
python算法与数据结构-数据结构中常用树的介绍(4…
2019-07-24 09:13:56来源:博客园 阅读 ()

一、树的定义
树是一种非线性的数据结构,是由n(n >=0)个结点组成的有限集合。
如果n==0,树为空树。
如果n>0,
树有一个特定的结点,根结点
根结点只有直接后继,没有直接前驱。
除根结点以外的其他结点划分为m(m>=0)个互不相交的有限集合,T0,T1,T2,...,Tm-1,每个结合是一棵树,称为根结点的子树。
- 树(tree):是以边(edge)相连的结点(node)的集合,每个结点存储对应的值(value/data),当存在子结点时与之相连。
- 根节点(root):是树的首个结点,在相连两结点中更接近根结点的成为父结点(parent node),相应的另一个结点称为子结点(parent node)。
- 边(edge):所有结点都由边相连,用于标识结点间的关系。边是树中很重要的一个概念,因为我们用它来确定节点之间的关系。
- 叶子节点(Leaves):是树的末端结点,他们没有子结点,就像真实的树那样 ,由根开始,伸展枝干,到叶为止。
- 树高(height):是由根结点出发,到子结点的最长路径长度。
- 节点深度(depth):是指对应结点到根结点路径长度。

二、二叉树介绍
二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)
二叉树的性质(特性)
性质1: 在二叉树的第i层上至多有2^(i-1)个结点(i>0)
性质2: 深度为k的二叉树至多有2^k - 1个结点(k>0)
性质3: 对于任意一棵二叉树,如果其叶结点数为N0,而度数为2的结点总数为N2,则N0=N2+1;
性质4: 具有n个结点的完全二叉树的深度必为 log2(n+1)
性质5:对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲的编号必为i/2(i=1 时为根,除外)
三、完全二叉树介绍
完全二叉树——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。

四、满二叉树介绍
满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。满二叉树:每一层都挂满了节点
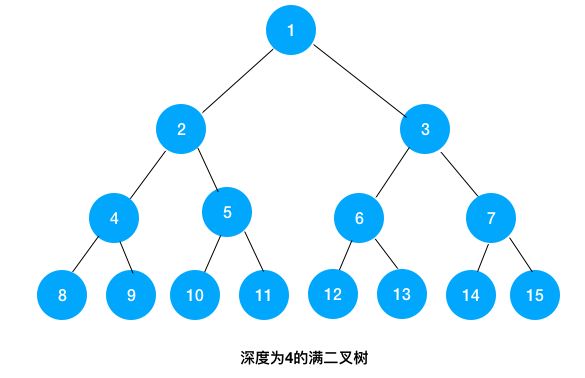
五、平衡二叉树(AVL树)介绍
AVL树本质上是一颗二叉查找树,但是它又具有以下特点:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。在AVL树中任何节点的两个子树的高度最大差别为一,所以它也被称为平衡二叉树。

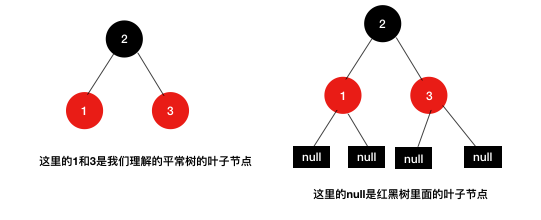
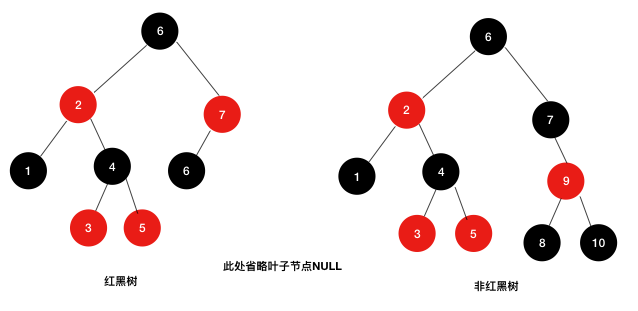
六、红黑树介绍
红黑树是一种平衡二叉树,在平衡二叉树的基础上每个节点又增加了一个颜色的属性,节点的颜色只能是红色或黑色,其每个结点满足以下条件:
- 每个结点都有颜色(黑或红);
- 根结点总是黑色;
- 不存在两个相邻的红色结点(一个红色结点不能有红色的父结点或者红色子女结点);
- 从根到空节点的每条路径都有相同数量的黑色节点。
- 每个叶结点(NULL)是黑色的
七、霍夫曼树
霍夫曼树是二叉树的一种特殊形式,又称为最优二叉树,其主要作用在于数据压缩和编码长度的优化。
7.1、路径和路径长度
在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。

7.2结点的权及带权路径长度
若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
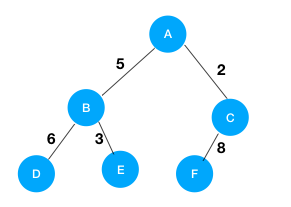
7.3树的带权路径长度
所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度。树的带权路径长度记为WPL= (W1*L1+W2*L2+W3*L3+...+Wn*Ln)。上图中的WPL = 6*2+3*2+8*2 = 34
7.4霍夫曼树的构造
给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为霍夫曼树(Huffman Tree)。例如:给定3课二叉树,都有4个叶子节点,A,B,C,D,分别带权7,5,2,4,求他们的带全路径长度。
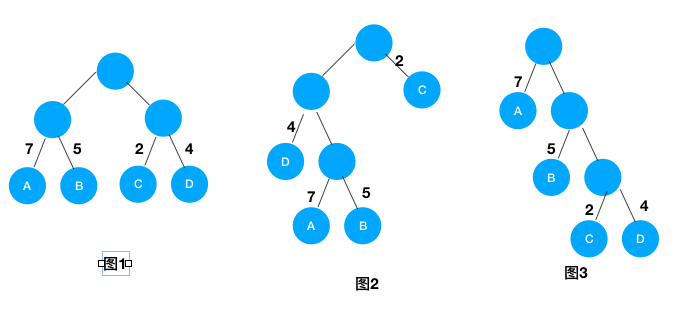
WPL1 = 7*2+5*2+2*2+4*2 = 36
WPL2 = 7*3+5*3+2*1+4*2 = 46
WPL3 = 7*1+5*2+2*3+4*3 = 35
八、B树介绍
B树也是一种用于查找的平衡树,但是它不是二叉树。
B树的定义:B树(B-tree)是一种树状数据结构,能够用来存储排序后的数据。这种数据结构能够让查找数据、循序存取、插入数据及删除的动作,都在对数时间内完成。B树,概括来说是一个一般化的二叉查找树,可以拥有多于2个子节点。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。这种数据结构常被应用在数据库和文件系统的实作上。
在B树中查找给定关键字的方法是,首先把根结点取来,在根结点所包含的关键字K1,…,Kn查找给定的关键字(可用顺序查找或二分查找法),若找到等于给定值的关键字,则查找成功;否则,一定可以确定要查找的关键字在Ki与Ki+1之间,Pi为指向子树根节点的指针,此时取指针Pi所指的结点继续查找,直至找到,或指针Pi为空时查找失败。
B树作为一种多路搜索树(并不是二叉的):
1) 定义任意非叶子结点最多只有M个儿子;且M>2;
2) 根结点的儿子数为[2, M];
3) 除根结点以外的非叶子结点的儿子数为[M/2, M];
4) 每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5) 非叶子结点的关键字个数=指向儿子的指针个数-1;
6) 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7) 非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8) 所有叶子结点位于同一层;
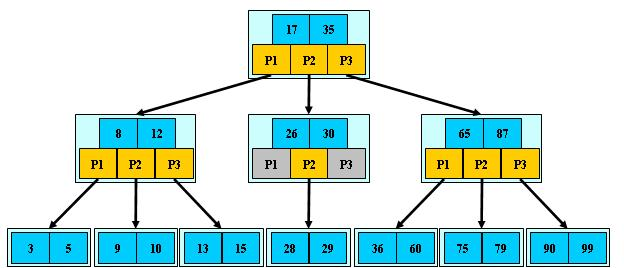
如下图为一个M=3的B树示例:
B树也是一种用于查找的平衡树,但是它不是二叉树。
B树的定义:B树(B-tree)是一种树状数据结构,能够用来存储排序后的数据。这种数据结构能够让查找数据、循序存取、插入数据及删除的动作,都在对数时间内完成。B树,概括来说是一个一般化的二叉查找树,可以拥有多于2个子节点。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。这种数据结构常被应用在数据库和文件系统的实作上。
在B树中查找给定关键字的方法是,首先把根结点取来,在根结点所包含的关键字K1,…,Kn查找给定的关键字(可用顺序查找或二分查找法),若找到等于给定值的关键字,则查找成功;否则,一定可以确定要查找的关键字在Ki与Ki+1之间,Pi为指向子树根节点的指针,此时取指针Pi所指的结点继续查找,直至找到,或指针Pi为空时查找失败。
B树作为一种多路搜索树(并不是二叉的):
1) 定义任意非叶子结点最多只有M个儿子;且M>2;
2) 根结点的儿子数为[2, M];
3) 除根结点以外的非叶子结点的儿子数为[M/2, M];
4) 每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5) 非叶子结点的关键字个数=指向儿子的指针个数-1;
6) 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7) 非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8) 所有叶子结点位于同一层;
如下图为一个M=3的B树示例:
九、B+树介绍
B+树是B树的变体,也是一种多路搜索树:
1) 其定义基本与B-树相同,除了:
2) 非叶子结点的子树指针与关键字个数相同;
3) 非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
4) 为所有叶子结点增加一个链指针;
5) 所有关键字都在叶子结点出现;
下图为M=3的B+树的示意图:
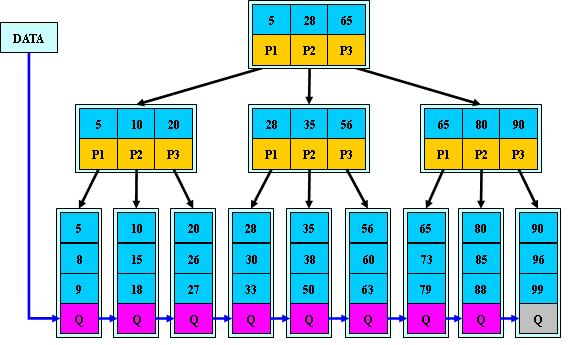
B+树的搜索与B树也基本相同,区别是B+树只有达到叶子结点才命中(B树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的性质:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统。
十、B*树介绍
B*树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针,将结点的最低利用率从1/2提高到2/3。
B*树如下图所示:
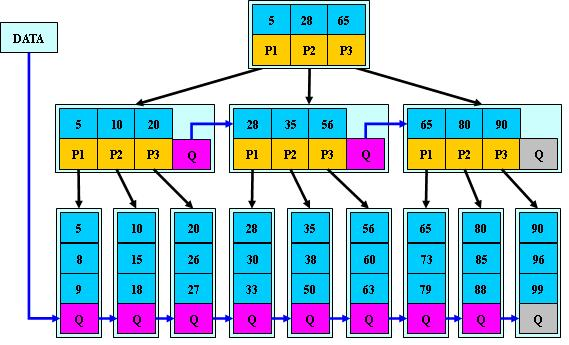
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高。
十一、Trie树
Tire树称为字典树,又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
Tire树的三个基本性质:
1) 根节点不包含字符,除根节点外每一个节点都只包含一个字符;
2) 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
3) 每个节点的所有子节点包含的字符都不相同。
Tire树的应用:
1) 串的快速检索
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
在这道题中,我们可以用数组枚举,用哈希,用字典树,先把熟词建一棵树,然后读入文章进行比较,这种方法效率是比较高的。
2) “串”排序
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出。用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可。
3) 最长公共前缀
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为求公共祖先的问题。
原文链接:https://www.cnblogs.com/Se7eN-HOU/p/11132082.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- python3基础之“术语表(2)” 2019-08-13
- python3 之 字符串编码小结(Unicode、utf-8、gbk、gb2312等 2019-08-13
- Python3安装impala 2019-08-13
- 小白如何入门 Python 爬虫? 2019-08-13
- python_字符串方法 2019-08-13
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
