21个必知的机器学习开源工具,涵盖5大领域
2019-11-20 来源:raincent

本文将介绍21个你可能没使用过的机器学习开源工具。
每个开源工具都为数据科学家处理数据库提供了不同角度。
本文将重点介绍五种机器学习的工具——面向非程序员的工具(Ludwig、Orange、KNIME)、模型部署(CoreML、Tensorflow.js)、大数据(Hadoop、Spark)、计算机视觉(SimpleCV)、NLP(StanfordNLP)、音频和强化学习(OpenAI Gym)。

你肯定已经知道一些知名的开源工具,如R、Python、Jupyter笔记本等。但除此之外,还有一个世界——一个在雷达下机器学习工具存在的世界。它们虽没有那些知名的开源工具出色,但却可以帮助用户解决许多机器学习的任务。
开源机器学习工具可分为以下5类:
1. 面向非程序员的开源机器学习工具
对于没有编程背景和技术背景的人来说,机器学习似乎很复杂。这是一个广阔的领域,可以想象,初次接触机器学习有多令人害怕。一个没有编程经验的人能在机器学习领域获得成功吗?
事实证明,能获得成功!以下三种工具可以帮助非程序员跨越技术鸿沟,进入声名鹊起的机器学习世界:
· Uber Ludwig:Uber’s Ludwig是一个建立在TensorFlow上的工具箱。Ludwig允许用户训练和测试深度学习模型,而不需要编写代码。用户需要提供的只是一个包含数据的CSV文件,一个用作输入的列表,以及一个用作输出的列表——而剩下工作将由Ludwig来完成。它对实验非常有用,因为用户只需耗费很少的时间和精力,就能构建复杂的模型。并且用户可以对其进行调整和处理之后再决定是否要将其运用在代码中。
· KNIME:KNIME可供用户使用拖放界面创建整个数据科学工作流。用户可以基本实现从功能工程到功能选择的所有功能,甚至可以通过这种方式将预测机器学习模型纳入工作流程中。这种可视化执行整个模型工作流的方法非常直观,并且在处理复杂的问题时非常有用。

· Orange:用户不必知道如何编写代码以使用orange来挖掘数据、处理数字以及由此得出自己的见解。相反,用户可执行基本可视化、数据操作、转换和数据挖掘等任务。由于Orange的易用性及其添加多个附加组件以补充其功能的能力,该工具最近在学生和教师中十分流行。
还有许多更有趣、免费的开源软件可以提供很好的机器学习功能,而无需编写(大量)代码。
此外,一些付费服务也可以考虑,如Google AutoML、 Azure Studio、 Deep Cognition和 Data Robot.
2. 旨在部署模型的开源机器学习工具
部署机器学习模型是一个十分重要但最容易被忽视的任务,用户应该加以注意。它肯定会出现在面试中,所以用户需很好地了解这个话题。
以下四种工具可以使用户更易将其项目运用到现实设备上。
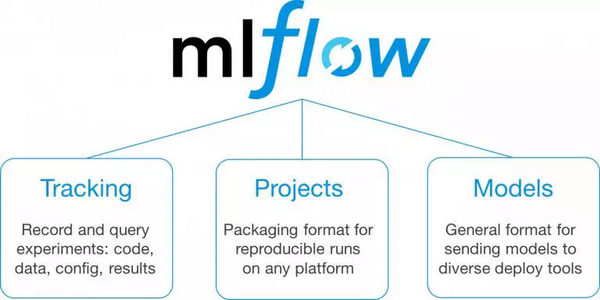
· MLFlow: MLFlow旨在与机器学习库或算法配合使用,并管理包括实验、再验和机器学习模型部署在内的整个生命周期。目前,MLFlow在Alpha中有3个部分——跟踪、项目和模型。
· Apple’s CoreML: CoreMLl是一个十分受欢迎的工具,它可将机器学习模型内置到用户的iOS/Apple Watch/Apple TV/MacOS的应用程序中。CoreML的闪光点在于用户无需对神经网络或机器学习有广泛的了解,最终达到双赢的结果!

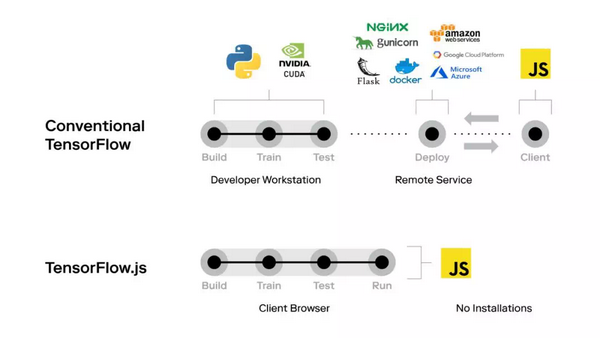
· TensorFlow Lite: TensorFlow Lite是一套帮助开发人员在移动设备(Android和iOS)和物联网设备上运行TensorFlow模型的工具,旨在方便开发人员在网络“边缘”的设备上进行机器学习,而不是从服务器来回发送数据。
· TensorFlow.js :TensorFlow.js是用户在网上部署机器学习模型的首选。这是一个开放源码库,供用户在浏览器中构建和处理机器学习模型。它可为GPU加速,还自动支持WebGL。用户可以导入现有的预培训模型,也可以在浏览器上重新处理整个现有机器学习模型!
3. 大数据开源机器学习工具
大数据是一个研究如何进行分析、如何系统地从数据集中提取信息或以其他方式处理传统数据处理软件无法处理的太大或太复杂的数据集的领域。想象一下,每天处理数百万条推特进行情绪分析。这感觉像是一项艰巨的任务,不是吗?
放宽心!以下三种工具可以帮助用户处理大数据。
· Hadoop: Hadoop是处理大数据最杰出也是最相关的工具之一。Hadoop允许用户使用简单的编程模型在计算机集群之间对大型数据集进行分布式处理。它旨在对单个服务器到数千台机器,每台机器都提供本地计算和存储。

· Spark: Apache spark被认为在大数据应用程序方面是Hadoop的进阶版。Apache spark的关键在于填补了Apache Hadoop在数据处理方面的空白。有趣的是,Spark可以同时处理批量数据和实时数据。
· Neo4j: 在处理大数据相关问题方面,Hadoop可能不是绝佳的选择。例如,用户需要处理大量的网络数据或图形相关问题(如社交网络或人口统计模式等)时。而图形数据库(Neo4j)则是最佳选择。
4. 用于计算机视觉、自然语言处理和音频的开源机器学习工具
· SimpleCV: 参与任何计算机视觉项目都必须使用OpenCV。但你有没有考虑过SimpleCV?SimpleCV可供用户访问几个高性能的计算机视觉库,如OpenCV——而不必首先了解位深度、文件格式、颜色空间、缓冲区管理、特征值以及矩阵与位图存储。计算机视觉让项目变得更容易上手。

· Tesseract OCR: 你是否曾使用过一些有创意的应用程序,可以使用智能手机的摄像头扫描文件或购物账单,或者只需拍张支票就可以将钱存入银行账户?所有这些应用程序使用的都是OCR,即光学字符识别软件。Tesseract就是这样的OCR引擎,可以识别100多种语言,也可以加以训练识别其他语言。
· Detectron: Detectron是Facebook旗下人工智能研究公司的软件系统,它采用了包括Mask R-CNN在内最先进的目标检测算法。Detectron由Python语言编写完成,由Caffe2深度学习框架提供支持。

· StanfordNLP: StanfordNLP是Python的自然语言分析包。它的闪光点在于其支持70多种人类语言!StanfordNLP还包含可以在以下程序步骤中使用的工具:
—将包含人类语言文本的字符串转换为句子和单词列表
—生成单词的基本形式、词类和形态特征
—逻辑句法结构依赖分析

· BERT as a Service: 所有的自然语言处理爱好者都应该听说过谷歌的开创性自然语言处理架构——BERT,但可能还没有用过。Bert-as-a-service将BERT作为句子编码器,并通过ZeroMQ将其作为服务器,从而使用户能够仅用两行代码将句子映射为固定长度的表示形式。
· Google Magenta: Google Magenta提供了处理源数据(主要是音乐和图像)的实用程序,该数据库使用这些源数据处理机器学习模型,并最终从这些模型中生成新内容。
· LibROSA: LibROSA是用于音乐和音频分析的Python语言包。它提供了构建音乐信息检索系统所必需的构建块。当用户在处理诸如语音到文本深度学习等的应用时, LibROSA广泛应用于在音频信号预处理程序环节。
5. 旨在进行强化学习的开源工具
强化学习(RL) 是机器学习的新话题,其目标是培养能够与环境互动并解决复杂任务的智能经纪人,实现机器人、自动驾驶汽车等的实际应用。
强化学习领域的快速发展得益于让智能经纪人玩一些游戏,如经典的Atari console games、传统的围棋游戏,或者让智能经纪人玩电子游戏,如Dota 2 或 Starcraft 2,所有这些游戏都为智能经纪人提供了具有挑战性的环境。在这个环境中,新的算法可以安全、可重复的方式测试想法。以下列举了4个最有利于强化学习的培养环境:
· Google Research Football: Google Research Football Environment是一个全新的强化学习环境,其中,智能经纪人旨在掌握世界上最流行的足球运动。这种环境能让用户更好地训练强化学习智能经纪人。观看以下视频了解更多信息:
· OpenAI Gym: Gym是开发和比较强化学习算法的工具包,可支持教学经纪人从走路到玩乒乓球或弹球之类的游戏。从以下动图中可以看到一个正在学习走路的教学经纪人。

· Unity ML Agents: The Unity Machine Learning Agents Toolkit(ML-Agents)是开源设备的插件,使游戏和模拟游戏能为智能经纪人训练提供有效环境。通过简单易用的Python API,用户可以使用强化学习、模仿学习、神经进化或其他机器学习方法来训练智能经纪人。

· Project Malmo: Malmo平台是一个建立在Minecraft之上的复杂人工智能实验平台,旨在支持人工智能领域的基础研究,由微软开发。
当用户进行数据科学和人工智能相关项目时,开放源码是一种可行的方法。本文只是介绍了冰山一角,仍有许多工具可用于处理各种各样的任务,使数据科学家的项目生活更为简便。数据科学家只需知道何处寻找开放源码即可。
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点!
本站所提供的图片等素材,版权归原作者所有,如需使用,请与原作者联系。

