
Linux 命令
2020-03-04 16:06:16来源:博客园 阅读 ()

Linux 命令
centos7中防火墙相关命令
查看状态:
getenforce # 查看内核防火墙状态(disabled标识关闭) systemctl status firewalld # 查看防火墙状态
firewalld 的基本命令:
启动: systemctl start firewalld 查看状态: systemctl status firewalld 停止: systemctl disable firewalld 禁用: systemctl stop firewalld 在开机时启用一个服务:systemctl enable firewalld.service 在开机时禁用一个服务:systemctl disable firewalld.service 查看服务是否开机启动:systemctl is-enabled firewalld.service 查看已启动的服务列表:systemctl list-unit-files|grep enabled 查看启动失败的服务列表:systemctl --failed
CentOS7关闭SELinux:
临时关闭:
##设置SELinux 成为permissive模式 ##setenforce 1 设置SELinux 成为enforcing模式 setenforce 0
永久关闭:
vi /etc/selinux/config # 将SELINUX=enforcing改为SELINUX=disabled # 设置后需要重启才能生效
Linux 常用基础命令
scp传文件:
scp -r /root/lk root@43.224.34.73:/home/lk/cpfile # 将本机的 /root/lk 文件夹传到43.224.34.73机器上 scp -r root@43.224.34.73:/home/lk /root # 将43.224.34.73机器上/home/lk 文件夹传到本地的/root文件件
file命令查看文件是windows格式还是linux格式:
'''在linux中确定文件是否是windows''' #1、windows格式文件显示:标记为 CRLF [root@redis aaa]# file testwin.py testwin.py: Python script, UTF-8 Unicode text executable, with CRLF line terminators #2、这个是linux格式文件 [root@op-sandbox app01]# file urls.py urls.py: Python script, ASCII text executable #3、还可以用cat -v 查看,windows格式文件有 ^M 标记为 [root@redis aaa]# cat -V testwin.py
find . -name "*.py" | xargs sed -i 's/\r$//g' # 批量将当前文件夹下所有.py文件转换成unix格式 find ./ -type f | xargs sed -i 's/\r$//g' # 批量将当前文件夹下所有文件装换成unix格式 find ./ -name *.pyc | xargs rm -rf {} # 批量删除当前文件夹下所有.pyc文件
查找大文件文件:
du -sh ./*|grep G # 查看当前目录下个文件大于1G的文件夹
查找日志文件中 5xx数量,并进行排序:
tail -n 1000000 2019042410.access.log | grep "status\":\"5" | jq .request_uri | sort | uniq -c | sort -n
ps查找进程:
ps:
ps -ef # 显示所有进程信息,连同命令行 ps -aux # 显示所有包含其他使用者的行程
pstree -apnh # 显示进程间的关系
说明:Linux pstree命令将所有行程以树状图显示,树状图将会以 pid (如果有指定) 如果有指定使用者 id,则树状图会只显示该使用者所拥有的行程。
pstree -apnh #显示进程间的关系 pstree -u # 显示用户名称
pgrep:
说明:pgrep 是通过程序的名字来查询进程的工具,一般是用来判断程序是否正在运行
pgrep -ln python
top # 动态查看进程的情况
kill 和 pkill杀死进程:
kill -9 2233 # 杀死进程2233 pkill zabbix # 杀死zabbix进程
netstat:
# 说明: 查看本机开启端口号 netstat -anptu|grep 8000 # 查看8000端口运行的服务
find查找命令
find . -name "*.txt" # 在当前目录下查找以txt结尾的文件 find . -name "[a-z]*" # 在当前目录下查找所有以字母开头的文件 find /etc -name "host*" # 在/etc目录下查找以host开头的文件 find . -perm 755 -type f # 在当前目录下查找权限为755的文件 find /var -mtime -5 # 在/var 下找更改时间在5天以内的文件 find /var -mtime +3 # 在/var下查找更改时间在三天前的文件 find /etc -type d # 在/etc下查找文件类型为d(目录) find . -size +1000000c # 在当前目录下查找文件大于1M的文件(1M是1000000个字节) # xargs: 将find查找到的内容作为后面命令的参数 # 1、找出当前目录下权限为755的文件并把权限改为 777 find . -perm 755 | xargs chmod 777 # 2、找出文件并查看详细信息 find . -type f |xargs ls -l
linux中正则表达式与grep使用
常用正则:
^linux # 以linux开头的行 $php # 以php结尾的行 . # 匹配任意单字符 .+ # 匹配任意多个字符 .* # 匹配0个或多个字符(可有可无) [0-9a-z] # 匹配中括号内任意一个字符 (linux)+ # 出现多次Linux单词 (web){2} #web出现两次以上 \ # 屏蔽转义
grep基本使用
grep -c "file" a.txt # 统计a.txt文件中有多少行包含"file"字符串 grep -n "file" a.txt # 在a.txt文件中有多少行匹配字符串"file",同时显示行和行号 grep -i "file" a.txt # 在a.txt文件中匹配字符串"file"不区分大小写 grep -v "file" a.txt # 在文件中过滤掉file所在行(-v 取反)
grep与正则结合
# 在file文件中找到以 linux 开头的行 grep -E '^linux' file
# 在文件中查找以 linux 结尾的行 grep -E 'linux$' file # 在file文件中有 linux 的行 grep -e '.*linux.*' file # 找出file文件中包含数字的行 [root@localhost aaa] # grep -En '[0-9]+' file 4:jfsdjdddd3333232dfsj linux # 前面作色数字4表示第四行 # 找出包含地址格式的行 grep -En '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]\.[0-9]' file # 查找时间在 2016-11-11 10:22:50 到 2016-11-11 10:22:59 [root@localhost aaa]# grep -e "2016-11-11 10:22:5[0-9]" file 查找时间在 2016-11-11 10:22:00 到 2016-11-11 10:22:59
# 杀死所有的text.py进程 ps -ef | grep -E "(manage.py)(.*):8000" | grep -v grep| awk '{print $2}' | xargs kill -9 ps -ef | grep -E "test.py" | grep -v grep| awk '{print $2}' | xargs kill -9
awk
awk是行处理器:- 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
- 依次对每一行进行处理,然后输出
awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file
[-F|-f|-v] # 大参数,-F指定分隔符,-f调用脚本,-v定义变量 var=value
' ' # 引用代码块
BEGIN # 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// # 匹配代码块,可以是字符串或正则表达式
{} # 命令代码块,包含一条或多条命令
; # 多条命令使用分号分隔
END # 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
技术要点:
// # 匹配代码块,可以是字符串或正则表达式 {} # 命令代码块,包含一条或多条命令 $0 # 表示整个当前行 $1 # 每行第一个字段 NF # 字段数量变量 NR # 每行的记录号,多文件记录递增 /[0-9][0-9]+/ # 两个或两个以上数字 /[0-9][0-9]*/ # 一个或一个以上数字 -F'[:#/]' # 定义三个分隔符 FNR # 与NR类似,不过多文件记录不递增,每个文件都从1开始 \t # 制表符 \n # 换行符 FS # BEGIN时定义分隔符 RS # 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入) ~ # 匹配,与==相比不是精确比较 !~ # 不匹配,不精确比较 == # 等于,必须全部相等,精确比较 != # 不等于,精确比较 && # 逻辑与 || # 逻辑或 + # 匹配时表示1个或1个以上print & $0:
print 是awk打印指定内容的主要命令 awk '{print}' /etc/passwd == awk '{print $0}' /etc/passwd awk '{print " "}' /etc/passwd # 不输出passwd的内容,而是输出相同个数的空行,进一步解释了awk是一行一行处理文本 awk '{print "a"}' /etc/passwd # 输出相同个数的a行,一行只有一个a字母 awk -F":" '{print $1}' /etc/passwd awk -F: '{print $1; print $2}' /etc/passwd # 将每一行的前二个字段,分行输出,进一步理解一行一行处理文本 awk -F: '{print $1,$3,$6}' OFS="\t" /etc/passwd # 输出字段1,3,6,以制表符作为分隔符
awk基础使用:
w|awk 'NR==1{print $6}' # 打印第一行,第六列的数据 cat /etc/passwd|awk -F":" '{print $1}' # -F指定以":"分隔,打印第一列数据 df -hl|awk '{print $NF}' # 打印最后一列数据 awk -F: 'NR==5{print}' /etc/passwd # 显示第5行 awk -F: 'NR==5 || NR==6{print}' /etc/passwd # 显示第5行和第6行 route -n|awk 'NR!=1{print}' # 不显示第一行
awk匹配代码块:
// # 纯字符匹配 !// # 纯字符不匹配 ~// # 字段值匹配 !~// # 字段值不匹配 ~/a1|a2/ # 字段值匹配a1或a2
awk '/mysql/' /etc/passwd # 匹配所有 包含 "mysql" 关键字的行 awk '!/mysql/' /etc/passwd # 匹配所有 不包含 "mysql"关键字的行 awk '/mysql|mail/{print}' /etc/passwd # 匹配包含mysql 或者 mail的行 awk -F: '/mail/,/mysql/' /etc/passwd # 匹配mail开头 到 mysql 结尾的所有行-f指定脚本文件:
awk -f script.awk file BEGIN{ FS=":" } {print $1} # 效果与awk -F":" '{print $1}'相同,只是分隔符使用FS在代码自身中指定-F指定分隔符:
awk 'BEGIN{X=0} /^$/{ X+=1 } END{print "I find",X,"blank lines."}' test I find 4 blank lines. ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is",sum}' # 计算文件大小 total size is 17487
$1 指指定分隔符后,第一个字段,$3第三个字段, \t是制表符 一个或多个连续的空格或制表符看做一个定界符,即多个空格看做一个空格 awk -F":" '{print $1}' /etc/passwd awk -F":" '{print $1 $3}' /etc/passwd # $1与$3相连输出,不分隔 awk -F":" '{print $1,$3}' /etc/passwd # 多了一个逗号,$1与$3使用空格分隔 awk -F":" '{print $1 " " $3}' /etc/passwd # $1与$3之间手动添加空格分隔 awk -F":" '{print "Username:" $1 "\t\t Uid:" $3 }' /etc/passwd # 自定义输出 awk -F: '{print NF}' /etc/passwd # 显示每行有多少字段 awk -F: '{print $NF}' /etc/passwd # 将每行第NF个字段的值打印出来 awk -F: 'NF==4 {print }' /etc/passwd # 显示只有4个字段的行 awk -F: 'NF>2{print $0}' /etc/passwd # 显示每行字段数量大于2的行 awk '{print NR,$0}' /etc/passwd # 输出每行的行号 awk -F: '{print NR,NF,$NF,"\t",$0}' /etc/passwd # 依次打印行号,字段数,最后字段值,制表符,每行内容 awk -F: 'NR==5{print}' /etc/passwd # 显示第5行 awk -F: 'NR==5 || NR==6{print}' /etc/passwd # 显示第5行和第6行 route -n|awk 'NR!=1{print}' # 不显示第一行//匹配代码块:
//纯字符匹配 !//纯字符不匹配 ~//字段值匹配 !~//字段值不匹配 ~/a1|a2/字段值匹配a1或a2 awk '/mysql/' /etc/passwd awk '/mysql/{print }' /etc/passwd awk '/mysql/{print $0}' /etc/passwd # 三条指令结果一样 awk '!/mysql/{print $0}' /etc/passwd # 输出不匹配mysql的行 awk '/mysql|mail/{print}' /etc/passwd awk '!/mysql|mail/{print}' /etc/passwd awk -F: '/mail/,/mysql/{print}' /etc/passwd # 区间匹配 awk '/[2][7][7]*/{print $0}' /etc/passwd # 匹配包含27为数字开头的行,如27,277,2777... awk -F: '$1~/mail/{print $1}' /etc/passwd # $1匹配指定内容才显示 awk -F: '{if($1~/mail/) print $1}' /etc/passwd # 与上面相同 awk -F: '$1!~/mail/{print $1}' /etc/passwd # 不匹配 awk -F: '$1!~/mail|mysql/{print $1}' /etc/passwd
IF语句:
# 下面三个语句实现一个效果:当字段中匹配 “mail” 打印当前行 awk -F: '{if($1~/mail/) print $0}' /etc/passwd # 简写 awk -F: '{if($1~/mail/) {print $0}}' /etc/passwd # 全写 awk -F: '{if($1~/mail/) {print $0} else {print $2}}' /etc/passwd # if...else... awk -F: '{if($3>100) print "large"; else print "small"}' /etc/passwd # $3大于100输出large否则输出small awk -F: '{if($3<100) next; else print}' /etc/passwd # 小于100跳过,否则显示
条件表达式:== != > >= :
awk -F":" '{if($1=="mysql") print $0}' /etc/passwd # 匹配包含mysql的行 awk -F":" '$1!="mysql"{print $0}' /etc/passwd # 匹配不包含mysql的行 awk -F":" '$3<=1{print $0}' /etc/passwd # 匹配$3的值小于等于1的行 awk -F: '$3 > 999 || $3 < 1' /etc/passwd # 匹配$3 大于999 小于 1 的行 awk -F: '$3+$4 > 2000' /etc/passwd # 匹配 $3 + $4 的值大于2000的行 awk '/MemFree/{print int($2/1024)}' /proc/meminfo # 打印取整之后的值逻辑运算符:
&& || awk -F: '$1~/mail/ && $3>8 {print }' /etc/passwd # 逻辑与,$1匹配mail,并且$3>8 awk -F: '{if($1~/mail/ && $3>8) print }' /etc/passwd awk -F: '$1~/mail/ || $3>1000 {print }' /etc/passwd # 逻辑或 awk -F: '{if($1~/mail/ || $3>1000) print }' /etc/passwd数值运算:
awk -F: '$3 > 100' /etc/passwd awk -F: '$3 > 100 || $3 < 5' /etc/passwd awk -F: '$3+$4 > 200' /etc/passwd awk -F: '/mysql|mail/{print $3+10}' /etc/passwd # 第三个字段加10打印 awk -F: '/mysql/{print $3-$4}' /etc/passwd # 减法 awk -F: '/mysql/{print $3*$4}' /etc/passwd # 求乘积 awk '/MemFree/{print $2/1024}' /proc/meminfo # 除法 awk '/MemFree/{print int($2/1024)}' /proc/meminfo # 取整输出分隔符OFS:
awk '$6 ~ /FIN/ || NR==1 {print NR,$4,$5,$6}' OFS="\t" netstat.txt awk '$6 ~ /WAIT/ || NR==1 {print NR,$4,$5,$6}' OFS="\t" netstat.txt # 输出字段6匹配WAIT的行,其中输出每行行号,字段4,5,6,并使用制表符分割字段输出处理结果到文件:
route -n|awk 'NR!=1{print > "./fs"}' # 在命令代码块中直接输出 route -n|awk 'NR!=1{print}' > ./fs # 使用重定向进行输出格式化输出:
netstat -anp|awk '{printf "%-8s %-8s %-10s\n",$1,$2,$3}' printf表示格式输出 %格式化输出分隔符 -8长度为8个字符 s表示字符串类型 打印每行前三个字段,指定第一个字段输出字符串类型(长度为8),第二个字段输出字符串类型(长度为8), 第三个字段输出字符串类型(长度为10) netstat -anp|awk '$6=="LISTEN" || NR==1 {printf "%-10s %-10s %-10s \n",$1,$2,$3}' netstat -anp|awk '$6=="LISTEN" || NR==1 {printf "%-3s %-10s %-10s %-10s \n",NR,$1,$2,$3}'IF语句:
awk -F: '{if($3>100) print "large"; else print "small"}' /etc/passwd small small small large small small awk -F: 'BEGIN{A=0;B=0} {if($3>100) {A++; print "large"} else {B++; print "small"}} END{print A,"\t",B}' /etc/passwd # ID大于100,A加1,否则B加1 awk -F: '{if($3<100) next; else print}' /etc/passwd # 小于100跳过,否则显示 awk -F: 'BEGIN{i=1} {if(i awk -F: 'BEGIN{i=1} {if(i 另一种形式 awk -F: '{print ($3>100 ? "yes":"no")}' /etc/passwd awk -F: '{print ($3>100 ? $3":\tyes":$3":\tno")}' /etc/passwdwhile语句:
awk -F: 'BEGIN{i=1} {while(i 7 root 1 7 x 2 7 0 3 7 0 4 7 root 5 7 /root 6<nf) print="" nf,$i,i++}'="" etc="" passwd ="" <="" div="" style="overflow-wrap: break-word;"> 数组:
netstat -anp|awk 'NR!=1{a[$6]++} END{for (i in a) print i,"\t",a[i]}' netstat -anp|awk 'NR!=1{a[$6]++} END{for (i in a) printf "%-20s %-10s %-5s \n", i,"\t",a[i]}' 9523 1 9929 1 LISTEN 6 7903 1 3038/cupsd 1 7913 1 10837 1 9833 1应用1:
awk -F: '{print NF}' helloworld.sh # 输出文件每行有多少字段 awk -F: '{print $1,$2,$3,$4,$5}' helloworld.sh # 输出前5个字段 awk -F: '{print $1,$2,$3,$4,$5}' OFS='\t' helloworld.sh # 输出前5个字段并使用制表符分隔输出 awk -F: '{print NR,$1,$2,$3,$4,$5}' OFS='\t' helloworld.sh # 制表符分隔输出前5个字段,并打印行号应用2:
awk -F'[:#]' '{print NF}' helloworld.sh # 指定多个分隔符: #,输出每行多少字段 awk -F'[:#]' '{print $1,$2,$3,$4,$5,$6,$7}' OFS='\t' helloworld.sh # 制表符分隔输出多字段应用3:
awk -F'[:#/]' '{print NF}' helloworld.sh # 指定三个分隔符,并输出每行字段数 awk -F'[:#/]' '{print $1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12}' helloworld.sh # 制表符分隔输出多字段应用4:
# 计算/home目录下,普通文件的大小,使用KB作为单位 ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",sum/1024,"KB"}' ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",int(sum/1024),"KB"}' # int是取整的意思应用5:
# 统计netstat -anp 状态为LISTEN和CONNECT的连接数量分别是多少 netstat -anp|awk '$6~/LISTEN|CONNECTED/{sum[$6]++} END{for (i in sum) printf "%-10s %-6s %-3s \n", i," ",sum[i]}'应用6:
# 统计/home目录下不同用户的普通文件的总数是多少? ls -l|awk 'NR!=1 && !/^d/{sum[$3]++} END{for (i in sum) printf "%-6s %-5s %-3s \n",i," ",sum[i]}' mysql 199 root 374 # 统计/home目录下不同用户的普通文件的大小总size是多少? ls -l|awk 'NR!=1 && !/^d/{sum[$3]+=$5} END{for (i in sum) printf "%-6s %-5s %-3s %-2s \n",i," ",sum[i]/1024/1024,"MB"}'应用7:
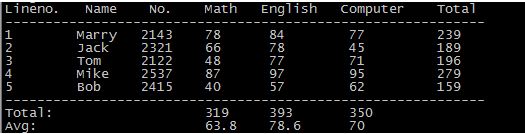
# 输出成绩表 awk 'BEGIN{math=0;eng=0;com=0;printf "Lineno. Name No. Math English Computer Total\n";printf "------------------------------------------------------------\n"}{math+=$3; eng+=$4; com+=$5;printf "%-8s %-7s %-7s %-7s %-9s %-10s %-7s \n",NR,$1,$2,$3,$4,$5,$3+$4+$5} END{printf "------------------------------------------------------------\n";printf "%-24s %-7s %-9s %-20s \n","Total:",math,eng,com;printf "%-24s %-7s %-9s %-20s \n","Avg:",math/NR,eng/NR,com/NR}' test0 [root@localhost home]# cat test0 Marry 2143 78 84 77 Jack 2321 66 78 45 Tom 2122 48 77 71 Mike 2537 87 97 95 Bob 2415 40 57 62
原文链接:https://www.cnblogs.com/yangmaosen/p/12416469.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- Linux系统如何设置开机自动运行脚本? 2020-06-11
- Linux指令和shell脚本 2020-06-11
- 适合开发者的最佳Linux发行版 2020-06-11
- awk命令详解 2020-06-10
- RAID 1 软件实现(Linux 系统) 2020-06-10
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
