
RDMA 相关 简要摘录
2019-08-31 07:15:19来源:博客园 阅读 ()

RDMA 相关 简要摘录
RDMA (Remote Direct Memory Access) 全称为 远程直接内存访问
其出现的目的:为了解决网络传输中服务端数据处理的延迟而产生的。其将数据直接从一台计算机的内存传输到另一台计算机,无需双方操作系统的介入。这允许高吞吐、低延迟的网络通信,尤其适合在大规模并行计算机集群中使用。RDMA通过网络把资料直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理能力。它消除了外部存储器复制和上下文切换的开销,因而能解放内存带宽和CPU周期用于改进应用系统性能。
调用栈:
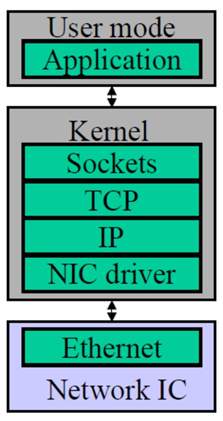
传统tcp/ip数据流动方式:
进程 buffer (用户空间)-> socket buffer(内核空间) -> 添加包头(内核空间)-> NIC buffer (网卡设备)-> 网络->接收端反向解析<--
特点:各层次分工完善,但是数据在传输过程中出现多次拷贝;产生延迟较高,也一定程度上浪费了内存和计算资源;
网络测试的五项指标:
- 可用性(availability):可使用ping 命令测试网络是否通畅;
- 响应时间(response time):ping 命令echo request/reply 一次往返所花费的时间;
- 网络利用率(network utilization):指的是网络使用时间和空闲时间的比例;
- 网络吞吐量(network throughput):在网络中两个节点之间,提供给网络应用的剩余带宽,测试网络吞吐的时候,需要在一天的不同时刻来进行测量;
- 网络带宽容量(network bandwidth capacity):与吞吐不同,网络带宽容量指的是在网络两个节点之间的最大可用带宽。该值是由网络设备本身的能力决定的。
其中两个最重要的指标是高带宽和低延迟。
通信延迟 =传输延迟 + 处理延迟;
处理延迟:发生在消息的发送端和消息的接收端; 传输延迟:发生在消息在发送方和接收方之间网络上;
通信过程中处理开销主要指:buffer 管理,不同空间的消息复制,消息发送和接收过程中系统的中断;
网络中传播的消息的种类:
Large Messages: 此类消息可以理解为:传输大块文件数据;此类模式中,网络传输延迟占整个通信中的主导地位;
Small Messages: 此类消息可以理解为:传输文件元数据信息;此类模式中,处理延迟在整个通信过程中的主导地位;
传统TCP/IP存在的问题:
传统的TCP/IP的问题,主要是IO瓶颈,在高速网络条件下与网络I/O相关的主机处理的高开销限制了可以在机器之间发送的带宽。由上面的数据流动方式,我们可以看到,这里的高开销主要是数据移动和复制操作;主要是传统的TCP/IP网络通信是通过内核发送消息。Messaging passing through kernel这种方式会导致很低的性能和很低的灵活性。性能低下的原因主要是由于网络通信通过内核传递,这种通信方式存在的很高的数据移动和数据复制的开销。并且现如今内存带宽性相较如CPU带宽和网络带宽有着很大的差异。很低的灵活性的原因主要是所有网络通信协议通过内核传递,这种方式很难去支持新的网络协议和新的消息通信协议和发送、接收接口。
高性能网络通信相关研究:
- TCP Offloading Engine(TOE):将加解包的工作下移到网卡上,需要特定网卡支持;
- User-Net Networking(U-Net):将整个协议栈移动到用户空间中,从数据通信路径中,彻底删除内核,带来高性能和高灵活性的提升;
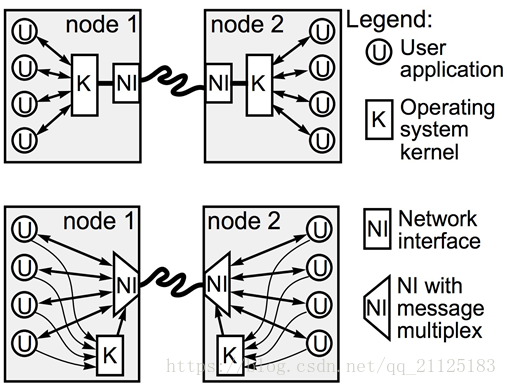
内核接口只涉及到连接步骤,在传输过程中,减少了数据在用户空间和内核空间的复制;
- Virtual interface Architecture(VIA):VIA 通过为每个应用进程提供受保护的,对网络硬件进行存取的接口-Virtual Interface,从而消除了传统模式下的系统处理开销;
- Remote Direct Memroy Access(RDMA)

RDMA 通过网络,把数据资料,直接传入计算机的存储区,消除了存储器件的赋值和上下文切换开销;其有低延迟,低CPU负载和高带宽三种特性;
RDMA 操作:
Memory verbs: RDMA read、write 和 atomic 操作。这些操作指定远程地址进行操作并绕过接收者的CPU; (单边操作,应用无感知)
Messaging verbs: 包括RDMA send、receive 操作。动作涉及到响应者的CPU,发送的数据被写入到由响应者CPU先前发布的接收所指定的地址;(双边操作,需应用感知)
send/receive 多用于连接控制类报文,而数据报文多是通过READ/WRITE 来完成的。双边操作与传统网络的底层Buffer Pool 类似,双方参与的过程并无差别。主要区别在于RDMA的零拷贝和Kernel Bypass。对于RDMA 这是一种负载的消息传输模式,多用于传输短的控制消息;

RC 表示可靠连接;UC 表示不可靠连接;UD 表示不可靠的数据报,不支持memory verbs;
RDMA 实现:

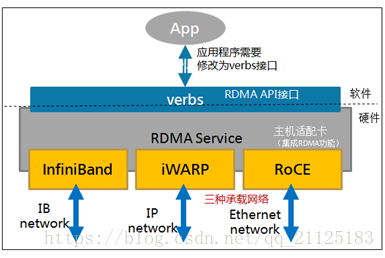
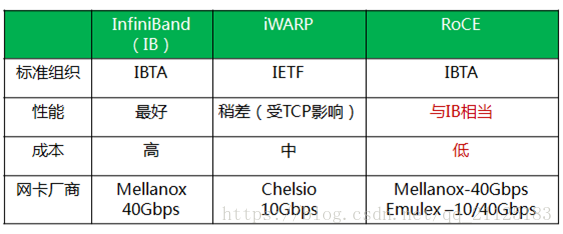
RDMA 目前有三种不同实现:InfiniBand,iWarp(internet Wide Area RDMA Protocol),RoCE(RDMA over Converged Ethernet);
Infiniband是一种专为RDMA设计的网络,从硬件级别保证可靠传输 , 而RoCE 和 iWARP都是基于以太网的RDMA技术,支持相应的verbs接口。从图中不难发现,RoCE协议存在RoCEv1和RoCEv2两个版本,主要区别RoCEv1是基于以太网链路层实现的RDMA协议(交换机需要支持PFC等流控技术,在物理层保证可靠传输),而RoCEv2是以太网TCP/IP协议中UDP层实现。从性能上,很明显Infiniband网络最好,但网卡和交换机是价格也很高,然而RoCEv2和iWARP仅需使用特殊的网卡就可以了,价格也相对便宜很多。
Infiniband:支持RDMA的新一代网络协议。 由于这是一种新的网络技术,因此需要支持该技术的NIC和交换机。
RoCE:允许在以太网上执行RDMA的网络协议。 其较低的网络标头是以太网标头,其较高的网络标头(包括数据)是InfiniBand标头。 这支持在标准以太网基础设施(交换机)上使用RDMA。 只有网卡应该是特殊的,支持RoCE。
iWARP:一个允许在TCP上执行RDMA的网络协议。 IB和RoCE中存在的功能在iWARP中不受支持。 这支持在标准以太网基础设施(交换机)上使用RDMA。 只有网卡应该是特殊的,并且支持iWARP(如果使用CPU卸载),否则所有iWARP堆栈都可以在SW中实现,并且丧失了大部分RDMA性能优势。
RDMA 结构图:

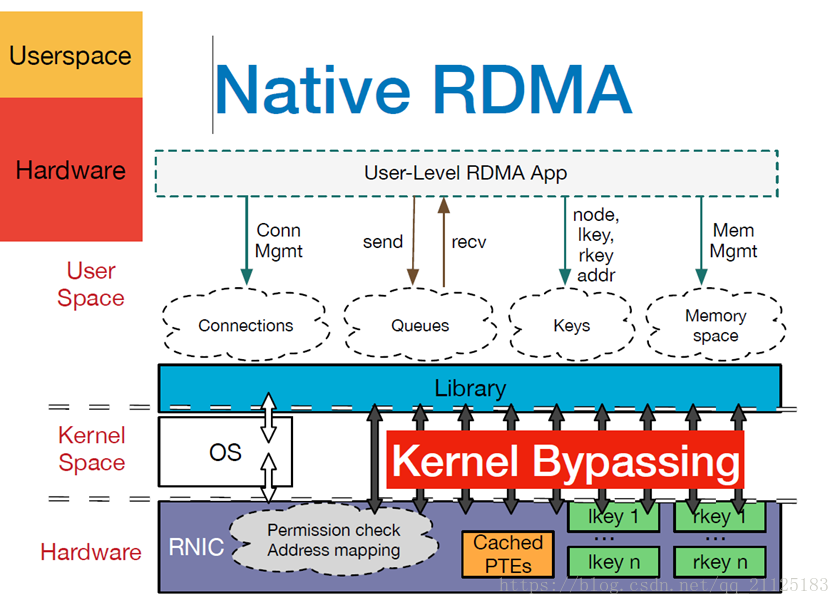
RDMA工作过程:
- 应用执行RDMA读写请求的时候,不需要内核内存参与,RDMA 请求直接从用户空间的应用发送到本地NIC(网卡);
- NIC 读取缓冲区内容,并通过网络传送到远程NIC;
- 在网络上传输的RDMA信息,包含目标虚拟地址,内存钥匙和数据本身;请求既可以完全在用户空间中处理(使用主动轮询机制),又可以在应用一直睡眠到请求完成时的情况下,通过系统中断处理。RDMA操作使得应用可以从一个远程应用的内存中(远程应用的虚拟内存)读取数据或者向这个内存中写数据;
- 目标NIC确认内存钥匙(key),直接将数据写入应用缓存中。用于操作的远程虚拟内存地址包含在RDMA信息中;
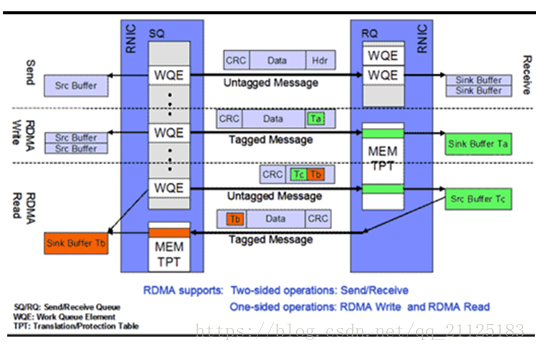
RMDA 中专有名词和对应缩写:
Channel-IO:RDMA 在本端应用和远端应用间创建的一个消息通道;
Queue Pairs(QP):每个消息通道两端是两对QP;
Send Queue(SQ): 发送队列,队列中的内容为WQE;
Receive Queue(RQ):接收队列,队列中的内容为WQE;
Work Queue Element(WQE):工作队列元素,WQE指向一块用于存储数据的Buffer;
Work Queue(WQ): 工作队列,在发送过程中 WQ = SQ; 在接收过程中WQ = WQ;
Complete Queue(CQ): 完成队列,CQ用于告诉用户WQ上的消息已经被处理完成;
Work Request(WR):传输请求,WR描述了应用希望传输到Channel对端的消息内容,在WQ中转化为 WQE 格式的信息;
参考链接:
https://blog.csdn.net/qq_21125183/article/details/80563463
保持更新,资源来源于对网上资料总结,如果对您有帮助,请关注 cnblogs.com/xuyaowen .
原文链接:https://www.cnblogs.com/xuyaowen/p/rdma-intro.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- ubuntu之命令相关问题 2020-06-06
- Linux下几个与磁盘空间和文件尺寸相关的命令 2020-05-20
- 运维相关 2020-05-16
- 【Linux面试题2】目录结构及相关命令 2020-05-15
- Linux 用户和权限 2020-05-15
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
