
由java程序引起的一次系统崩溃
2020-05-27 16:04:38来源:博客园 阅读 ()

由java程序引起的一次系统崩溃
问题来源
2020年5月3日星期天。晚上7点39分,正是结账的高峰期,然而就是在这个时候系统崩溃了。牵扯到钱的事没一件事小事,可以定性此为重大事故。
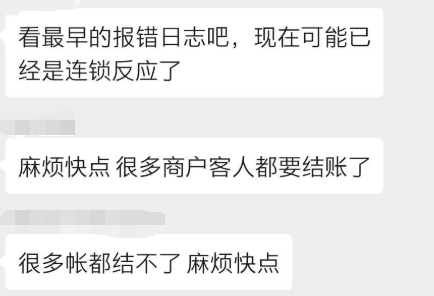
造成的后果:

有人必须要背锅了,先恢复再找问题源头,再找谁的问题(这种锅绝大多数是开发的问题)。
问题处理
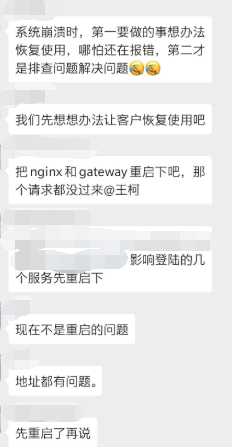
常见思路:回滚、重启大法!!! 先恢复再查原因
f12 访问看问题到底在哪里?

502服务端错误,可以肯定与代码健壮性有关。
重启回滚能解决百分之80的问题,但这里的路径多了一个/,路由是不是有问题,看日志,或看相关服务的连接。nginx就做了一个反向代理,我觉得还是跟请求的代码有关,让他们抓包看看流量到哪了,先看看解析有没有问题,然后直接用ip能不能到ng,解析没问题的话,确定一下域名访问能到ng不,后端直接在ng上用curl测试下正常不,代码问题直接回滚,不二话,域名问题看看是不是被劫持了。

GC了,....网关,开发自己写的...
其实最开始出现问题,后面会出现有的可以访问,有的不行,我们的gatway是设置弹性伸缩的,刚才确实伸缩了,但是有些流量还是转到了旧的pod上,因为GC了,所以不能访问gatway。
OOM是不会影响端口 端口只有是否被开放 或者服务是否正确启动才会有端口的问题,OOM是内存的问题和你服务端口无关,Pod中查询OOM的问题:java应用出现内存溢出老正常了。最好加上监控(监控Pod的IO之类的),重启也行,加入注册中心,服务不可用 剔除。
善后工作
- 监控日志,报警出来
- 做探针?
探针没用,因为服务端口都在,pod状态也是running。所以就是要api,检测可用性的api。端口不能代表可用性,应该让开发在网关加一个健康检查端口。通过curl 健康检查端口判断业务是否正常 - prestop
钩子,有问题,就杀掉,然后剔除注册中心,滚动更新的时候加上prestop,然后通过curl 注册中心,将这个pod强制下线

具体参数得问开发
越是重大问题你处理了,越是体现价值,处理好了,应该的,处理不好,背锅。真现实。
原文链接:https://www.cnblogs.com/zisefeizhu/p/12973635.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

- MPI 本地局域网运行多机配置,同时运行多个程序; 2020-06-02
- 饿了么总监分享:我是如何完成从程序员到管理层的蜕变? 2020-05-14
- 自己动手在Linux系统实现一个everything程序 2020-05-12
- Javaweb项目配置到阿里云服务器 2020-05-06
- 针对Linux上Java程式运行脚本的Log信息记录操作人员记录以及 2020-04-27
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
