
Web框架之Django_05 模型层了解(单表查询、多表…
2019-06-14 08:05:06来源:博客园 阅读 ()

摘要:
-
单表查询
-
多表查询
-
聚合查询
-
分组查询
一、Django ORM 常用字段和参数:
- 常用字段:
#AutoField
int自增列,必须填入参数primary_key = True,当model中如果没有自增列,则会自动创建一个列名为id的列
#IntegerField
一个整数类型,范围在--2147483648 to 2147483647。(一般不用它来存手机号(位数也不够),直接用字符串存)
#CharField
字符类型,必须提供max_length参数,max_length表示字符长度
Tips:Django的CharField对应的MySQL数据库中的varchar类型,没有设置对应char类型的字段,但是Django允许我们自定义新的字段,下面我来自定义对应于数据库的char类型
需要注意的是:自定义字段在实际项目应用中可能会经常用到,所以这里需要留意。#应用上面自定义的char类型 class Class(models.Model): id=models.AutoField(primary_key=True) title=models.CharField(max_length=32) class_name=RealCharField(max_length=16) gender_choice=((1,'男'),(2,'女'),(3,'保密')) gender=models.SmallIntegerField(choices=gender_choice,default=3)
#DateField
日期字段,日期格式 YYYY-MM-MD,例如:2019-6-12,相当于Python中的datetime.date()实例。
#DateTimeField
日期格式字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例。 - 字段合集:
 字段合集
字段合集AutoField(Field) - int自增列,必须填入参数 primary_key=True BigAutoField(AutoField) - bigint自增列,必须填入参数 primary_key=True 注:当model中如果没有自增列,则自动会创建一个列名为id的列 from django.db import models class UserInfo(models.Model): # 自动创建一个列名为id的且为自增的整数列 username = models.CharField(max_length=32) class Group(models.Model): # 自定义自增列 nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) SmallIntegerField(IntegerField): - 小整数 -32768 ~ 32767 PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) - 正小整数 0 ~ 32767 IntegerField(Field) - 整数列(有符号的) -2147483648 ~ 2147483647 PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) - 正整数 0 ~ 2147483647 BigIntegerField(IntegerField): - 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807 BooleanField(Field) - 布尔值类型 NullBooleanField(Field): - 可以为空的布尔值 CharField(Field) - 字符类型 - 必须提供max_length参数, max_length表示字符长度 TextField(Field) - 文本类型 EmailField(CharField): - 字符串类型,Django Admin以及ModelForm中提供验证机制 IPAddressField(Field) - 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制 GenericIPAddressField(Field) - 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6 - 参数: protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6" unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启此功能,需要protocol="both" URLField(CharField) - 字符串类型,Django Admin以及ModelForm中提供验证 URL SlugField(CharField) - 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号) CommaSeparatedIntegerField(CharField) - 字符串类型,格式必须为逗号分割的数字 UUIDField(Field) - 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证 FilePathField(Field) - 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能 - 参数: path, 文件夹路径 match=None, 正则匹配 recursive=False, 递归下面的文件夹 allow_files=True, 允许文件 allow_folders=False, 允许文件夹 FileField(Field) - 字符串,路径保存在数据库,文件上传到指定目录 - 参数: upload_to = "" 上传文件的保存路径 storage = None 存储组件,默认django.core.files.storage.FileSystemStorage ImageField(FileField) - 字符串,路径保存在数据库,文件上传到指定目录 - 参数: upload_to = "" 上传文件的保存路径 storage = None 存储组件,默认django.core.files.storage.FileSystemStorage width_field=None, 上传图片的高度保存的数据库字段名(字符串) height_field=None 上传图片的宽度保存的数据库字段名(字符串) DateTimeField(DateField) - 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ] DateField(DateTimeCheckMixin, Field) - 日期格式 YYYY-MM-DD TimeField(DateTimeCheckMixin, Field) - 时间格式 HH:MM[:ss[.uuuuuu]] DurationField(Field) - 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型 FloatField(Field) - 浮点型 DecimalField(Field) - 10进制小数 - 参数: max_digits,小数总长度 decimal_places,小数位长度 BinaryField(Field) - 二进制类型
ORM字段与MySQL字段对应关系对应关系: 'AutoField': 'integer AUTO_INCREMENT', 'BigAutoField': 'bigint AUTO_INCREMENT', 'BinaryField': 'longblob', 'BooleanField': 'bool', 'CharField': 'varchar(%(max_length)s)', 'CommaSeparatedIntegerField': 'varchar(%(max_length)s)', 'DateField': 'date', 'DateTimeField': 'datetime', 'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)', 'DurationField': 'bigint', 'FileField': 'varchar(%(max_length)s)', 'FilePathField': 'varchar(%(max_length)s)', 'FloatField': 'double precision', 'IntegerField': 'integer', 'BigIntegerField': 'bigint', 'IPAddressField': 'char(15)', 'GenericIPAddressField': 'char(39)', 'NullBooleanField': 'bool', 'OneToOneField': 'integer', 'PositiveIntegerField': 'integer UNSIGNED', 'PositiveSmallIntegerField': 'smallint UNSIGNED', 'SlugField': 'varchar(%(max_length)s)', 'SmallIntegerField': 'smallint', 'TextField': 'longtext', 'TimeField': 'time', 'UUIDField': 'char(32)',
- 字段参数:
#null :用于表示某个字段可以为空
#unique :如果设置为unique = True 则该字段在此表中必须是唯一的
# db_index :如果db_index = True 则代表着为此字段设置索引
# default :为该字段设置默认值 - DateField和DateTimeField:
#auto_now_add
配置auto_now_add = True,创建数据记录的时候会把当前时间添加到数据库,后续操作数据不自动更新
#auto_now
配置上auto_now = True,每次更新数据记录的时候会更新该字段 - 关系字段:
#①ForeignKey
外键类型在ORM中用表示外键关联关系,一般吧ForeignKey字段设置在‘一段多’中的多的一方,ForeignKey可以和其它表做关联关系同时也可以和自身做关联关系。
#字段参数:
##to 设置要关联的表
##to_field 设置要关联的表的字段
##on_delete 当删除关联表中的数据时,当前表与其关联的行的行为
models.CASCADE (Django2.x版本必须要设置,1.x版本默认就设置了)
删除关联数据,与之关联也删除
##db_constraint 是否在数据库中创建外键约束,默认为True
其余字段参数models.DO_NOTHING 删除关联数据,引发错误IntegrityError models.PROTECT 删除关联数据,引发错误ProtectedError models.SET_NULL 删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空) models.SET_DEFAULT 删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值) models.SET 删除关联数据, a. 与之关联的值设置为指定值,设置:models.SET(值) b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)示例:
def func(): return 10 class MyModel(models.Model): user = models.ForeignKey( to="User", to_field="id", # 不写默认关联对方关联表的primary_key on_delete=models.SET(func) )
#②OneToOneField
#字段参数:
一对一字段
通常一对一字段用来扩展已有字段。(通俗的说就是一个人的所有信息不是放在一张表里面的,简单的信息一张表,隐私的信息另一张表,之间通过一对一外键关联)
##to 设置要关联的表
##to_field 设置要关联的表的字段
##on_delete 当删除关联表中的数据时,当前与其关联的行的行为(参考ForeignKey)
#③ManyToManyField
多对多字段
#字段参数:
##to 设置要关联的表
##to_field 设置要关联的表的字段
##on_delete 当删除关联表中的数据时,当前与其关联的行的行为(参考ForeignKey)
例子分别以图书管理系统的Book、Publish、Author三张表直接的关系来举例 from django.db import models class Book(models.Model): title = models.CharField(max_length=32) price = models.DecimalField(max_digits=6, decimal_places=1) publish = models.ForeignKey(to='Publish') author = models.ManyToManyField(to='Author') class Publish(models.Model): name = models.CharField(max_length=32) email = models.CharField(max_length=32) class Author(models.Model): name = models.CharField(max_length=32) age = models.IntegerField(default=18)

二、单表查询
- 准备
为了更方便的测试表查询的结果,我们需要先配置一下参数,可以是我们直接在Django页面中运行我们的测试表查询代码,快速显示结果,所以需要做如下操作:
项目根目录创建一个test.py测试文件>>>>在项目的manage.py文件中复制一段代码>>>>将复制的代码粘贴到test.py文件中,然后再加入几段代码,这样就可以在test文件中进行数据库表数据操作了,当然,连接数据库的过程不能少,表的创建也是。
manage.py文件复制的代码: import os if __name__ == "__main__": os.environ.setdefault("DJANGO_SETTINGS_MODULE", "created_by_pycharm.settings") 添加的代码:(在main下面) import django django.setup() from app01 import models # 注意这句话必须在这里,不能放最上面
这里需要建一张表,用于单表查询:(models文件内)
from django.db import models # Create your models here. # 单表查询示例表 class User(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() register_time = models.DateField(auto_now_add=True)
项目settings里面将MySQL数据库连入: DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'orm_test', 'HOST': '127.0.0.1', 'PORT': 3306, 'USER': 'root', 'PASSWORD': '123', } } 同时不要忘了在项目程序文件夹中init文件添加代码: import pymysql pymysql.install_as_MySQLdb() 这样才代表数据库已经和Django项目对接完毕
当然新建完要生效,需要进行数据库迁移(同步)操作 python3 manage.py makemigrations python3 manage.py migrate - 新增表数据
# 基于create创建 models.User.objects.create(name='sgt', age=18) # 基于对象的绑定方法创建 user_obj = models.User(name='王大锤', age=12) user_obj.save()
- 修改表数据
# 基于QuerySet models.User.objects.filter(name='ttt').update(age=100) # 基于对象 user_obj = models.User.objects.filter(name='sss').first() user_obj.age = 99 user_obj.save()
- 删除表数据
总结一下单表操作的一些方法:
# 基于QuerySet models.User.objects.filter(name='ggg').delete() # 基于对象 user_obj = models.User.objects.filter(name='ttt').first() user_obj.delete()
<1> all(): 查询所有的结果,返回QuerySet对象们的列表
res = models.User.objects.all() print(res) <QuerySet [<User: User object>, <User: User object>, <User: User object>, <User: User object>]>
<2> filter(**kwargs): 通过括号中的条件查询到匹配的对象,返回QuerySet对象们的列表
res = models.User.objects.filter(name='sgt') print(res) <QuerySet [<User: User object>, <User: User object>, <User: User object>]> 这里提一下:filter筛选条件是可以有多个的,多个条件是与关系,必须全部满足才会得到查询结果
<3> get(**kwargs): 返回与所给筛选条件匹配的object对象,且返回结果只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
res1 = models.User.objects.get(name='sgt') # app01.models.MultipleObjectsReturned: get() returned more than one User -- it returned 3! res2 = models.User.objects.get(name='孙悟空') # app01.models.DoesNotExist: User matching query does not exist. res3 = models.User.objects.get(name='王大锤') # User object
<4> exclude(**kwargs): 返回筛选条件不匹配的QuerySet对象们的列表(取反筛选)
res1 = models.User.objects.exclude(name='sgt') <QuerySet [<User: User object>, <User: User object>, <User: User object>]>
<5> order_by(*field): 对查询结果通过某一字段进行排序(默认升序),返回QuerySet对象们的列表
res1 = models.User.objects.filter(name='sgt').order_by('age') # 排序默认是升序,如果这里的age前加上一个负号‘-’,怎会进行降序排序。 # res1 = models.User.objects.filter(name='sgt').order_by('-age') print(res1) # <QuerySet [<User: User object>, <User: User object>, <User: User object>]> # 为了让结果更清晰,遍历下得到排好序的QuerySet对象们列表,以其age显示顺序 users = [] for user_obj in res1: users.append(user_obj.age) print(users) # [18, 22, 32]
<6> reverse(): 对查询的排序结果进行反向排列,记住,不是反向排序,而是反向排列,返回QuerySet对象们的列表
res1 = models.User.objects.filter(name='sgt').order_by('age').reverse() users = [] for user_obj in res1: users.append(user_obj.age) print(users) # 结果反过来排列了:[32, 22, 18]
<7> count(): QuerySet方法,返回查询到的QuerySet对象的数量,该方法只能对返回的查询结果为QuerySet对象使用,如果返回的对象是一个普通的对象,那么结果跟res3一样
res1 = models.User.objects.filter(name='sgt').count() print(res1) # 3 res2 = models.User.objects.filter(name='hahaha').count() print(res2) # 0 res3 = models.User.objects.get(name='王大锤').count() # 抛出错误:AttributeError: 'User' object has no attribute 'count'
<8> first(): 返回查询结果的第一个对象,返回一个普通对象(User object)
res = models.User.objects.filter(name='sgt').first() print(res) # User object
<9> last(): 返回查询结果的最后一个对象,返回一个普通对象(User object)
res = models.User.objects.filter(name='sgt').last() print(res) # User object
<10> exists(): QuerySet方法, 如果QuerySet包含数据,就返回True,否则返回False
res = models.User.objects.filter(name='sgt').exists() print(res) # True res = models.User.objects.filter(name='sgg').exists() print(res) # False
<11> values(*field): 返回一个特殊的QuerySet对象,对象里面是一个列表套字典(model的实例化对象,而是一个可迭代的字典序列)
res = models.User.objects.filter(name='sgt').values('age') print(res) print(res.order_by('age')) print(res.order_by('age').reverse()) print(res.count()) print(res[0]) print(res.first(), res.last()) <QuerySet [{'age': 18}, {'age': 32}, {'age': 22}]> # values方法返回结果 <QuerySet [{'age': 18}, {'age': 32}, {'age': 22}]> # 通过age来反向排列,无效,说明该方法只能用在order_by之后,才能进行反向排列 <QuerySet [{'age': 18}, {'age': 22}, {'age': 32}]> # order_by <QuerySet [{'age': 32}, {'age': 22}, {'age': 18}]> # order_by后再reverse 3 # 使用count方法 {'age': 18} # 可以用索引取出对应索引的字典 {'age': 18} {'age': 22} # 使用first和last方法
<12> values_list(*field): 它与values()非常相似,它返回的是一个元组序列的QuerySet对象
res = models.User.objects.filter(name='sgt').values_list('age') print(res) print(res.order_by('age')) print(res.order_by('age').reverse()) print(res.count()) print(res[0]) print(res.first(), res.last()) <QuerySet [(18,), (32,), (22,)]> <QuerySet [(18,), (22,), (32,)]> <QuerySet [(32,), (22,), (18,)]> 3 (18,) (18,) (22,) 结果和values方法差不多,只是把字典序列变成了元祖序列
<13> distinct(): 从返回结果中剔除重复纪录,注意必须是所有数据都相同才满足去重条件,但是一个表中的每一条数据是不会完全重复的,因为有primary_key的存在,就不会完全相同,所以此方法的主要是在上面的values和values_list方法的基础上用的话会实现一些我们想要的结果。返回特殊的QuerySet对象
res1 = models.User.objects.filter(name='sgt') res2 = models.User.objects.filter(name='sgt').distinct() print(res1) print(res2) # <QuerySet [<User: User object>, <User: User object>, <User: User object>, <User: User object>]> # <QuerySet [<User: User object>, <User: User object>, <User: User object>, <User: User object>]> # 结果数量不变,说明没有去重的项目,主要原因:id没有相同的,肯定无法去重
# 我们用values方法的基础上使用distinct方法: res1 = models.User.objects.filter(name='sgt').values('age') res2 = res1.distinct() print(res1) print(res2) # <QuerySet [{'age': 18}, {'age': 32}, {'age': 22}, {'age': 22}]> # <QuerySet [{'age': 18}, {'age': 32}, {'age': 22}]> # 发现这样去重的意义就出来了
- 只要是QuerySet对象都可以无线的点其中的方法,点下去...
-
基于双下划线的单表查询:

大于(__gt)、小于(__lt)、大于等于(__gte)、小于等于(__lte)
# 将结果再使用values方法,更直接显示 res1 = models.User.objects.filter(age__gt=12).values('name', 'age') print(res1) # <QuerySet [{'name': '王大锤', 'age': 18}, {'name': '王大炮', 'age': 66}, {'name': '黄飞鸿', 'age': 88}]> res2 = models.User.objects.filter(age__lt=12).values('name', 'age') print(res2) # <QuerySet [{'name': '米小圈', 'age': 8}, {'name': '铁头', 'age': 9}]> res3 = models.User.objects.filter(age__gte=12).values('name', 'age') print(res3) # <QuerySet [{'name': '王大锤', 'age': 18}, {'name': '佩奇', 'age': 12}, {'name': '王大炮', 'age': 66}, {'name': '黄飞鸿', 'age': 88}]> res4 = models.User.objects.filter(age__lte=12).values('name', 'age') print(res4) # <QuerySet [{'name': '米小圈', 'age': 8}, {'name': '铁头', 'age': 9}, {'name': '佩奇', 'age': 12}]>
包含(区分大小写__contains|不区分大小写__icontains),以xx开头(__startswith),以xx结尾(__endswith)
res1 = models.User.objects.filter(name__contains='i').values('name', 'age') print(res1) # <QuerySet [{'name': 'igon', 'age': 55}, {'name': 'igoN', 'age': 66}]> res2 = models.User.objects.filter(name__contains='N').values('name', 'age') print(res2) # <QuerySet [{'name': 'igoN', 'age': 66}]> res0 = models.User.objects.filter(name__icontains='j').values('name', 'age') print(res0) # <QuerySet [{'name': 'json', 'age': 11}, {'name': 'Jason', 'age': 16}]> res3 = models.User.objects.filter(name__startswith='j').values('name', 'age') print(res3) # <QuerySet [{'name': 'json', 'age': 11}]> res4 = models.User.objects.filter(name__endswith='t').values('name', 'age') print(res4) # <QuerySet [{'name': 'sgt', 'age': 18}]>
时间为2018年的记录:(__year=2017)
res = models.User.objects.filter(register_time__year=2018).values('name', 'age', 'register_time') print(res) # <QuerySet [{'name': 'json', 'age': 11, 'register_time': datetime.date(2018, 6, 21)}]>
在指定容器内__in=[a,b,c],在指定范围内__range=[m,n],首尾都包括在内
res1 = models.User.objects.filter(age__in=[66, 88]).values('name', 'age') print(res1) # <QuerySet [{'name': '王大炮', 'age': 66}, {'name': '黄飞鸿', 'age': 88}, {'name': 'igoN', 'age': 66}]> res2 = models.User.objects.filter(age__range=[9, 12]).values('name', 'age') print(res2) # <QuerySet [{'name': '铁头', 'age': 9}, {'name': '佩奇', 'age': 12}, {'name': 'json', 'age': 11}]>
三、多表查询
- 表与表之间的关系
#一对一(OneToOneField):一对一字段无论建在哪张关系表里面都可以,但是推荐建在查询频率比较高的那张表里面
#一对多(ForeignKey):一对多字段建在多的那一方
#多对多(ManyToManyField):多对多字段无论建在哪张关系表里面都可以,但是推荐建在查询频率比较高的那张表里面
多对多操作:
添加add(),
修改set(),
移除remove() 注意不能接收可迭代对象,
清空clear() 无需传参如何判断表与表之间到底是什么关系 换位思考 A能不能有多个B B能不能有多个A -
多表的增删改查:
======增删改:一对多======from django.db import models # 多表查询示例表 class Book(models.Model): title = models.CharField(max_length=32) price = models.DecimalField(max_digits=8, decimal_places=2) publish_date = models.DateField(auto_now_add=True) # 外键关系 # 一对多:(外键) publish = models.ForeignKey(to='Publish') # 多对多: author = models.ManyToManyField(to='Author') # 这是一个虚拟字段, 信号字段 class Publish(models.Model): name = models.CharField(max_length=32) addr = models.CharField(max_length=32) email = models.EmailField() # 对应的就是varchar类型 class Author(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() # 一对一关系 authordetail = models.OneToOneField(to='AuthorDetail') class AuthorDetail(models.Model): phone = models.CharField(max_length=32) addr = models.CharField(max_length=32)
Book与Publish 一对多关系
新增:
# 一对多新增: # 由于book表和Publish表示多对一的关系,所以我们需要先建立Publish相关数据才能进行book记录新增 models.Publish.objects.create(name='东方出版社', addr='北京', email='123@163.com') models.Publish.objects.create(name='西方出版社', addr='内蒙', email='456@163.com') models.Publish.objects.create(name='南方出版社', addr='武汉', email='789@163.com') models.Publish.objects.create(name='北方出版社', addr='上海', email='546@163.com')
# 新增book记录(直接添加写id) models.Book.objects.create(title='西游记', price=66, publish_id=1) models.Book.objects.create(title='红楼梦', price=266, publish_id=2) models.Book.objects.create(title='西厢记', price=166, publish_id=3) models.Book.objects.create(title='金屏梅', price=366, publish_id=4)
修改:# 一对多新增,传输数据对象 publish_obj = models.Publish.objects.filter(pk=1).first() models.Book.objects.create(title='三国志', price=48, publish=publish_obj)
删除:(默认情况下)# 一对多修改 # QuerySet方法修改 ① models.Book.objects.filter(pk=1).update(publish_id=2) ② publish_obj = models.Publish.objects.filter(pk=4).first() models.Book.objects.filter(pk=1).update(publish=publish_obj) # 对象方法修改 ① book_obj = models.Book.objects.filter(pk=1).first() book_obj.publish_id = 3 # 点表中真实存在的字段名 book_obj.save() ② book_obj = models.Book.objects.filter(pk=1).first() publish_obj = models.Publish.objects.filter(pk=1).first() book_obj.publish = publish_obj book_obj.save()
======增删改:多对多======# 多对一删除 ①QuerySet方法 # 当删除'多'的表数据,则那张'一'的表无影响 models.Book.objects.filter(pk=1).delete() # 当删除'一'的表数据,则那张'多'的表对应的记录会删除 models.Publish.objects.filter(pk=2).delete() ②对象方法: book_obj = models.Book.objects.filter(pk=2).first() book_obj.delete()
book与author表之间是多对多关系
新增
# 多对多关系表的新增 # 过程:先新增数据,后绑定关系 # 先新增author数据和book数据(假设作者信息已经存在对应Detail表) models.Author.objects.create(name='萧鼎', age=66, authordetail_id=1) models.Author.objects.create(name='路遥', age=56, authordetail_id=2) models.Author.objects.create(name='三毛', age=77, authordetail_id=3) models.Author.objects.create(name='金庸', age=95, authordetail_id=4) book_obj = models.Book.objects.create(title='画江湖', price=99, publish_id=1) book_obj.author.add(2, 3) 当然新增也支持传对象的方式 author_obj1 = models.Author.objects.filter(pk=1).first() author_obj2 = models.Author.objects.filter(pk=2).first() book_obj.author.add(author_obj1, author_obj2)
修改
删除:默认情况下删除一方表记录,连带的会删除其绑定关系,但是另一边记录无影响,仅仅是绑定关系没有了# 修改book和author记录及其关系:set()方法,必须传可迭代对象 book_obj = models.Book.objects.filter(pk=3).first() # 修改方法和新增类似,也是修改自身数据后再修改关系 # 可以传数字和对象,并且也支持传多个 # 传id book_obj.author.set((1,)) # 传一个 book_obj.author.set((1,2,3)) # 传多个 # 传对象 author_list = models.Author.objects.all() book_obj = models.Book.objects.filter(pk=3).first() book_obj.author.set(author_list)
# 多对多删除 # QuerySet方法 models.Book.objects.filter(pk=4).delete() # 删除id为4的书,同时会自动删除此书与作者之间的关系,此时绑定关系会自动删除 # 对象方法 book_obj = models.Book.objects.filter(pk=5).first() book_obj.author.remove(2) # 先删除关系不会删除book记录数据 book_obj = models.Book.objects.filter(pk=6).first() book_obj.delete() # 删除book对象,会自动触发删除绑定关系 # 假设一本书有多个作者 book_obj = models.Book.objects.filter(pk=1).first() author_list = models.Author.objects.all() book_obj.author.remove(*author_list) # 注意这里的QuerySet需要打散才行
======增删改:一对一======
删除:新增:# 一对一,author表创建外键绑定关系到authordetail表,删除创建外键的那张author表的记录,另一方无影响 models.Author.objects.filter(pk=1).delete() # 一对一,删除非外键的那张authordetail表记录,则绑定关系以及对应的author表记录都会随之删除 models.AuthorDetail.objects.filter(pk=2).delete()
修改:# 一对一新增:创建外键的表author中新增记录,对应的外键必须未用占且存在,因为是一对一关系,否则报错 models.Author.objects.create(name='王锤', age=88, authordetail_id=1) # 一对一新增,authordetail表中新增记录,author表无影响. models.AuthorDetail.objects.create(phone='123', addr='毛里求斯')
# 一对一修改, models.Author.objects.filter(pk=8).update(name='汤勺') models.AuthorDetail.objects.filter(pk=4).update(addr='伊拉克') # 一对一修改 关联外键值: # 外键值必须未占用,且存在,不然报错 models.Author.objects.filter(pk=8).update(authordetail_id=5)
======清空clear()======
book_obj = models.Book.objects.filter(pk=3).first() book_obj.authors.clear() # 清空当前书籍对应的所有作者的绑定关系
-
正向查询:通过一张表a查询另一张表b,如果a与b之间的关系外键是建在a中,那么我们从a中能通过这个外键字段查询到b表中的对应数据的过程就叫做正向查询
反向查询:上面的正向查询,如果从b表去找a表的数据,外键还是建在a表中,这时候b表中就没有与a表关联的字段,此时b查到a就需要用另外的手段来实现,这种就叫反向查询
正向、反向查询方法:
原则:正向查询按字段,反向查询按表名小写# 一对一
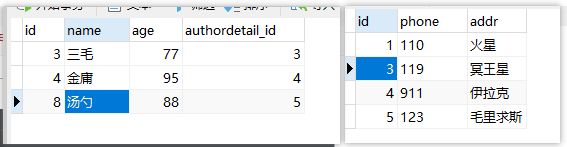
Author表和AuthorDetail表是一对一关系:(外键在Author表中)
## 正向查询:从Author查到AuthorDetail: res = models.Author.objects.filter(pk=3).first().authordetail.addr print(res) # 冥王星 ## 反向查询:从AuthorDetail 查到Author res1 = models.AuthorDetail.objects.filter(pk=3).first().author.name print(res1) # 三毛
# 一对多

# Book到Publish res = models.Book.objects.filter(pk=1).first().publish.name print(res) # 东方出版社 # Publish到Book res1 = models.Publish.objects.filter(pk=2).first().book_set.all() print(res1) # <QuerySet [<Book: Book object>, <Book: Book object>]> res2 = models.Publish.objects.filter(pk=2).first().book_set.all().values('title') print(res2) # <QuerySet [{'title': '红楼梦'}, {'title': '西游记'}]>
# 多对多

# 正向查询 res1 = models.Book.objects.filter(pk=2).first().author.all() print(res1) # <QuerySet [<Author: Author object>, <Author: Author object>]> res2 = models.Book.objects.filter(pk=2).first().author.all().values('name') print(res2) # <QuerySet [{'name': '金庸'}, {'name': '汤勺'}]> # 反向查询 res3 = models.Author.objects.filter(pk=3).first().book_set.all() print(res3) # <QuerySet [<Book: Book object>, <Book: Book object>]> res4 = models.Author.objects.filter(pk=3).first().book_set.all().values('title') print(res4) # <QuerySet [{'title': '西厢记'}, {'title': '红楼梦'}]>
规律:一对多、多对多 反向查询的时候要加_set.all()
一对一 反向查询不用加 -
基于双下划线的多表查询
- 用例子来说明:
① 查询书籍为红楼梦的出版社名:res = models.Book.objects.filter(title='红楼梦').values('publish__name') print(res) # <QuerySet [{'publish__name': '南方出版社'}]>
② 查询书籍为西游记的作者的姓名:
res = models.Book.objects.filter(title='西游记').values('author__name') print(res) # <QuerySet [{'author__name': '三毛'}, {'author__name': '唐唐'}]>
③ 查询南方出版社初版的书名:
res = models.Publish.objects.filter(name='南方出版社').values('book__title') print(res) # <QuerySet [{'book__title': '红楼梦'}, {'book__title': '西游记'}]>
④ 查询电话号码是911的作者写的书名:
res = models.AuthorDetail.objects.filter(phone='911').values('author__book__title') print(res) # <QuerySet [{'author__book__title': '三国志'}, {'author__book__title': '西厢记'}]>
⑤ 查询作者名字为金庸写的书的书名:
res = models.Author.objects.filter(name='金庸').values('book__title') print(res) # <QuerySet [{'book__title': '三国志'}, {'book__title': '西厢记'}]>
⑥ 查询书籍为西游记的作者的电话号码:
res = models.Book.objects.filter(title='西游记').values('author__name', 'author__authordetail__phone') print(res) # <QuerySet [{'author__name': '三毛', 'author__authordetail__phone': '119'}, # {'author__name': '唐唐', 'author__authordetail__phone': '110'}]>
⑦ 通过作者细节表 查询作者叫金庸的电话号码
res = models.AuthorDetail.objects.filter(author__name='金庸').values('phone') print(res) # <QuerySet [{'phone': '911'}]>
⑧ 从书这张表 查询出版社为南方出版社的所有图书的名字和价格
res = models.Book.objects.filter(publish__name='南方出版社').values('title', 'price') print(res) # <QuerySet [{'title': '红楼梦', 'price': Decimal('67.00')}, {'title': '西游记', 'price': Decimal('87.00')}]>
⑨ 查询东方出版社初版的书的价格大于45的书
res = models.Publish.objects.filter(name='东方出版社', book__price__gt=45).values('book__title', 'book__price') print(res) # <QuerySet [{'book__title': '三国志', 'book__price': Decimal('48.00')}]>
四、聚合查询和分组查询
- 聚合查询
aggregate(),它是QuerySet的一个终止子句,意思就是,会返回一个包含一些键值对的字典
键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的
用到的内置函数:from django.db.models import Avg, Sum, Max, Min, Count
示例:
from django.db.models import Avg,Sum,Max,Min,Count、 查询所有书籍的平均价格,最大价格,书的数量 res = models.Book.objects.all().aggregate(Avg('price'), Max('price'), Count('title')) print(res) # {'price__avg': 56.6, 'price__max': Decimal('87.00'), 'title__count': 5}
可以给聚合值指定一个名称,用于使用该聚合值
如果你想要为聚合值指定一个名称,可以向聚合子句提供它。 >>> models.Book.objects.aggregate(average_price=Avg('price')) {'average_price': 13.233333}
- 分组查询
示例:
统计每一个出版社的出版的书平均价格res = models.Publish.objects.annotate(avg_price=Avg('book__price')).values('name', 'avg_price') print(res) # <QuerySet [{'name': '东方出版社', 'avg_price': 46.0}, {'name': '南方出版社', 'avg_price': 77.0}, {'name': '北方出版社', 'avg_price': 37.0}]>

统计出每个出版社买的最便宜的书的价格# <QuerySet [{'name': '东方出版社', 'avg_price': 46.0}, {'name': '南方出版社', 'avg_price': 77.0}, {'name': '北方出版社', 'avg_price': 37.0}]> res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name', 'min_price' ) print(res) # <QuerySet [{'name': '东方出版社', 'min_price': Decimal('44.00')}, {'name': '南方出版社', 'min_price': Decimal('67.00')}, {'name': '北方出版社', 'min_price': Decimal('37.00')}]>
统计不止一个作者的图书
res = models.Book.objects.annotate(author_num=Count('author')).filter(author_num__gt=1).values('title') print(res) # <QuerySet [{'title': '西厢记'}]>
原文链接:https://www.cnblogs.com/suguangti/p/11011062.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- Django项目中使用qq第三方登录。 2019-08-13
- 使用scrapy框架爬取全书网书籍信息。 2019-08-13
- Django和前端用ajax传输json等数据 2019-08-13
- 网络编程相关知识点 2019-08-13
- Django基本知识 2019-08-13
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
