的,会产生乱码。
2,文件的储存,传输,不能是unicode(只能是utf-8、utf-16、gbk、gb2312、ASCLL等)
在python3中:
str 在内存中是用unicode编码。Python 3最重要的新特性之一是对字符串和二进制数据流做了明确的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。
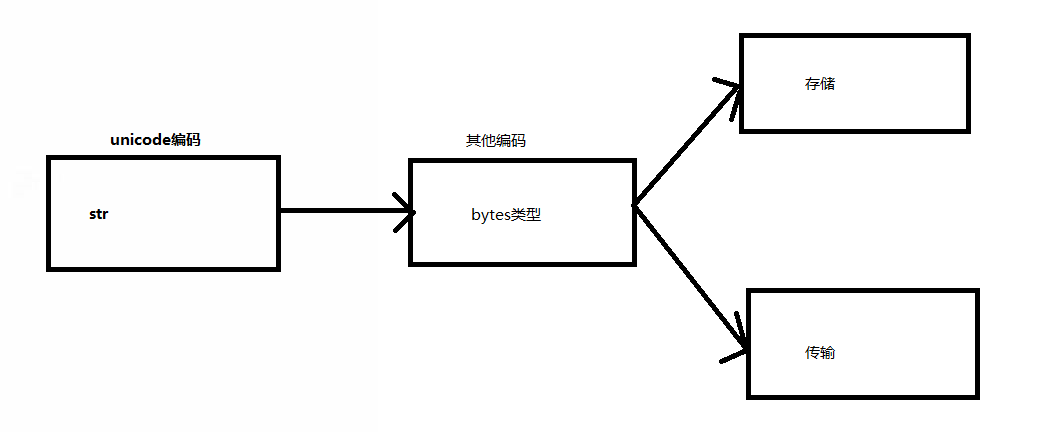
数据的存储和传输,只能由bytes类型进行。
对于英文:
str :表现形式:s = 'alex'
编码方式: 010101010 unicode
bytes :表现形式:s = b'alex'
编码方式: 000101010 utf-8、gbk。。。。
1 s = 'alex' 2 s1 = b'alex' 3 print(s,type(s)) 4 print(s1,type(s1)) 5 # result: 6 # alex <class 'str'> 7 # b'alex' <class 'bytes'>
对于中文:
str :表现形式:s = '中国'
编码方式: 010101010 unicode
bytes :表现形式:s = b'\xe4\xb8\xad\xe5\x9b\xbd'
1 s = '中国' 2 print(s,type(s)) 3 b = bytes(s,encoding='utf-8') 4 print(b)
可以看出这里是用utf-8编码,utf-8是三个字节,中国两个字就有六个字节,故表现形式里面就有了六个。
1 s = '中国' 2 print(s,type(s)) 3 b = bytes(s,encoding='gbk') 4 print(b)
在这里用的是gbk编码,故他的结果是四个:b'\xd6\xd0\xb9\xfa'
编码方式: 000101010 utf-8 gbk。。。。
原文链接:https://www.cnblogs.com/missdx/p/10863960.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- 网络编程相关知识点 2019-08-13
- 整合 User-Agent 大全汇总 2019-07-24
- python 基础知识汇总―― if else while continue 2019-05-16
- 【Python实践-1】求一元二次方程的两个解 2019-04-21
- day06 2019-04-20
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
