
sql优化
2019-07-24 09:02:54来源:博客园 阅读 ()

在我们实际工作中大部分人会遇到sql优化的问题,这篇文章主要介绍SQL优化相关。首先我们怎么发现我们的sql执行效率低呢,最简单的方法就是当用户反馈慢的时候我们就会知道哪里可能会有sql效率影响的问题,这里排除其他影响情况,只考虑数据库sql慢的问题。当然这种方式对于我们来说很被动,我们还可以通过什么方式找到有性能问题sql,我们可以通过MySQL的配置文件来开启慢查询日志,我们可以设置slow_query_log=on,因为MySQL默认是不开启,如果MySQL是运行状态的MySQL可以使用set global命令来启动,我们还可以指定日志文件路径slow_query_log_file,如果不设置默认在MySQL数据目录中,除了文件路径,我们还可以设置记录sql执行时间的伐值long_query_time,可以精确的毫秒级别,但是他的单位是秒,如果不设置默认为10s,log_queries_not_using_indexes配置会记录未使用索引的sql,因为我们知道索引的建立会占用一定的磁盘空间,对添加修改删除也会有影响,如果一个索引的建立一直未被使用,我们可以对其进行分析,是重复索引了还是冗余了等问题,关于MySQL的配置文件的详细配置可以自行查阅资料,MySQL配置位置文件的位置在linux服务器我也就不多去介绍了,对于使用docker镜像安装的MySQL可以指定外挂我们自己的配置文件。MySQL的慢查询日志可能会记录很多,我们肉眼去看可能不是特别现实,我们可以借助慢查询日志分析工具,例如MySQL官方推荐的mysqldumpslow,在MySQL服务器自带mysqldumpslow工具,可以直接使用。我们除了可以通过日志记录的方式查看也可以通过语句实时查询有幸能问题的sql。

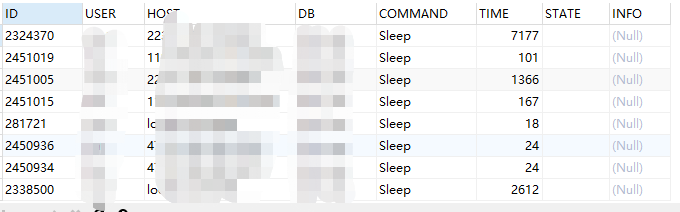
我们可以获取到进程id,用户,ip,使用的数据库,语句,时间等。我们在进行sql分析前先来了解一下怎么查看sql的执行计划,执行计划的每个参数又是什么意思呢?我们继续向下看。
什么是sql的执行计划,他就像一份体检报告,这份报告告诉你没想参数的结果。我们通过EXPLAIN来查看我们的sql执行的情况,贴个图


这是一个很简单的sql两个表关联查询通过where子查询作为条件,从第一个列来看,有1跟2,再看sql我们能看出来MySQL首先执行的应该是where条件里的子查询,通过id这列我们能看出来MySQL执行时id越大执行优先级越高,如果id相同则顺序执行。
第二列select_type查询类型。查询类型都有:
SIMPLE:简单查询,查询里没有子查询或者union
PRIMARY:查询包含嵌套查询,最外层查询的类型为PRIMARY
SUBQUERY:在SELECT或WHERE列表中包含了子查询,子查询的类型为SUBQUERY
DERIVED(衍生):在FROM列表中的子查询的类型为DERIVED,MySQL会将查询的结果放在临时表中,我们上面写到的sql没有产生这个类型只需要将store写成子查询即可,我们就不做演示,我们的查询有的时候需要临时表他会加快我们的查询效率,但是临时表的数据量很大,它也会影响我们的查询效率,对于临时表我们后面会提到
UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在 FROM子句的子查询中,外层SELECT将被标记为:DERIVED
UNION RESULT:从UNION表获取结果的SELECT的类型为UNION RESULT
UNION跟UNION RESULT光看理论可能看不懂,举个例子


这样一看就明白了,出现在union后面的为union类型,而两个表合并的为union result类型
第三列看名字就知道他的意思是表
第四列表的分区(看下图),对于分区这里暂不介绍
第五列访问类型,常见的从低至高all,index,range,ref,eq_ref,const,system。当然system表里只有一行记录,实际业务表基本不会出现,可以忽略。
const:通常通过主键索引或者唯一索引进行查询,因为只需要匹配一行,所以很快。


eq_ref:通过主键或者唯一索引相等作为条件,对于每个索引只有唯一匹配,举个例子:

ref:查询的索引列查询出来的记录不唯一,没有唯一匹配,举个例子:

他跟eq_ref区别就在于一个是完全匹配,一个是查询的结果不唯一,所以前者更多用于主键索引或者唯一索引
range:范围索引,通过'>','<',in,between,like





注意我们上篇文章提到不是所有的like查询都会走索引
index:全索引扫描,我们知道索引的大小远小于数据的大小,即使是index他的查询效率也比全表扫描高很多

查询出来的列值在索引中不需要再去找到对应行的数据,也叫覆盖索引
all:全表扫描,这个很简单就不写例子了
第六列possible_keys可能用到的索引,当查询的列,多个索引列包含,会列出可能执行的索引
第七列key真正执行的索引如果该列为空可能是没有索引或者索引失效
第八列key_len索引的最大可能长度,越大代表查询用到的索引更多,但并非越大越好,在同样查询结果的情况下key_len越小越好


第九列ref查询中使用索引被用到的值或常量
第十列查询需要扫描的行,这恶值越小越好
第十一列代表查询的结果占扫描列的百分比,上图都是100,这里不做介绍
第十二列额外重要的信息,先把比较重要的放到前面说
Using index代表我们查询用到了索引
Using temporary代表我们的查询通过临时表存储,相当于创建一张表然后将数据复制进去比较出结果后邮件临时表删除,这样的索引使也会严重影响查询效率,最常见用于分组或者排序,举个例子,创建的索引如下












还能举出例子的情况还有很多种,这里就不一一列举了,通过几个执行计划能看出来在我们查询时通过复合索引进行了分组的时候,当访问类型为ref级别的时候只有在复合索引跳过某个字段的时候会出现,在访问类型为range级别时,group by后面的字段必须按照符合索引的顺序,后面的可以缺失,第一个不能缺失,store_name,store_user_name,status|store_name,store_user_name|store_name不会出现Using temporary,store_user_name,status等都会出现Using temporary,因为range为范围查找,范围查找后的所有条件都失效,所以没有使用后面的索引。导致出现Using temporary
Using filesort代表MySQL无法通过索引进行排序,通过文件排序的的方式进行排序








几个例子发现它的出发条件跟上面的触发条件一样,同样排序没有通过索引的方式排序通过文件排序也是会影响查询效率的
Using where表示使用了where条件
Using join buffer使用了连接缓存
impossible where表示where的条件总是查询不出结果,我们的状态启用或者禁用,不可能一个店又是启用又是禁用

说了这么多,举几个例子来看一下具体优化:
1.单表查询:
select * from store where store_name='测试' and store_user_name LIKE'测试%' GROUP BY `status`,我们还是用这条sql来看,前面大致讲了一下原因,但是没有说这条sql应该怎么改,我们还是贴出执行计划

创建的索引列也贴出来,这样就不用去上面找了

这条sql能看出来使用了索引,访问类型是range,也就是说范围查询后面的列是不走索引的,按我们有什么办法让他走索引呢,我们上面把like查询换成了等值查询之后就走了索引,但是这样做并不满足我们的优化需求,为了在满足业务正确性的前提下我们可以优化索引
我们将复合索引中需要范围查询的索引去掉

然后看一下执行计划

发现访问类型为ref,从这里就能看出来我们的优化有了效果,并且我们也解决了Using temproary跟Using filesort,key_len的长度也减少了,前面也提到在同样的查询结果下key_len越小越好
2.两表联查:
select * from store s LEFT JOIN user_account ua on s.store_mobile=ua.mobile,我们将两个表的索引都删掉,执行

毫无疑问两个都是全表扫面,那么问题来了,我们加索引应该怎么加,给哪个表加,我们先试一下从第一个表开始


发现加了索引之后访问类型没有改变但是我们扫描的列变少了,这可能是MySQL查询优化器觉得全表扫描更优,然后我们将store表索引删除,在user_account表上加索引

我们能看出来我们加索引的表应该是右边的表,right on一样我们就不做演示了,我们反着加,三个表联查我们也是在后面两个表加,我们在加索引的过程一定要注意索引在什么情况下会失效,上篇文章我们提到过,解决索引失效也是我们优化sql的一部分,在满足业务的情况下当然我们也可以用小表驱动大表,还有一个特殊的请款列出来

order by遵循最左匹配原则,但是这种情况例外,将会产生Using filesort。
本篇文章提到的优化方案不一定是最优的,可能也有其他多种方案,文章可能也会有漏洞,欢迎大佬吐槽。
原文链接:https://www.cnblogs.com/HuuuWnnn/p/11160088.html
如有疑问请与原作者联系
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- MySQL replace函数怎么替换字符串语句 2020-03-09
- PHP访问MySQL查询超时怎么办 2020-03-09
- mysql登录时闪退 2020-02-27
- MySQL出现1067错误号 2020-02-27
- mysql7.x如何单独安装mysql 2020-02-27
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
